 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Misalignment of Multimodal Large Language Models via Influence Function
Nov 18, 2024Multi-modal Large Language models (MLLMs) are always trained on data from diverse and unreliable sources, which may contain misaligned or mislabeled text-image pairs. This frequently causes robustness issues and hallucinations, leading to performance degradation. Data valuation is an efficient way to detect and trace these misalignments. Nevertheless, existing methods are computationally expensive for MLLMs. While computationally efficient, the classical influence functions are inadequate for contrastive learning models because they were originally designed for pointwise loss. Additionally, contrastive learning involves minimizing the distance between the modalities of positive samples and maximizing the distance between the modalities of negative samples. This requires us to evaluate the influence of samples from both perspectives. To tackle these challenges, we introduce the Extended Influence Function for Contrastive Loss (ECIF), an influence function crafted for contrastive loss. ECIF considers both positive and negative samples and provides a closed-form approximation of contrastive learning models, eliminating the need for retraining. Building upon ECIF, we develop a series of algorithms for data evaluation in MLLM, misalignment detection, and misprediction trace-back tasks. Experimental results demonstrate our ECIF advances the transparency and interpretability of MLLMs by offering a more accurate assessment of data impact and model alignment compared to traditional baseline methods.
Effective prevention of semantic drift as angular distance in memory-less continual deep neural networks
Dec 16, 2021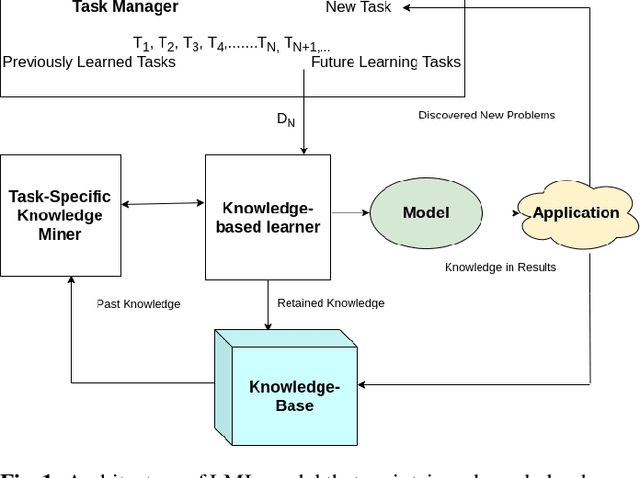
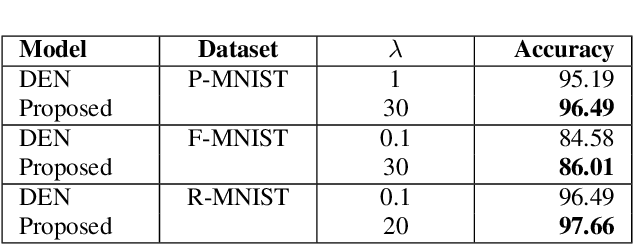

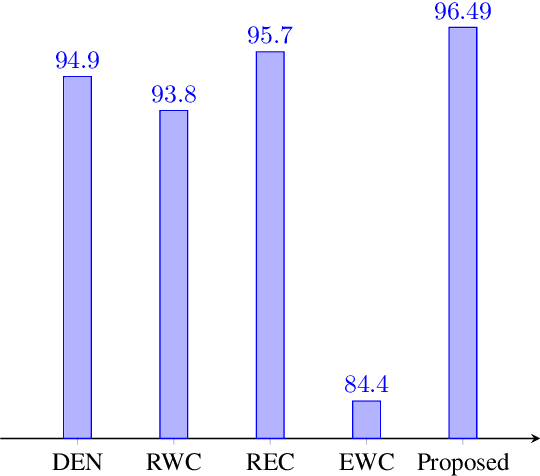
Lifelong machine learning or continual learning models attempt to learn incrementally by accumulating knowledge across a sequence of tasks. Therefore, these models learn better and faster. They are used in various intelligent systems that have to interact with humans or any dynamic environment e.g., chatbots and self-driving cars. Memory-less approach is more often used with deep neural networks that accommodates incoming information from tasks within its architecture. It allows them to perform well on all the seen tasks. These models suffer from semantic drift or the plasticity-stability dilemma. The existing models use Minkowski distance measures to decide which nodes to freeze, update or duplicate. These distance metrics do not provide better separation of nodes as they are susceptible to high dimensional sparse vectors. In our proposed approach, we use angular distance to evaluate the semantic drift in individual nodes that provide better separation of nodes and thus better balancing between stability and plasticity. The proposed approach outperforms state-of-the art models by maintaining higher accuracy on standard datasets.