 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Self-Improving Error Diagnosis in Multi-Agent Systems
Apr 19, 2026Large Language Model (LLM)-based Multi-Agent Systems (MAS) enable complex problem-solving but introduce significant debugging challenges, characterized by long interaction traces, inter-agent dependencies, and delayed error manifestation. Existing diagnostic approaches often rely on expensive expert annotation or ''LLM-as-a-judge'' paradigms, which struggle to pinpoint decisive error steps within extended contexts. In this paper, we introduce ErrorProbe, a self-improving framework for semantic failure attribution that identifies responsible agents and the originating error step. The framework operates via a three-stage pipeline: (1) operationalizing the MAS failure taxonomy to detect local anomalies, (2) performing symptom-driven backward tracing to prune irrelevant context, and (3) employing a specialized multi-agent team (Strategist, Investigator, Arbiter) to validate error hypotheses through tool-grounded execution. Crucially, ErrorProbe maintains a verified episodic memory that updates only when error patterns are confirmed by executable evidence, without the need for annotation. Experiments across the TracerTraj and Who&When benchmarks demonstrate that ErrorProbe significantly outperforms baselines, particularly in step-level localization, while the verified memory enables robust cross-domain transfer without retraining.
Generalizing GNNs with Tokenized Mixture of Experts
Feb 09, 2026Deployed graph neural networks (GNNs) are frozen at deployment yet must fit clean data, generalize under distribution shifts, and remain stable to perturbations. We show that static inference induces a fundamental tradeoff: improving stability requires reducing reliance on shift-sensitive features, leaving an irreducible worst-case generalization floor. Instance-conditional routing can break this ceiling, but is fragile because shifts can mislead routing and perturbations can make routing fluctuate. We capture these effects via two decompositions separating coverage vs selection, and base sensitivity vs fluctuation amplification. Based on these insights, we propose STEM-GNN, a pretrain-then-finetune framework with a mixture-of-experts encoder for diverse computation paths, a vector-quantized token interface to stabilize encoder-to-head signals, and a Lipschitz-regularized head to bound output amplification. Across nine node, link, and graph benchmarks, STEM-GNN achieves a stronger three-way balance, improving robustness to degree/homophily shifts and to feature/edge corruptions while remaining competitive on clean graphs.
Graph is a Substrate Across Data Modalities
Jan 29, 2026Graphs provide a natural representation of relational structure that arises across diverse domains. Despite this ubiquity, graph structure is typically learned in a modality- and task-isolated manner, where graph representations are constructed within individual task contexts and discarded thereafter. As a result, structural regularities across modalities and tasks are repeatedly reconstructed rather than accumulated at the level of intermediate graph representations. This motivates a representation-learning question: how should graph structure be organized so that it can persist and accumulate across heterogeneous modalities and tasks? We adopt a representation-centric perspective in which graph structure is treated as a structural substrate that persists across learning contexts. To instantiate this perspective, we propose G-Substrate, a graph substrate framework that organizes learning around shared graph structures. G-Substrate comprises two complementary mechanisms: a unified structural schema that ensures compatibility among graph representations across heterogeneous modalities and tasks, and an interleaved role-based training strategy that exposes the same graph structure to multiple functional roles during learning. Experiments across multiple domains, modalities, and tasks show that G-Substrate outperforms task-isolated and naive multi-task learning methods.
Semantic Refinement with LLMs for Graph Representations
Dec 24, 2025Graph-structured data exhibit substantial heterogeneity in where their predictive signals originate: in some domains, node-level semantics dominate, while in others, structural patterns play a central role. This structure-semantics heterogeneity implies that no graph learning model with a fixed inductive bias can generalize optimally across diverse graph domains. However, most existing methods address this challenge from the model side by incrementally injecting new inductive biases, which remains fundamentally limited given the open-ended diversity of real-world graphs. In this work, we take a data-centric perspective and treat node semantics as a task-adaptive variable. We propose a Data-Adaptive Semantic Refinement framework DAS for graph representation learning, which couples a fixed graph neural network (GNN) and a large language model (LLM) in a closed feedback loop. The GNN provides implicit supervisory signals to guide the semantic refinement of LLM, and the refined semantics are fed back to update the same graph learner. We evaluate our approach on both text-rich and text-free graphs. Results show consistent improvements on structure-dominated graphs while remaining competitive on semantics-rich graphs, demonstrating the effectiveness of data-centric semantic adaptation under structure-semantics heterogeneity.
Mapping Faithful Reasoning in Language Models
Oct 25, 2025Chain-of-thought (CoT) traces promise transparency for reasoning language models, but prior work shows they are not always faithful reflections of internal computation. This raises challenges for oversight: practitioners may misinterpret decorative reasoning as genuine. We introduce Concept Walk, a general framework for tracing how a model's internal stance evolves with respect to a concept direction during reasoning. Unlike surface text, Concept Walk operates in activation space, projecting each reasoning step onto the concept direction learned from contrastive data. This allows us to observe whether reasoning traces shape outcomes or are discarded. As a case study, we apply Concept Walk to the domain of Safety using Qwen 3-4B. We find that in 'easy' cases, perturbed CoTs are quickly ignored, indicating decorative reasoning, whereas in 'hard' cases, perturbations induce sustained shifts in internal activations, consistent with faithful reasoning. The contribution is methodological: Concept Walk provides a lens to re-examine faithfulness through concept-specific internal dynamics, helping identify when reasoning traces can be trusted and when they risk misleading practitioners.
NeuralDB: Scaling Knowledge Editing in LLMs to 100,000 Facts with Neural KV Database
Jul 24, 2025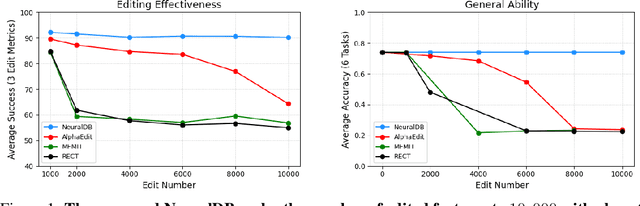
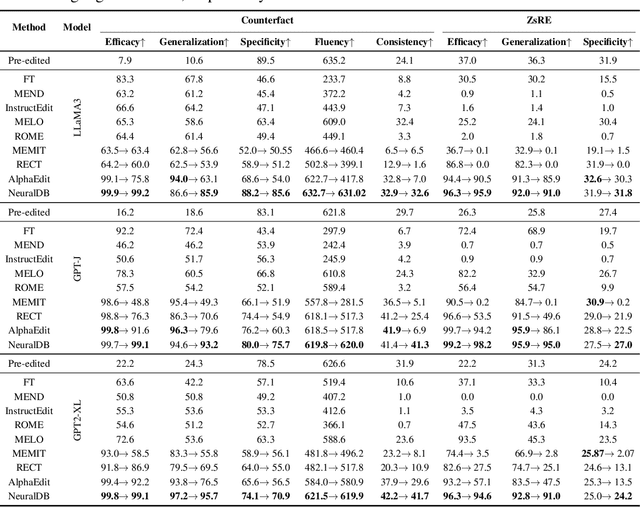
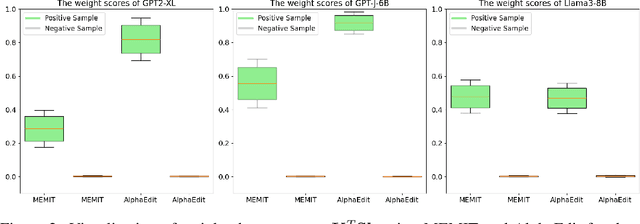

Efficiently editing knowledge stored in large language models (LLMs) enables model updates without large-scale training. One possible solution is Locate-and-Edit (L\&E), allowing simultaneous modifications of a massive number of facts. However, such editing may compromise the general abilities of LLMs and even result in forgetting edited facts when scaling up to thousands of edits. In this paper, we model existing linear L\&E methods as querying a Key-Value (KV) database. From this perspective, we then propose NeuralDB, an editing framework that explicitly represents the edited facts as a neural KV database equipped with a non-linear gated retrieval module, % In particular, our gated module only operates when inference involves the edited facts, effectively preserving the general abilities of LLMs. Comprehensive experiments involving the editing of 10,000 facts were conducted on the ZsRE and CounterFacts datasets, using GPT2-XL, GPT-J (6B) and Llama-3 (8B). The results demonstrate that NeuralDB not only excels in editing efficacy, generalization, specificity, fluency, and consistency, but also preserves overall performance across six representative text understanding and generation tasks. Further experiments indicate that NeuralDB maintains its effectiveness even when scaled to 100,000 facts (\textbf{50x} more than in prior work).
QuestA: Expanding Reasoning Capacity in LLMs via Question Augmentation
Jul 17, 2025Reinforcement learning (RL) has become a key component in training large language reasoning models (LLMs). However, recent studies questions its effectiveness in improving multi-step reasoning-particularly on hard problems. To address this challenge, we propose a simple yet effective strategy via Question Augmentation: introduce partial solutions during training to reduce problem difficulty and provide more informative learning signals. Our method, QuestA, when applied during RL training on math reasoning tasks, not only improves pass@1 but also pass@k-particularly on problems where standard RL struggles to make progress. This enables continual improvement over strong open-source models such as DeepScaleR and OpenMath Nemotron, further enhancing their reasoning capabilities. We achieve new state-of-the-art results on math benchmarks using 1.5B-parameter models: 67.1% (+5.3%) on AIME24, 59.5% (+10.0%) on AIME25, and 35.5% (+4.0%) on HMMT25. Further, we provide theoretical explanations that QuestA improves sample efficiency, offering a practical and generalizable pathway for expanding reasoning capability through RL.
Graph Prompting for Graph Learning Models: Recent Advances and Future Directions
Jun 10, 2025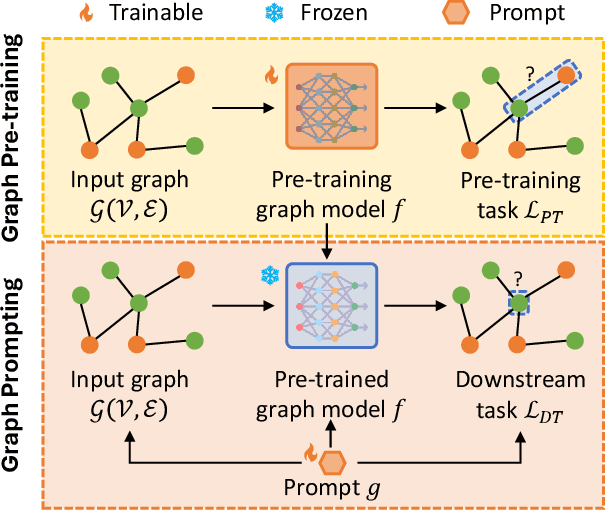
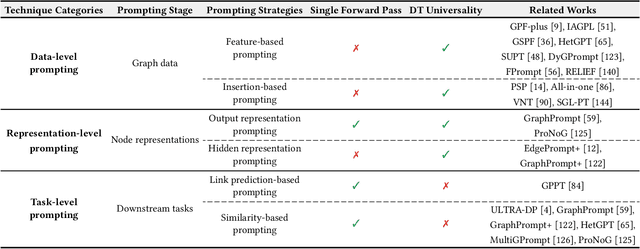
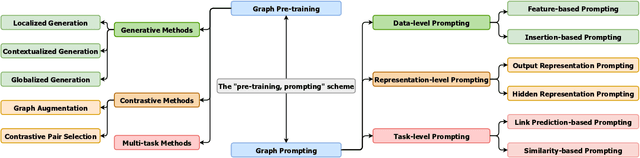
Graph learning models have demonstrated great prowess in learning expressive representations from large-scale graph data in a wide variety of real-world scenarios. As a prevalent strategy for training powerful graph learning models, the "pre-training, adaptation" scheme first pre-trains graph learning models on unlabeled graph data in a self-supervised manner and then adapts them to specific downstream tasks. During the adaptation phase, graph prompting emerges as a promising approach that learns trainable prompts while keeping the pre-trained graph learning models unchanged. In this paper, we present a systematic review of recent advancements in graph prompting. First, we introduce representative graph pre-training methods that serve as the foundation step of graph prompting. Next, we review mainstream techniques in graph prompting and elaborate on how they design learnable prompts for graph prompting. Furthermore, we summarize the real-world applications of graph prompting from different domains. Finally, we discuss several open challenges in existing studies with promising future directions in this field.
Data Mixing Can Induce Phase Transitions in Knowledge Acquisition
May 23, 2025Large Language Models (LLMs) are typically trained on data mixtures: most data come from web scrapes, while a small portion is curated from high-quality sources with dense domain-specific knowledge. In this paper, we show that when training LLMs on such data mixtures, knowledge acquisition from knowledge-dense datasets, unlike training exclusively on knowledge-dense data (arXiv:2404.05405), does not always follow a smooth scaling law but can exhibit phase transitions with respect to the mixing ratio and model size. Through controlled experiments on a synthetic biography dataset mixed with web-scraped data, we demonstrate that: (1) as we increase the model size to a critical value, the model suddenly transitions from memorizing very few to most of the biographies; (2) below a critical mixing ratio, the model memorizes almost nothing even with extensive training, but beyond this threshold, it rapidly memorizes more biographies. We attribute these phase transitions to a capacity allocation phenomenon: a model with bounded capacity must act like a knapsack problem solver to minimize the overall test loss, and the optimal allocation across datasets can change discontinuously as the model size or mixing ratio varies. We formalize this intuition in an information-theoretic framework and reveal that these phase transitions are predictable, with the critical mixing ratio following a power-law relationship with the model size. Our findings highlight a concrete case where a good mixing recipe for large models may not be optimal for small models, and vice versa.
Graph Foundation Models: A Comprehensive Survey
May 21, 2025Graph-structured data pervades domains such as social networks, biological systems, knowledge graphs, and recommender systems. While foundation models have transformed natural language processing, vision, and multimodal learning through large-scale pretraining and generalization, extending these capabilities to graphs -- characterized by non-Euclidean structures and complex relational semantics -- poses unique challenges and opens new opportunities. To this end, Graph Foundation Models (GFMs) aim to bring scalable, general-purpose intelligence to structured data, enabling broad transfer across graph-centric tasks and domains. This survey provides a comprehensive overview of GFMs, unifying diverse efforts under a modular framework comprising three key components: backbone architectures, pretraining strategies, and adaptation mechanisms. We categorize GFMs by their generalization scope -- universal, task-specific, and domain-specific -- and review representative methods, key innovations, and theoretical insights within each category. Beyond methodology, we examine theoretical foundations including transferability and emergent capabilities, and highlight key challenges such as structural alignment, heterogeneity, scalability, and evaluation. Positioned at the intersection of graph learning and general-purpose AI, GFMs are poised to become foundational infrastructure for open-ended reasoning over structured data. This survey consolidates current progress and outlines future directions to guide research in this rapidly evolving field. Resources are available at https://github.com/Zehong-Wang/Awesome-Foundation-Models-on-Graphs.