 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo Heads Are Better Than One: Dual-Model Verbal Reflection at Inference-Time
Feb 26, 2025Large Language Models (LLMs) often struggle with complex reasoning scenarios. While preference optimization methods enhance reasoning performance through training, they often lack transparency in why one reasoning outcome is preferred over another. Verbal reflection techniques improve explainability but are limited in LLMs' critique and refinement capacity. To address these challenges, we introduce a contrastive reflection synthesis pipeline that enhances the accuracy and depth of LLM-generated reflections. We further propose a dual-model reasoning framework within a verbal reinforcement learning paradigm, decoupling inference-time self-reflection into specialized, trained models for reasoning critique and refinement. Extensive experiments show that our framework outperforms traditional preference optimization methods across all evaluation metrics. Our findings also show that "two heads are better than one", demonstrating that a collaborative Reasoner-Critic model achieves superior reasoning performance and transparency, compared to single-model approaches.
An Automated Explainable Educational Assessment System Built on LLMs
Dec 17, 2024
In this demo, we present AERA Chat, an automated and explainable educational assessment system designed for interactive and visual evaluations of student responses. This system leverages large language models (LLMs) to generate automated marking and rationale explanations, addressing the challenge of limited explainability in automated educational assessment and the high costs associated with annotation. Our system allows users to input questions and student answers, providing educators and researchers with insights into assessment accuracy and the quality of LLM-assessed rationales. Additionally, it offers advanced visualization and robust evaluation tools, enhancing the usability for educational assessment and facilitating efficient rationale verification. Our demo video can be found at https://youtu.be/qUSjz-sxlBc.
AERA Chat: An Interactive Platform for Automated Explainable Student Answer Assessment
Oct 12, 2024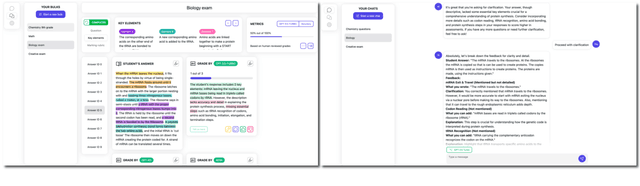

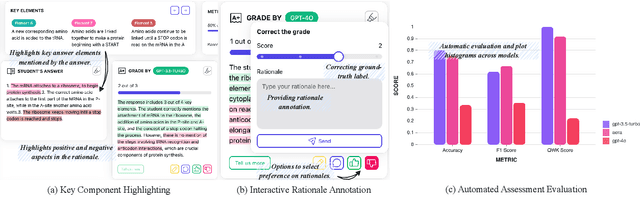
Generating rationales that justify scoring decisions has emerged as a promising approach to enhance explainability in the development of automated scoring systems. However, the scarcity of publicly available rationale data and the high cost of annotation have resulted in existing methods typically relying on noisy rationales generated by large language models (LLMs). To address these challenges, we have developed AERA Chat, an interactive platform, to provide visually explained assessment of student answers and streamline the verification of rationales. Users can input questions and student answers to obtain automated, explainable assessment results from LLMs. The platform's innovative visualization features and robust evaluation tools make it useful for educators to assist their marking process, and for researchers to evaluate assessment performance and quality of rationales generated by different LLMs, or as a tool for efficient annotation. We evaluated three rationale generation approaches on our platform to demonstrate its capability.
Calibrating LLMs with Preference Optimization on Thought Trees for Generating Rationale in Science Question Scoring
Jun 28, 2024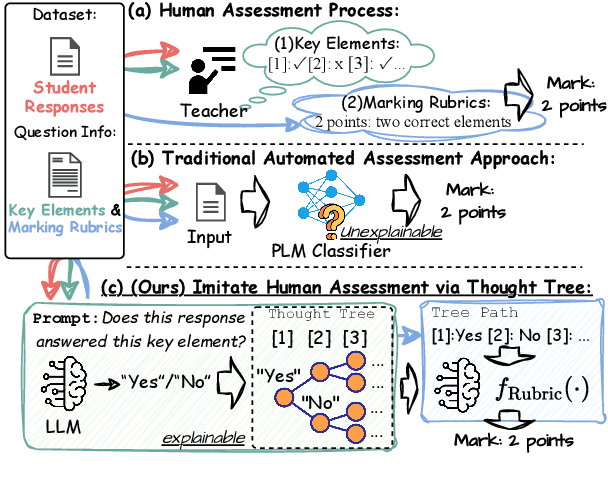
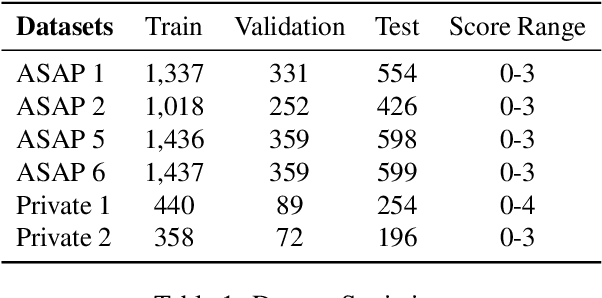
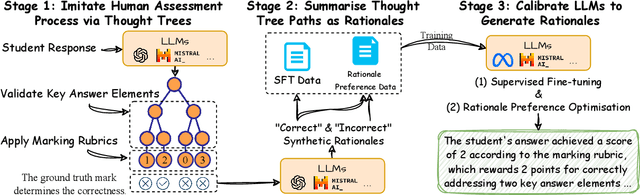
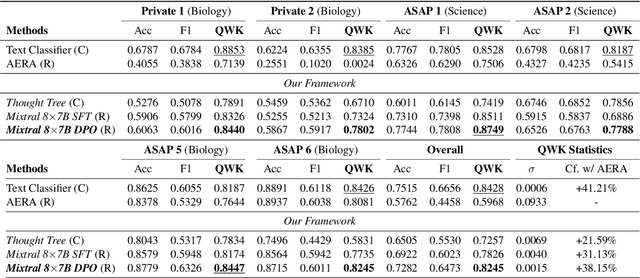
Generating rationales that justify scoring decisions has been a promising way to facilitate explainability in automated scoring systems. However, existing methods do not match the accuracy of classifier-based methods. Plus, the generated rationales often contain hallucinated information. To address these issues, we propose a novel framework capable of generating more faithful rationales and, more importantly, matching performance with classifier-based black-box scoring systems. We first mimic the human assessment process by querying Large Language Models (LLMs) to generate a thought tree. We then summarise intermediate assessment decisions from each thought tree path for creating synthetic rationale data and rationale preference data. Finally, we utilise the generated synthetic data to calibrate LLMs through a two-step training process: supervised fine-tuning and preference optimization. Extensive experimental results demonstrate that our framework achieves a 38% assessment performance improvement in the QWK score compared to prior work while producing higher-quality rationales, as recognised by human evaluators and LLMs. Our work sheds light on the effectiveness of performing preference optimization using synthetic preference data obtained from thought tree paths.
Distilling ChatGPT for Explainable Automated Student Answer Assessment
May 22, 2023



Assessing student answers and providing valuable feedback is crucial for effective learning, but it can be a time-consuming task. Traditional methods of automating student answer assessment through text classification often suffer from issues such as lack of trustworthiness, transparency, and the ability to provide a rationale for the automated assessment process. These limitations hinder their usefulness in practice. In this paper, we explore using ChatGPT, a cutting-edge large language model, for the concurrent tasks of student answer scoring and rationale generation under both the zero-shot and few-shot settings. We introduce a critic module which automatically filters incorrect outputs from ChatGPT and utilizes the remaining ChtaGPT outputs as noisy labelled data to fine-tune a smaller language model, enabling it to perform student answer scoring and rationale generation. Moreover, by drawing multiple samples from ChatGPT outputs, we are able to compute predictive confidence scores, which in turn can be used to identify corrupted data and human label errors in the training set. Our experimental results demonstrate that despite being a few orders of magnitude smaller than ChatGPT, the fine-tuned language model achieves better performance in student answer scoring. Furthermore, it generates more detailed and comprehensible assessments than traditional text classification methods. Our approach provides a viable solution to achieve explainable automated assessment in education.