 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExDDI: Explaining Drug-Drug Interaction Predictions with Natural Language
Sep 09, 2024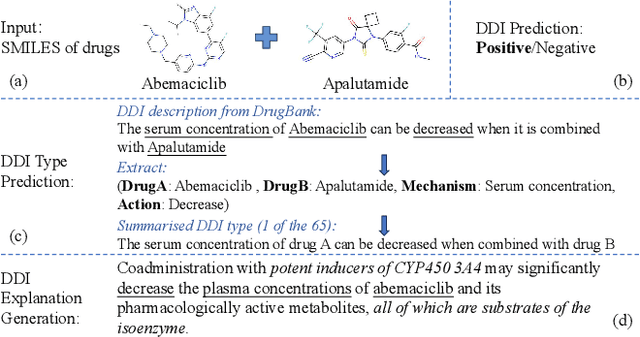


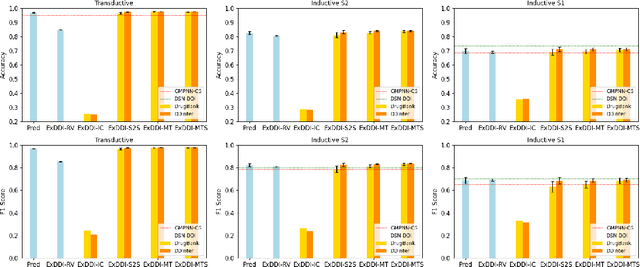
Predicting unknown drug-drug interactions (DDIs) is crucial for improving medication safety. Previous efforts in DDI prediction have typically focused on binary classification or predicting DDI categories, with the absence of explanatory insights that could enhance trust in these predictions. In this work, we propose to generate natural language explanations for DDI predictions, enabling the model to reveal the underlying pharmacodynamics and pharmacokinetics mechanisms simultaneously as making the prediction. To do this, we have collected DDI explanations from DDInter and DrugBank and developed various models for extensive experiments and analysis. Our models can provide accurate explanations for unknown DDIs between known drugs. This paper contributes new tools to the field of DDI prediction and lays a solid foundation for further research on generating explanations for DDI predictions.
Calibrating LLMs with Preference Optimization on Thought Trees for Generating Rationale in Science Question Scoring
Jun 28, 2024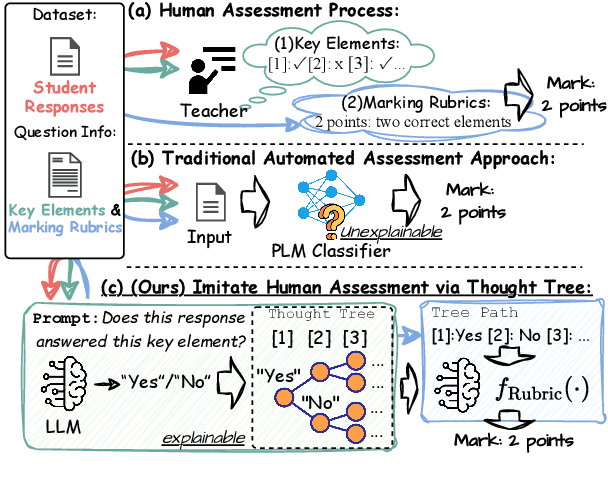
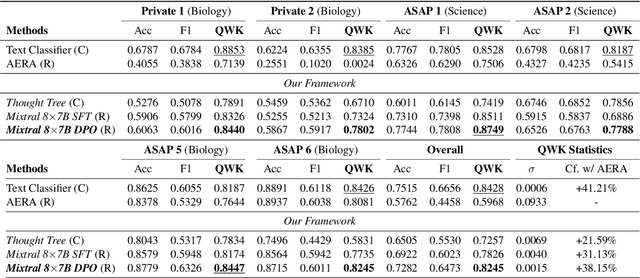
Generating rationales that justify scoring decisions has been a promising way to facilitate explainability in automated scoring systems. However, existing methods do not match the accuracy of classifier-based methods. Plus, the generated rationales often contain hallucinated information. To address these issues, we propose a novel framework capable of generating more faithful rationales and, more importantly, matching performance with classifier-based black-box scoring systems. We first mimic the human assessment process by querying Large Language Models (LLMs) to generate a thought tree. We then summarise intermediate assessment decisions from each thought tree path for creating synthetic rationale data and rationale preference data. Finally, we utilise the generated synthetic data to calibrate LLMs through a two-step training process: supervised fine-tuning and preference optimization. Extensive experimental results demonstrate that our framework achieves a 38% assessment performance improvement in the QWK score compared to prior work while producing higher-quality rationales, as recognised by human evaluators and LLMs. Our work sheds light on the effectiveness of performing preference optimization using synthetic preference data obtained from thought tree paths.
DrugWatch: A Comprehensive Multi-Source Data Visualisation Platform for Drug Safety Information
Jun 18, 2024Drug safety research is crucial for maintaining public health, often requiring comprehensive data support. However, the resources currently available to the public are limited and fail to provide a comprehensive understanding of the relationship between drugs and their side effects. This paper introduces DrugWatch, an easy-to-use and interactive multi-source information visualisation platform for drug safety study. It allows users to understand common side effects of drugs and their statistical information, flexibly retrieve relevant medical reports, or annotate their own medical texts with our automated annotation tool. Supported by NLP technology and enriched with interactive visual components, we are committed to providing researchers and practitioners with a one-stop information analysis, retrieval, and annotation service. The demonstration video is available at https://www.youtube.com/watch?v=RTqDgxzETjw. We also deployed an online demonstration system at https://drugwatch.net/.
Leveraging ChatGPT in Pharmacovigilance Event Extraction: An Empirical Study
Feb 24, 2024With the advent of large language models (LLMs), there has been growing interest in exploring their potential for medical applications. This research aims to investigate the ability of LLMs, specifically ChatGPT, in the context of pharmacovigilance event extraction, of which the main goal is to identify and extract adverse events or potential therapeutic events from textual medical sources. We conduct extensive experiments to assess the performance of ChatGPT in the pharmacovigilance event extraction task, employing various prompts and demonstration selection strategies. The findings demonstrate that while ChatGPT demonstrates reasonable performance with appropriate demonstration selection strategies, it still falls short compared to fully fine-tuned small models. Additionally, we explore the potential of leveraging ChatGPT for data augmentation. However, our investigation reveals that the inclusion of synthesized data into fine-tuning may lead to a decrease in performance, possibly attributed to noise in the ChatGPT-generated labels. To mitigate this, we explore different filtering strategies and find that, with the proper approach, more stable performance can be achieved, although constant improvement remains elusive.
CUE: An Uncertainty Interpretation Framework for Text Classifiers Built on Pre-Trained Language Models
Jun 06, 2023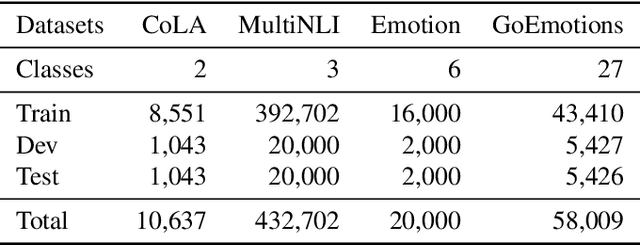
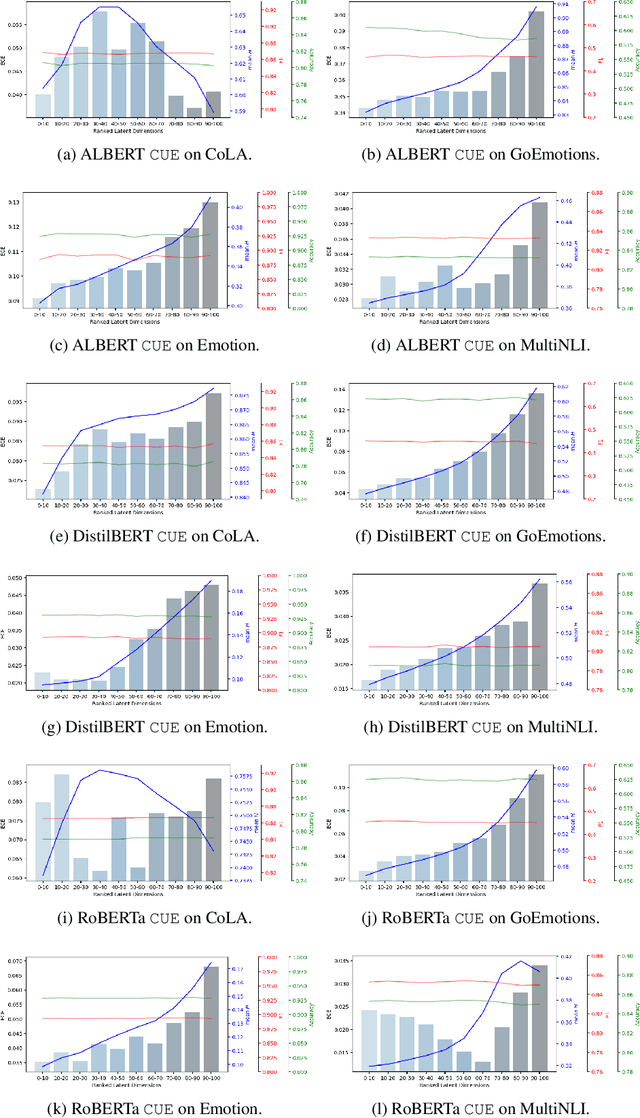


Text classifiers built on Pre-trained Language Models (PLMs) have achieved remarkable progress in various tasks including sentiment analysis, natural language inference, and question-answering. However, the occurrence of uncertain predictions by these classifiers poses a challenge to their reliability when deployed in practical applications. Much effort has been devoted to designing various probes in order to understand what PLMs capture. But few studies have delved into factors influencing PLM-based classifiers' predictive uncertainty. In this paper, we propose a novel framework, called CUE, which aims to interpret uncertainties inherent in the predictions of PLM-based models. In particular, we first map PLM-encoded representations to a latent space via a variational auto-encoder. We then generate text representations by perturbing the latent space which causes fluctuation in predictive uncertainty. By comparing the difference in predictive uncertainty between the perturbed and the original text representations, we are able to identify the latent dimensions responsible for uncertainty and subsequently trace back to the input features that contribute to such uncertainty. Our extensive experiments on four benchmark datasets encompassing linguistic acceptability classification, emotion classification, and natural language inference show the feasibility of our proposed framework. Our source code is available at: https://github.com/lijiazheng99/CUE.
PHEE: A Dataset for Pharmacovigilance Event Extraction from Text
Oct 22, 2022



The primary goal of drug safety researchers and regulators is to promptly identify adverse drug reactions. Doing so may in turn prevent or reduce the harm to patients and ultimately improve public health. Evaluating and monitoring drug safety (i.e., pharmacovigilance) involves analyzing an ever growing collection of spontaneous reports from health professionals, physicians, and pharmacists, and information voluntarily submitted by patients. In this scenario, facilitating analysis of such reports via automation has the potential to rapidly identify safety signals. Unfortunately, public resources for developing natural language models for this task are scant. We present PHEE, a novel dataset for pharmacovigilance comprising over 5000 annotated events from medical case reports and biomedical literature, making it the largest such public dataset to date. We describe the hierarchical event schema designed to provide coarse and fine-grained information about patients' demographics, treatments and (side) effects. Along with the discussion of the dataset, we present a thorough experimental evaluation of current state-of-the-art approaches for biomedical event extraction, point out their limitations, and highlight open challenges to foster future research in this area.