 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUE: An Uncertainty Interpretation Framework for Text Classifiers Built on Pre-Trained Language Models
Paper and Code
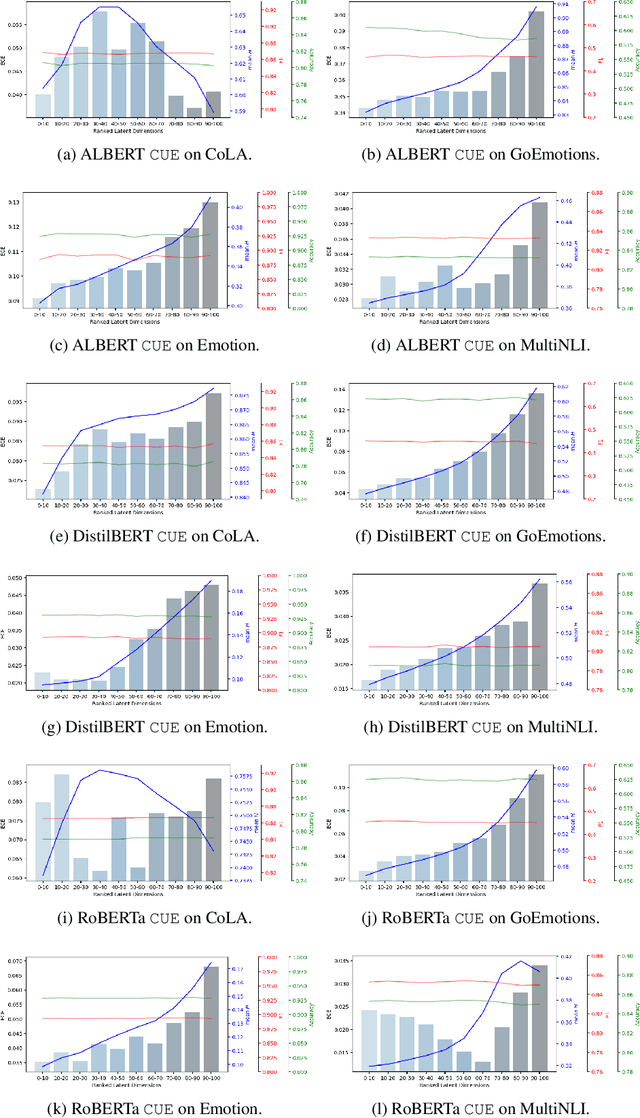


Text classifiers built on Pre-trained Language Models (PLMs) have achieved remarkable progress in various tasks including sentiment analysis, natural language inference, and question-answering. However, the occurrence of uncertain predictions by these classifiers poses a challenge to their reliability when deployed in practical applications. Much effort has been devoted to designing various probes in order to understand what PLMs capture. But few studies have delved into factors influencing PLM-based classifiers' predictive uncertainty. In this paper, we propose a novel framework, called CUE, which aims to interpret uncertainties inherent in the predictions of PLM-based models. In particular, we first map PLM-encoded representations to a latent space via a variational auto-encoder. We then generate text representations by perturbing the latent space which causes fluctuation in predictive uncertainty. By comparing the difference in predictive uncertainty between the perturbed and the original text representations, we are able to identify the latent dimensions responsible for uncertainty and subsequently trace back to the input features that contribute to such uncertainty. Our extensive experiments on four benchmark datasets encompassing linguistic acceptability classification, emotion classification, and natural language inference show the feasibility of our proposed framework. Our source code is available at: https://github.com/lijiazheng99/CUE.