 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement
Feb 04, 2026Large Vision-Language Models (LVLMs) have advanced rapidly by aligning visual patches with the text embedding space, but a fixed visual-token budget forces images to be resized to a uniform pretraining resolution, often erasing fine-grained details and causing hallucinations via over-reliance on language priors. Recent attention-guided enhancement (e.g., cropping or region-focused attention allocation) alleviates this, yet it commonly hinges on a static "magic layer" empirically chosen on simple recognition benchmarks and thus may not transfer to complex reasoning tasks. In contrast to this static assumption, we propose a dynamic perspective on visual grounding. Through a layer-wise sensitivity analysis, we demonstrate that visual grounding is a dynamic process: while simple object recognition tasks rely on middle layers, complex visual search and reasoning tasks require visual information to be reactivated at deeper layers. Based on this observation, we introduce Visual Activation by Query (VAQ), a metric that identifies the layer whose attention map is most relevant to query-specific visual grounding by measuring attention sensitivity to the input query. Building on VAQ, we further propose LASER (Layer-adaptive Attention-guided Selective visual and decoding Enhancement for Reasoning), a training-free inference procedure that adaptively selects task-appropriate layers for visual localization and question answering. Experiments across diverse VQA benchmarks show that LASER significantly improves VQA accuracy across tasks with varying levels of complexity.
Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
Feb 02, 2026Agent memory systems often adopt the standard Retrieval-Augmented Generation (RAG) pipeline, yet its underlying assumptions differ in this setting. RAG targets large, heterogeneous corpora where retrieved passages are diverse, whereas agent memory is a bounded, coherent dialogue stream with highly correlated spans that are often duplicates. Under this shift, fixed top-$k$ similarity retrieval tends to return redundant context, and post-hoc pruning can delete temporally linked prerequisites needed for correct reasoning. We argue retrieval should move beyond similarity matching and instead operate over latent components, following decoupling to aggregation: disentangle memories into semantic components, organise them into a hierarchy, and use this structure to drive retrieval. We propose xMemory, which builds a hierarchy of intact units and maintains a searchable yet faithful high-level node organisation via a sparsity--semantics objective that guides memory split and merge. At inference, xMemory retrieves top-down, selecting a compact, diverse set of themes and semantics for multi-fact queries, and expanding to episodes and raw messages only when it reduces the reader's uncertainty. Experiments on LoCoMo and PerLTQA across the three latest LLMs show consistent gains in answer quality and token efficiency.
Linguistic Neuron Overlap Patterns to Facilitate Cross-lingual Transfer on Low-resource Languages
Aug 23, 2025The current Large Language Models (LLMs) face significant challenges in improving performance on low-resource languages and urgently need data-efficient methods without costly fine-tuning. From the perspective of language-bridge, we propose BridgeX-ICL, a simple yet effective method to improve zero-shot Cross-lingual In-Context Learning (X-ICL) for low-resource languages. Unlike existing works focusing on language-specific neurons, BridgeX-ICL explores whether sharing neurons can improve cross-lingual performance in LLMs or not. We construct neuron probe data from the ground-truth MUSE bilingual dictionaries, and define a subset of language overlap neurons accordingly, to ensure full activation of these anchored neurons. Subsequently, we propose an HSIC-based metric to quantify LLMs' internal linguistic spectrum based on overlap neurons, which guides optimal bridge selection. The experiments conducted on 2 cross-lingual tasks and 15 language pairs from 7 diverse families (covering both high-low and moderate-low pairs) validate the effectiveness of BridgeX-ICL and offer empirical insights into the underlying multilingual mechanisms of LLMs.
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
May 30, 2025Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
Bridging the Long-Term Gap: A Memory-Active Policy for Multi-Session Task-Oriented Dialogue
May 26, 2025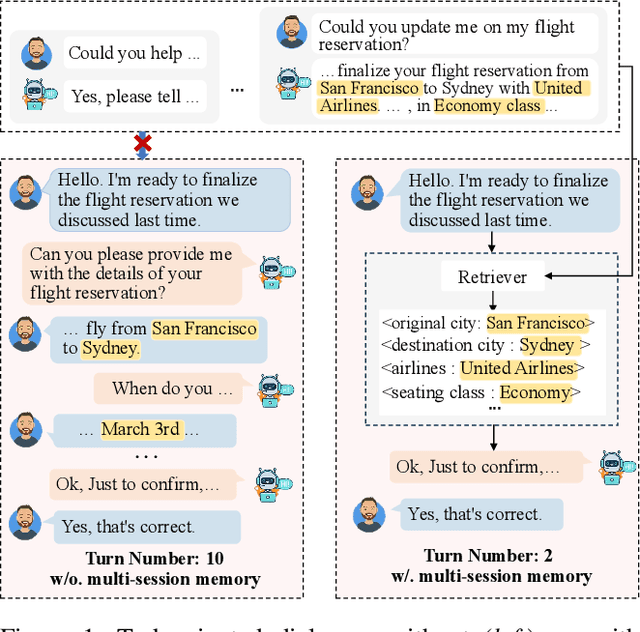
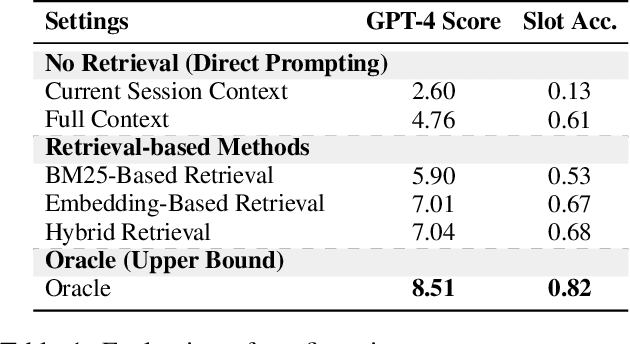
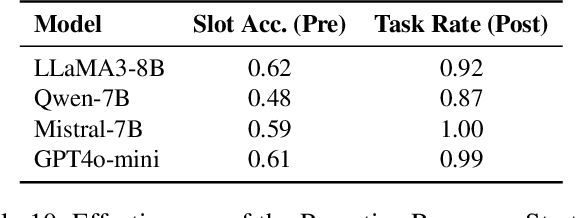
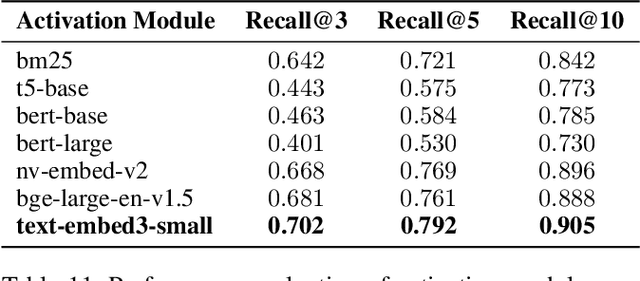
Existing Task-Oriented Dialogue (TOD) systems primarily focus on single-session dialogues, limiting their effectiveness in long-term memory augmentation. To address this challenge, we introduce a MS-TOD dataset, the first multi-session TOD dataset designed to retain long-term memory across sessions, enabling fewer turns and more efficient task completion. This defines a new benchmark task for evaluating long-term memory in multi-session TOD. Based on this new dataset, we propose a Memory-Active Policy (MAP) that improves multi-session dialogue efficiency through a two-stage approach. 1) Memory-Guided Dialogue Planning retrieves intent-aligned history, identifies key QA units via a memory judger, refines them by removing redundant questions, and generates responses based on the reconstructed memory. 2) Proactive Response Strategy detects and correct errors or omissions, ensuring efficient and accurate task completion. We evaluate MAP on MS-TOD dataset, focusing on response quality and effectiveness of the proactive strategy. Experiments on MS-TOD demonstrate that MAP significantly improves task success and turn efficiency in multi-session scenarios, while maintaining competitive performance on conventional single-session tasks.
Sparse Activation Editing for Reliable Instruction Following in Narratives
May 22, 2025

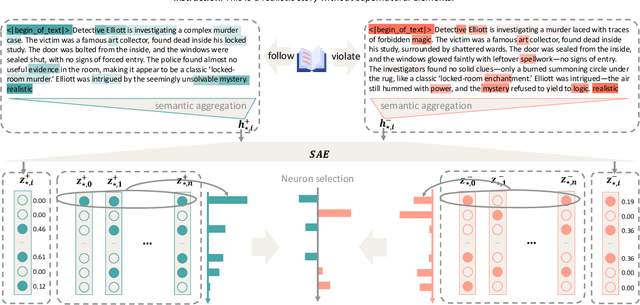

Complex narrative contexts often challenge language models' ability to follow instructions, and existing benchmarks fail to capture these difficulties. To address this, we propose Concise-SAE, a training-free framework that improves instruction following by identifying and editing instruction-relevant neurons using only natural language instructions, without requiring labelled data. To thoroughly evaluate our method, we introduce FreeInstruct, a diverse and realistic benchmark of 1,212 examples that highlights the challenges of instruction following in narrative-rich settings. While initially motivated by complex narratives, Concise-SAE demonstrates state-of-the-art instruction adherence across varied tasks without compromising generation quality.
Bounded and Uniform Energy-based Out-of-distribution Detection for Graphs
Apr 18, 2025Given the critical role of graphs in real-world applications and their high-security requirements, improving the ability of graph neural networks (GNNs) to detect out-of-distribution (OOD) data is an urgent research problem. The recent work GNNSAFE proposes a framework based on the aggregation of negative energy scores that significantly improves the performance of GNNs to detect node-level OOD data. However, our study finds that score aggregation among nodes is susceptible to extreme values due to the unboundedness of the negative energy scores and logit shifts, which severely limits the accuracy of GNNs in detecting node-level OOD data. In this paper, we propose NODESAFE: reducing the generation of extreme scores of nodes by adding two optimization terms that make the negative energy scores bounded and mitigate the logit shift. Experimental results show that our approach dramatically improves the ability of GNNs to detect OOD data at the node level, e.g., in detecting OOD data induced by Structure Manipulation, the metric of FPR95 (lower is better) in scenarios without (with) OOD data exposure are reduced from the current SOTA by 28.4% (22.7%).
SciReplicate-Bench: Benchmarking LLMs in Agent-driven Algorithmic Reproduction from Research Papers
Mar 31, 2025This study evaluates large language models (LLMs) in generating code from algorithm descriptions from recent NLP papers. The task requires two key competencies: (1) algorithm comprehension: synthesizing information from papers and academic literature to understand implementation logic, and (2) coding expertise: identifying dependencies and correctly implementing necessary APIs. To facilitate rigorous evaluation, we introduce SciReplicate-Bench, a benchmark of 100 tasks from 36 NLP papers published in 2024, featuring detailed annotations and comprehensive test cases. Building on SciReplicate-Bench, we propose Sci-Reproducer, a multi-agent framework consisting of a Paper Agent that interprets algorithmic concepts from literature and a Code Agent that retrieves dependencies from repositories and implement solutions. To assess algorithm understanding, we introduce reasoning graph accuracy, which quantifies similarity between generated and reference reasoning graphs derived from code comments and structure. For evaluating implementation quality, we employ execution accuracy, CodeBLEU, and repository dependency/API recall metrics. In our experiments, we evaluate various powerful Non-Reasoning LLMs and Reasoning LLMs as foundational models. The best-performing LLM using Sci-Reproducer achieves only 39% execution accuracy, highlighting the benchmark's difficulty.Our analysis identifies missing or inconsistent algorithm descriptions as key barriers to successful reproduction. We will open-source our benchmark, and code at https://github.com/xyzCS/SciReplicate-Bench.
Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering
Mar 03, 2025



Large language models have recently pushed open domain question answering (ODQA) to new frontiers. However, prevailing retriever-reader pipelines often depend on multiple rounds of prompt level instructions, leading to high computational overhead, instability, and suboptimal retrieval coverage. In this paper, we propose EmbQA, an embedding-level framework that alleviates these shortcomings by enhancing both the retriever and the reader. Specifically, we refine query representations via lightweight linear layers under an unsupervised contrastive learning objective, thereby reordering retrieved passages to highlight those most likely to contain correct answers. Additionally, we introduce an exploratory embedding that broadens the model's latent semantic space to diversify candidate generation and employs an entropy-based selection mechanism to choose the most confident answer automatically. Extensive experiments across three open-source LLMs, three retrieval methods, and four ODQA benchmarks demonstrate that EmbQA substantially outperforms recent baselines in both accuracy and efficiency.
Two Heads Are Better Than One: Dual-Model Verbal Reflection at Inference-Time
Feb 26, 2025Large Language Models (LLMs) often struggle with complex reasoning scenarios. While preference optimization methods enhance reasoning performance through training, they often lack transparency in why one reasoning outcome is preferred over another. Verbal reflection techniques improve explainability but are limited in LLMs' critique and refinement capacity. To address these challenges, we introduce a contrastive reflection synthesis pipeline that enhances the accuracy and depth of LLM-generated reflections. We further propose a dual-model reasoning framework within a verbal reinforcement learning paradigm, decoupling inference-time self-reflection into specialized, trained models for reasoning critique and refinement. Extensive experiments show that our framework outperforms traditional preference optimization methods across all evaluation metrics. Our findings also show that "two heads are better than one", demonstrating that a collaborative Reasoner-Critic model achieves superior reasoning performance and transparency, compared to single-model approaches.