 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciReplicate-Bench: Benchmarking LLMs in Agent-driven Algorithmic Reproduction from Research Papers
Mar 31, 2025This study evaluates large language models (LLMs) in generating code from algorithm descriptions from recent NLP papers. The task requires two key competencies: (1) algorithm comprehension: synthesizing information from papers and academic literature to understand implementation logic, and (2) coding expertise: identifying dependencies and correctly implementing necessary APIs. To facilitate rigorous evaluation, we introduce SciReplicate-Bench, a benchmark of 100 tasks from 36 NLP papers published in 2024, featuring detailed annotations and comprehensive test cases. Building on SciReplicate-Bench, we propose Sci-Reproducer, a multi-agent framework consisting of a Paper Agent that interprets algorithmic concepts from literature and a Code Agent that retrieves dependencies from repositories and implement solutions. To assess algorithm understanding, we introduce reasoning graph accuracy, which quantifies similarity between generated and reference reasoning graphs derived from code comments and structure. For evaluating implementation quality, we employ execution accuracy, CodeBLEU, and repository dependency/API recall metrics. In our experiments, we evaluate various powerful Non-Reasoning LLMs and Reasoning LLMs as foundational models. The best-performing LLM using Sci-Reproducer achieves only 39% execution accuracy, highlighting the benchmark's difficulty.Our analysis identifies missing or inconsistent algorithm descriptions as key barriers to successful reproduction. We will open-source our benchmark, and code at https://github.com/xyzCS/SciReplicate-Bench.
GARLIC: LLM-Guided Dynamic Progress Control with Hierarchical Weighted Graph for Long Document QA
Oct 07, 2024In the past, Retrieval-Augmented Generation (RAG) methods split text into chunks to enable language models to handle long documents. Recent tree-based RAG methods are able to retrieve detailed information while preserving global context. However, with the advent of more powerful LLMs, such as Llama 3.1, which offer better comprehension and support for longer inputs, we found that even recent tree-based RAG methods perform worse than directly feeding the entire document into Llama 3.1, although RAG methods still hold an advantage in reducing computational costs. In this paper, we propose a new retrieval method, called LLM-Guided Dynamic Progress Control with Hierarchical Weighted Graph (GARLIC), which outperforms previous state-of-the-art baselines, including Llama 3.1, while retaining the computational efficiency of RAG methods. Our method introduces several improvements: (1) Rather than using a tree structure, we construct a Hierarchical Weighted Directed Acyclic Graph with many-to-many summarization, where the graph edges are derived from attention mechanisms, and each node focuses on a single event or very few events. (2) We introduce a novel retrieval method that leverages the attention weights of LLMs rather than dense embedding similarity. Our method allows for searching the graph along multiple paths and can terminate at any depth. (3) We use the LLM to control the retrieval process, enabling it to dynamically adjust the amount and depth of information retrieved for different queries. Experimental results show that our method outperforms previous state-of-the-art baselines, including Llama 3.1, on two single-document and two multi-document QA datasets, while maintaining similar computational complexity to traditional RAG methods.
Encourage or Inhibit Monosemanticity? Revisit Monosemanticity from a Feature Decorrelation Perspective
Jun 25, 2024
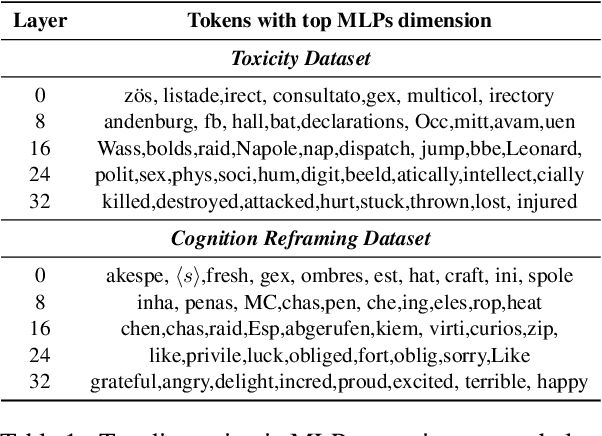
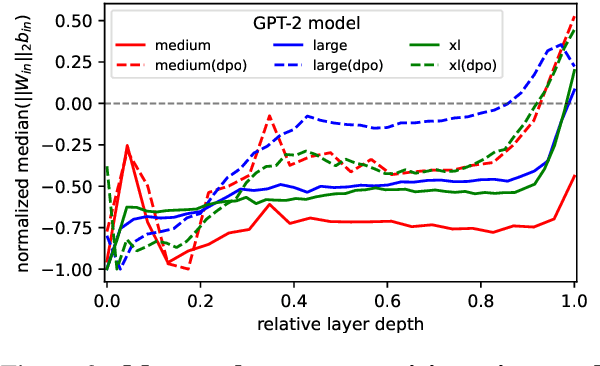

To better interpret the intrinsic mechanism of large language models (LLMs), recent studies focus on monosemanticity on its basic units. A monosemantic neuron is dedicated to a single and specific concept, which forms a one-to-one correlation between neurons and concepts. Despite extensive research in monosemanticity probing, it remains unclear whether monosemanticity is beneficial or harmful to model capacity. To explore this question, we revisit monosemanticity from the feature decorrelation perspective and advocate for its encouragement. We experimentally observe that the current conclusion by wang2024learning, which suggests that decreasing monosemanticity enhances model performance, does not hold when the model changes. Instead, we demonstrate that monosemanticity consistently exhibits a positive correlation with model capacity, in the preference alignment process. Consequently, we apply feature correlation as a proxy for monosemanticity and incorporate a feature decorrelation regularizer into the dynamic preference optimization process. The experiments show that our method not only enhances representation diversity and activation sparsity but also improves preference alignment performance.
Addressing Order Sensitivity of In-Context Demonstration Examples in Causal Language Models
Feb 23, 2024In-context learning has become a popular paradigm in natural language processing. However, its performance can be significantly influenced by the order of in-context demonstration examples. In this paper, we found that causal language models (CausalLMs) are more sensitive to this order compared to prefix language models (PrefixLMs). We attribute this phenomenon to the auto-regressive attention masks within CausalLMs, which restrict each token from accessing information from subsequent tokens. This results in different receptive fields for samples at different positions, thereby leading to representation disparities across positions. To tackle this challenge, we introduce an unsupervised fine-tuning method, termed the Information-Augmented and Consistency-Enhanced approach. This approach utilizes contrastive learning to align representations of in-context examples across different positions and introduces a consistency loss to ensure similar representations for inputs with different permutations. This enhances the model's predictive consistency across permutations. Experimental results on four benchmarks suggest that our proposed method can reduce the sensitivity to the order of in-context examples and exhibit robust generalizability, particularly when demonstrations are sourced from a pool different from that used in the training phase, or when the number of in-context examples differs from what is used during training.
The Mystery and Fascination of LLMs: A Comprehensive Survey on the Interpretation and Analysis of Emergent Abilities
Nov 01, 2023

Understanding emergent abilities, such as in-context learning (ICL) and chain-of-thought (CoT) prompting in large language models (LLMs), is of utmost importance. This importance stems not only from the better utilization of these capabilities across various tasks, but also from the proactive identification and mitigation of potential risks, including concerns of truthfulness, bias, and toxicity, that may arise alongside these capabilities. In this paper, we present a thorough survey on the interpretation and analysis of emergent abilities of LLMs. First, we provide a concise introduction to the background and definition of emergent abilities. Then, we give an overview of advancements from two perspectives: 1) a macro perspective, emphasizing studies on the mechanistic interpretability and delving into the mathematical foundations behind emergent abilities; and 2) a micro-perspective, concerning studies that focus on empirical interpretability by examining factors associated with these abilities. We conclude by highlighting the challenges encountered and suggesting potential avenues for future research. We believe that our work establishes the basis for further exploration into the interpretation of emergent abilities.