 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrecting Large Language Model Behavior via Influence Function
Dec 21, 2024
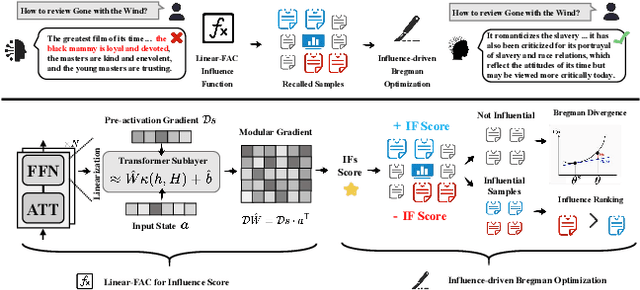
Recent advancements in AI alignment techniques have significantly improved the alignment of large language models (LLMs) with static human preferences. However, the dynamic nature of human preferences can render some prior training data outdated or even erroneous, ultimately causing LLMs to deviate from contemporary human preferences and societal norms. Existing methodologies, whether they involve the curation of new data for continual alignment or the manual correction of outdated data for re-alignment, demand costly human resources. To address this challenge, we propose a novel approach, Large Language Model Behavior Correction with Influence Function Recall and Post-Training (LANCET), which requires no human involvement. LANCET consists of two phases: (1) using influence functions to identify the training data that significantly impact undesirable model outputs, and (2) applying an Influence function-driven Bregman Optimization (IBO) technique to adjust the model's behavior based on these influence distributions. Our experiments demonstrate that LANCET effectively and efficiently correct inappropriate behaviors of LLMs. Furthermore, LANCET can outperform methods that rely on collecting human preferences, and it enhances the interpretability of learning human preferences within LLMs.
Enhancing Decision-Making for LLM Agents via Step-Level Q-Value Models
Sep 14, 2024



Agents significantly enhance the capabilities of standalone Large Language Models (LLMs) by perceiving environments, making decisions, and executing actions. However, LLM agents still face challenges in tasks that require multiple decision-making steps. Estimating the value of actions in specific tasks is difficult when intermediate actions are neither appropriately rewarded nor penalized. In this paper, we propose leveraging a task-relevant Q-value model to guide action selection. Specifically, we first collect decision-making trajectories annotated with step-level Q values via Monte Carlo Tree Search (MCTS) and construct preference data. We then use another LLM to fit these preferences through step-level Direct Policy Optimization (DPO), which serves as the Q-value model. During inference, at each decision-making step, LLM agents select the action with the highest Q value before interacting with the environment. We apply our method to various open-source and API-based LLM agents, demonstrating that Q-value models significantly improve their performance. Notably, the performance of the agent built with Phi-3-mini-4k-instruct improved by 103% on WebShop and 75% on HotPotQA when enhanced with Q-value models, even surpassing GPT-4o-mini. Additionally, Q-value models offer several advantages, such as generalization to different LLM agents and seamless integration with existing prompting strategies.
Online Self-Preferring Language Models
May 23, 2024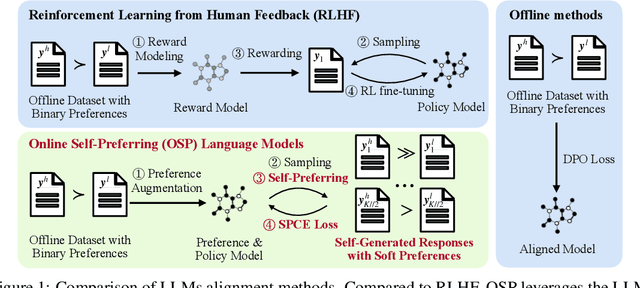
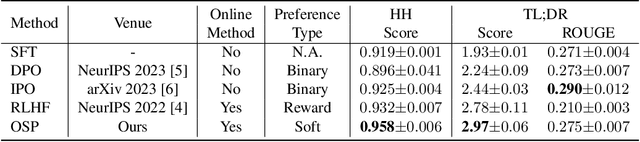
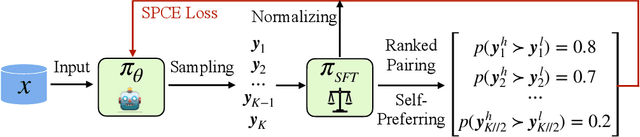
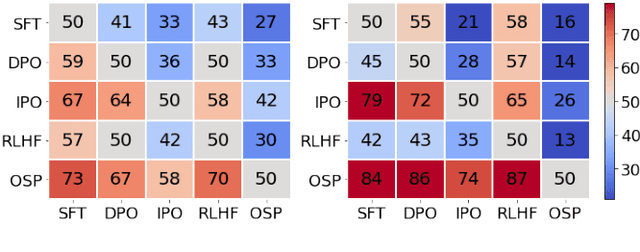
Aligning with human preference datasets has been critical to the success of large language models (LLMs). Reinforcement learning from human feedback (RLHF) employs a costly reward model to provide feedback for on-policy sampling responses. Recently, offline methods that directly fit responses with binary preferences in the dataset have emerged as alternatives. However, existing methods do not explicitly model preference strength information, which is crucial for distinguishing different response pairs. To overcome this limitation, we propose Online Self-Preferring (OSP) language models to learn from self-generated response pairs and self-judged preference strengths. For each prompt and corresponding self-generated responses, we introduce a ranked pairing method to construct multiple response pairs with preference strength information. We then propose the soft-preference cross-entropy loss to leverage such information. Empirically, we demonstrate that leveraging preference strength is crucial for avoiding overfitting and enhancing alignment performance. OSP achieves state-of-the-art alignment performance across various metrics in two widely used human preference datasets. OSP is parameter-efficient and more robust than the dominant online method, RLHF when limited offline data are available and generalizing to out-of-domain tasks. Moreover, OSP language models established by LLMs with proficiency in self-preferring can efficiently self-improve without external supervision.
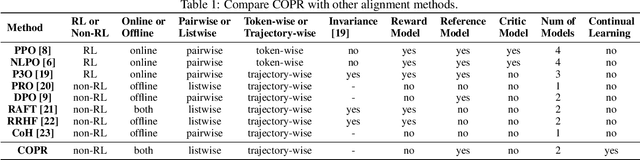
COPR: Continual Human Preference Learning via Optimal Policy Regularization
Feb 27, 2024Reinforcement Learning from Human Feedback (RLHF) is commonly utilized to improve the alignment of Large Language Models (LLMs) with human preferences. Given the evolving nature of human preferences, continual alignment becomes more crucial and practical in comparison to traditional static alignment. Nevertheless, making RLHF compatible with Continual Learning (CL) is challenging due to its complex process. Meanwhile, directly learning new human preferences may lead to Catastrophic Forgetting (CF) of historical preferences, resulting in helpless or harmful outputs. To overcome these challenges, we propose the Continual Optimal Policy Regularization (COPR) method, which draws inspiration from the optimal policy theory. COPR utilizes a sampling distribution as a demonstration and regularization constraints for CL. It adopts the Lagrangian Duality (LD) method to dynamically regularize the current policy based on the historically optimal policy, which prevents CF and avoids over-emphasizing unbalanced objectives. We also provide formal proof for the learnability of COPR. The experimental results show that COPR outperforms strong CL baselines on our proposed benchmark, in terms of reward-based, GPT-4 evaluations and human assessment. Furthermore, we validate the robustness of COPR under various CL settings, including different backbones, replay memory sizes, and learning orders.
Optimistic Model Rollouts for Pessimistic Offline Policy Optimization
Jan 11, 2024



Model-based offline reinforcement learning (RL) has made remarkable progress, offering a promising avenue for improving generalization with synthetic model rollouts. Existing works primarily focus on incorporating pessimism for policy optimization, usually via constructing a Pessimistic Markov Decision Process (P-MDP). However, the P-MDP discourages the policies from learning in out-of-distribution (OOD) regions beyond the support of offline datasets, which can under-utilize the generalization ability of dynamics models. In contrast, we propose constructing an Optimistic MDP (O-MDP). We initially observed the potential benefits of optimism brought by encouraging more OOD rollouts. Motivated by this observation, we present ORPO, a simple yet effective model-based offline RL framework. ORPO generates Optimistic model Rollouts for Pessimistic offline policy Optimization. Specifically, we train an optimistic rollout policy in the O-MDP to sample more OOD model rollouts. Then we relabel the sampled state-action pairs with penalized rewards and optimize the output policy in the P-MDP. Theoretically, we demonstrate that the performance of policies trained with ORPO can be lower-bounded in linear MDPs. Experimental results show that our framework significantly outperforms P-MDP baselines by a margin of 30%, achieving state-of-the-art performance on the widely-used benchmark. Moreover, ORPO exhibits notable advantages in problems that require generalization.
Uncertainty-Penalized Reinforcement Learning from Human Feedback with Diverse Reward LoRA Ensembles
Dec 30, 2023Reinforcement learning from human feedback (RLHF) emerges as a promising paradigm for aligning large language models (LLMs). However, a notable challenge in RLHF is overoptimization, where beyond a certain threshold, the pursuit of higher rewards leads to a decline in human preferences. In this paper, we observe the weakness of KL regularization which is commonly employed in existing RLHF methods to address overoptimization. To mitigate this limitation, we scrutinize the RLHF objective in the offline dataset and propose uncertainty-penalized RLHF (UP-RLHF), which incorporates uncertainty regularization during RL-finetuning. To enhance the uncertainty quantification abilities for reward models, we first propose a diverse low-rank adaptation (LoRA) ensemble by maximizing the nuclear norm of LoRA matrix concatenations. Then we optimize policy models utilizing penalized rewards, determined by both rewards and uncertainties provided by the diverse reward LoRA ensembles. Our experimental results, based on two real human preference datasets, showcase the effectiveness of diverse reward LoRA ensembles in quantifying reward uncertainty. Additionally, uncertainty regularization in UP-RLHF proves to be pivotal in mitigating overoptimization, thereby contributing to the overall performance.
COPF: Continual Learning Human Preference through Optimal Policy Fitting
Oct 28, 2023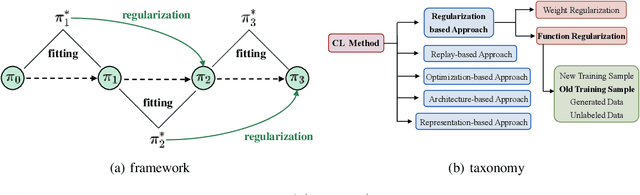


The technique of Reinforcement Learning from Human Feedback (RLHF) is a commonly employed method to improve pre-trained Language Models (LM), enhancing their ability to conform to human preferences. Nevertheless, the current RLHF-based LMs necessitate full retraining each time novel queries or feedback are introduced, which becomes a challenging task because human preferences can vary between different domains or tasks. Retraining LMs poses practical difficulties in many real-world situations due to the significant time and computational resources required, along with concerns related to data privacy. To address this limitation, we propose a new method called Continual Optimal Policy Fitting (COPF), in which we estimate a series of optimal policies using the Monte Carlo method, and then continually fit the policy sequence with the function regularization. COPF involves a single learning phase and doesn't necessitate complex reinforcement learning. Importantly, it shares the capability with RLHF to learn from unlabeled data, making it flexible for continual preference learning. Our experimental results show that COPF outperforms strong Continuous learning (CL) baselines when it comes to consistently aligning with human preferences on different tasks and domains.
Self-Supervised Exploration via Temporal Inconsistency in Reinforcement Learning
Aug 24, 2022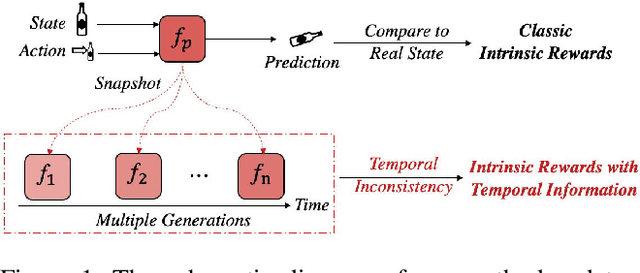
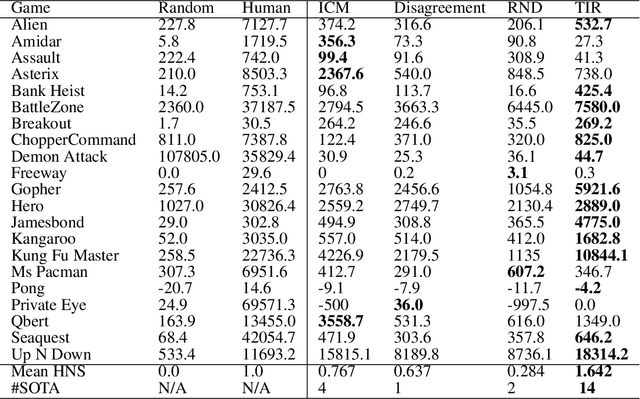
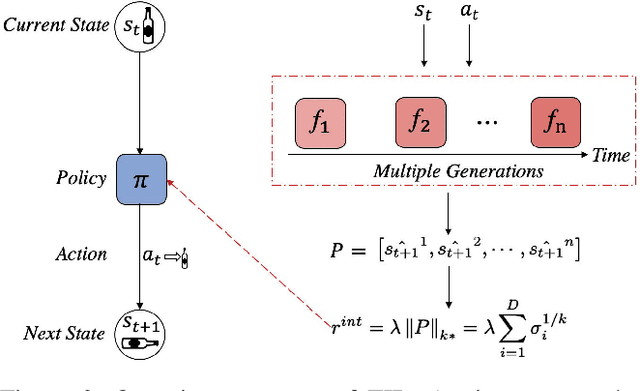

In real-world scenarios, reinforcement learning under sparse-reward synergistic settings has remained challenging, despite surging interests in this field. Previous attempts suggest that intrinsic reward can alleviate the issue caused by sparsity. In this paper, we present a novel intrinsic reward that is inspired by human learning, as humans evaluate curiosity by comparing current observations with historical knowledge. Specifically, we train a self-supervised prediction model and save a set of snapshots of the model parameters, without incurring addition training cost. Then we employ nuclear norm to evaluate the temporal inconsistency between the predictions of different snapshots, which can be further deployed as the intrinsic reward. Moreover, a variational weighting mechanism is proposed to assign weight to different snapshots in an adaptive manner. We demonstrate the efficacy of the proposed method in various benchmark environments. The results suggest that our method can provide overwhelming state-of-the-art performance compared with other intrinsic reward-based methods, without incurring additional training costs and maintaining higher noise tolerance. Our code will be released publicly to enhance reproducibility.
Dynamic Memory-based Curiosity: A Bootstrap Approach for Exploration
Aug 24, 2022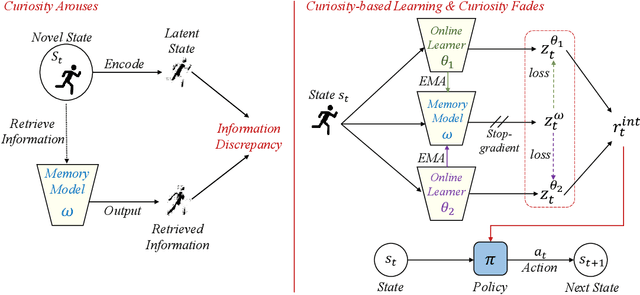
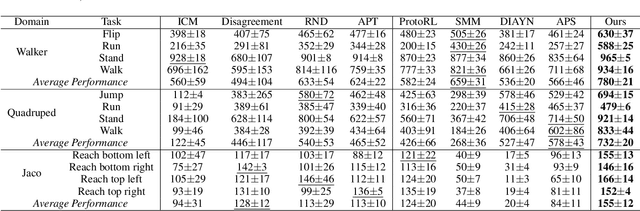
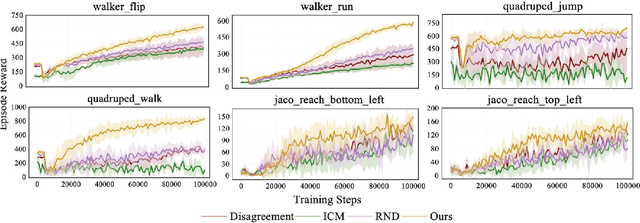
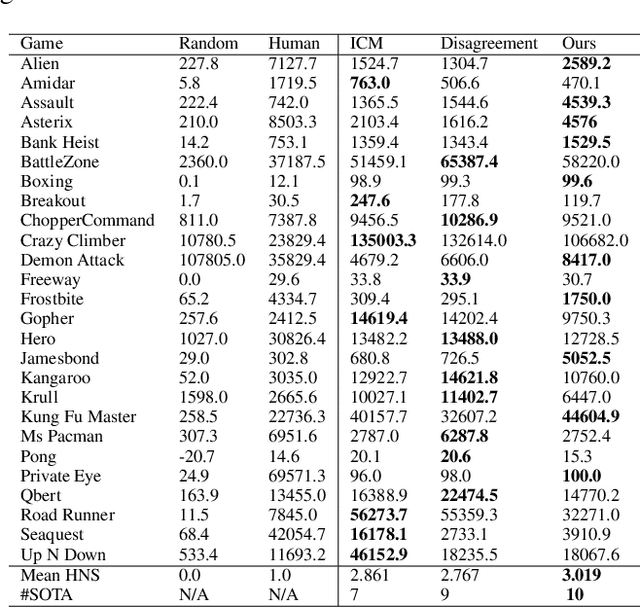
The sparsity of extrinsic rewards poses a serious challenge for reinforcement learning (RL). Currently, many efforts have been made on curiosity which can provide a representative intrinsic reward for effective exploration. However, the challenge is still far from being solved. In this paper, we present a novel curiosity for RL, named DyMeCu, which stands for Dynamic Memory-based Curiosity. Inspired by human curiosity and information theory, DyMeCu consists of a dynamic memory and dual online learners. The curiosity arouses if memorized information can not deal with the current state, and the information gap between dual learners can be formulated as the intrinsic reward for agents, and then such state information can be consolidated into the dynamic memory. Compared with previous curiosity methods, DyMeCu can better mimic human curiosity with dynamic memory, and the memory module can be dynamically grown based on a bootstrap paradigm with dual learners. On multiple benchmarks including DeepMind Control Suite and Atari Suite, large-scale empirical experiments are conducted and the results demonstrate that DyMeCu outperforms competitive curiosity-based methods with or without extrinsic rewards. We will release the code to enhance reproducibility.