 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOPF: Continual Learning Human Preference through Optimal Policy Fitting
Paper and Code
Oct 28, 2023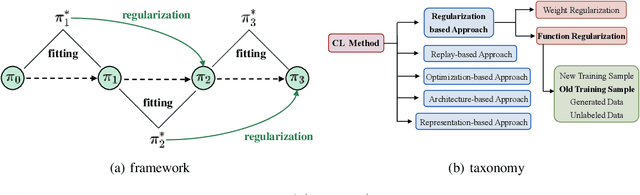
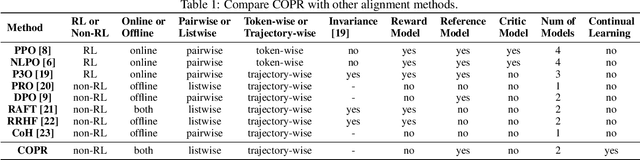


The technique of Reinforcement Learning from Human Feedback (RLHF) is a commonly employed method to improve pre-trained Language Models (LM), enhancing their ability to conform to human preferences. Nevertheless, the current RLHF-based LMs necessitate full retraining each time novel queries or feedback are introduced, which becomes a challenging task because human preferences can vary between different domains or tasks. Retraining LMs poses practical difficulties in many real-world situations due to the significant time and computational resources required, along with concerns related to data privacy. To address this limitation, we propose a new method called Continual Optimal Policy Fitting (COPF), in which we estimate a series of optimal policies using the Monte Carlo method, and then continually fit the policy sequence with the function regularization. COPF involves a single learning phase and doesn't necessitate complex reinforcement learning. Importantly, it shares the capability with RLHF to learn from unlabeled data, making it flexible for continual preference learning. Our experimental results show that COPF outperforms strong Continuous learning (CL) baselines when it comes to consistently aligning with human preferences on different tasks and domains.