 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabChange: Precise Attribute Changes in Tabular Data
May 30, 2026Modifying an attribute in tabular data often introduces an unnatural instance by breaking its relationships with other attributes. The modified instance must be both natural and minimally changed from the original instance. This paper addresses the challenge of generating such a modified instance. We identify key limitations in existing approaches: generative models either don't support instance-level attribute editing or, in the case of methods like CVAE, retain attribute information in the latent space, leading to unnecessary modifications. To solve this, we propose TabChange, an approach that analyzes the relationship between the attribute of interest and other attributes in the dataset. If the relationship is weak, it simply flips the attribute; if it is strong, it uses an adversarial framework that removes information about the attribute in the latent space representation. This removal enables precise modifications, making only the necessary adjustments to maintain naturalness. Our experiments across seven datasets show that TabChange generates counterfactuals in attributes that are comparable in naturalness and are more proximal to their original instances. This leads to a higher number of valid counterfactuals and a lower number of invalid counterfactuals compared to the baselines.
Threshold-Guided Optimization for Visual Generative Models
May 06, 2026Aligning large visual generative models with human feedback is often performed through pairwise preference optimization. While such approaches are conceptually simple, they fundamentally rely on annotated pairs, limiting scalability in settings where feedback is collected as independent scalar ratings. In this work, we revisit the KL-regularized alignment objective and show that the optimal policy implicitly compares each sample's reward to an instance-specific baseline that is generally intractable. We propose a threshold-guided alignment framework that replaces this oracle baseline with a data-driven global threshold estimated from empirical score statistics. This formulation turns alignment into a binary decision task on unpaired data, enabling effective optimization directly from scalar feedback. We also incorporate a confidence weighting term to emphasize samples whose scores deviate strongly from the threshold, improving sample efficiency. Experiments across both diffusion and masked generative paradigms, spanning three test sets and five reward models, show that our method consistently improves preference alignment over previous methods. These results position our threshold-guided framework as a simple yet principled alternative for aligning visual generative models without paired comparisons.
ReaGeo: Reasoning-Enhanced End-to-End Geocoding with LLMs
Apr 23, 2026This paper proposes ReaGeo, an end-to-end geocoding framework based on large language models, designed to overcome the limitations of traditional multi-stage approaches that rely on text or vector similarity retrieval over geographic databases, including workflow complexity, error propagation, and heavy dependence on structured geographic knowledge bases. The method converts geographic coordinates into geohash sequences, reformulating the coordinate prediction task as a text generation problem, and introduces a Chain-of-Thought mechanism to enhance the model's reasoning over spatial relationships. Furthermore, reinforcement learning with a distance-deviation-based reward is applied to optimize the generation accuracy. Comprehensive experiments show that ReaGeo can accurately handle explicit address queries in single-point predictions and effectively resolve vague relative location queries. In addition, the model demonstrates strong predictive capability for non-point geometric regions, highlighting its versatility and generalization ability in geocoding tasks.
A novel LSTM music generator based on the fractional time-frequency feature extraction
Apr 20, 2026In this paper, we propose a novel approach for generating music based on an artificial intelligence (AI) system. We analyze the features of music and use them to fit and predict the music. The fractional Fourier transform (FrFT) and the long short-term memory (LSTM) network are the foundations of our method. The FrFT method is used to extract the spectral features of a music piece, where the music signal is expressed on the time and frequency domains. The LSTM network is used to generate new music based on the extracted features, where we predict the music according to the hidden layer features and real-time inputs using GiantMIDI-Piano dataset. The results of our experiments show that our proposed system is capable of generating high-quality music that is comparable to human-generated music.
A Mechanistic Analysis of Sim-and-Real Co-Training in Generative Robot Policies
Apr 15, 2026Co-training, which combines limited in-domain real-world data with abundant surrogate data such as simulation or cross-embodiment robot data, is widely used for training generative robot policies. Despite its empirical success, the mechanisms that determine when and why co-training is effective remain poorly understood. We investigate the mechanism of sim-and-real co-training through theoretical analysis and empirical study, and identify two intrinsic effects governing performance. The first, \textbf{``structured representation alignment"}, reflects a balance between cross-domain representation alignment and domain discernibility, and plays a primary role in downstream performance. The second, the \textbf{``importance reweighting effect"}, arises from domain-dependent modulation of action weighting and operates at a secondary level. We validate these effects with controlled experiments on a toy model and extensive sim-and-sim and sim-and-real robot manipulation experiments. Our analysis offers a unified interpretation of recent co-training techniques and motivates a simple method that consistently improves upon prior approaches. More broadly, our aim is to examine the inner workings of co-training and to facilitate research in this direction.
TabKD: Tabular Knowledge Distillation through Interaction Diversity of Learned Feature Bins
Mar 16, 2026Data-free knowledge distillation enables model compression without original training data, critical for privacy-sensitive tabular domains. However, existing methods does not perform well on tabular data because they do not explicitly address feature interactions, the fundamental way tabular models encode predictive knowledge. We identify interaction diversity, systematic coverage of feature combinations, as an essential requirement for effective tabular distillation. To operationalize this insight, we propose TabKD, which learns adaptive feature bins aligned with teacher decision boundaries, then generates synthetic queries that maximize pairwise interaction coverage. Across 4 benchmark datasets and 4 teacher architectures, TabKD achieves highest student-teacher agreement in 14 out of 16 configurations, outperforming 5 state-of-the-art baselines. We further show that interaction coverage strongly correlates with distillation quality, validating our core hypothesis. Our work establishes interaction-focused exploration as a principled framework for tabular model extraction.
DD-CAM: Minimal Sufficient Explanations for Vision Models Using Delta Debugging
Feb 22, 2026We introduce a gradient-free framework for identifying minimal, sufficient, and decision-preserving explanations in vision models by isolating the smallest subset of representational units whose joint activation preserves predictions. Unlike existing approaches that aggregate all units, often leading to cluttered saliency maps, our approach, DD-CAM, identifies a 1-minimal subset whose joint activation suffices to preserve the prediction (i.e., removing any unit from the subset alters the prediction). To efficiently isolate minimal sufficient subsets, we adapt delta debugging, a systematic reduction strategy from software debugging, and configure its search strategy based on unit interactions in the classifier head: testing individual units for models with non-interacting units and testing unit combinations for models in which unit interactions exist. We then generate minimal, prediction-preserving saliency maps that highlight only the most essential features. Our experimental evaluation demonstrates that our approach can produce more faithful explanations and achieve higher localization accuracy than the state-of-the-art CAM-based approaches.
A DeepSeek-Powered AI System for Automated Chest Radiograph Interpretation in Clinical Practice
Dec 23, 2025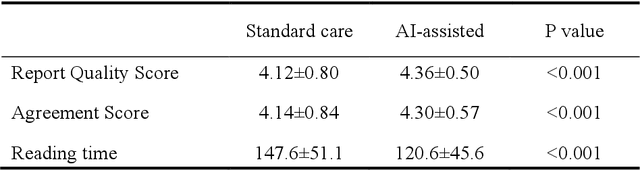
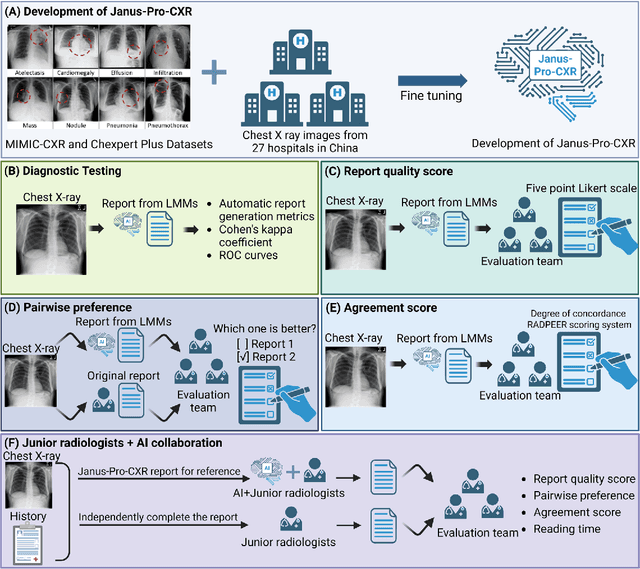
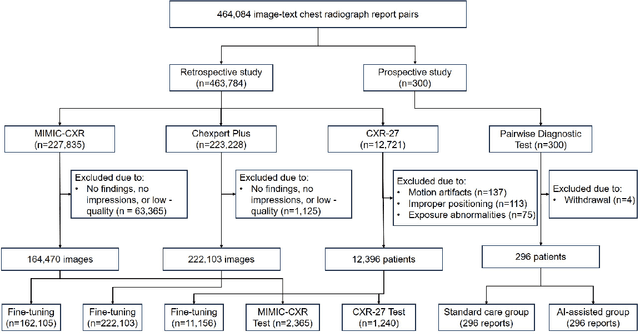
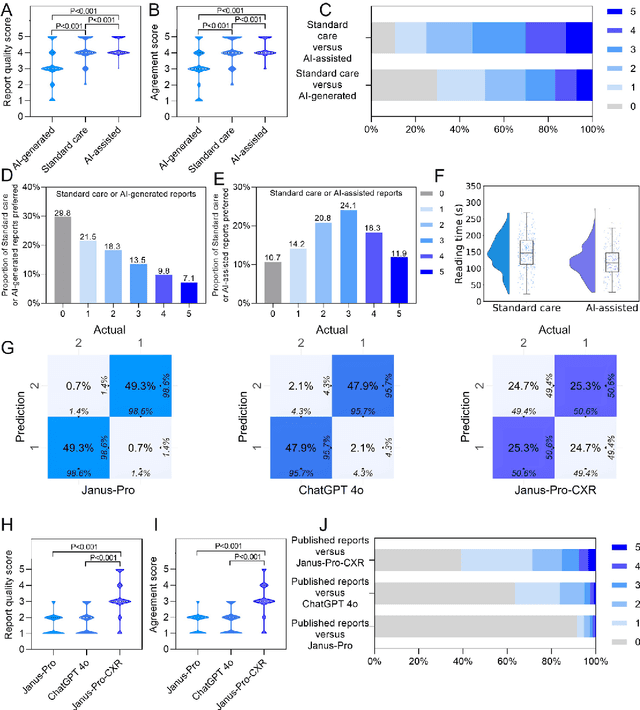
A global shortage of radiologists has been exacerbated by the significant volume of chest X-ray workloads, particularly in primary care. Although multimodal large language models show promise, existing evaluations predominantly rely on automated metrics or retrospective analyses, lacking rigorous prospective clinical validation. Janus-Pro-CXR (1B), a chest X-ray interpretation system based on DeepSeek Janus-Pro model, was developed and rigorously validated through a multicenter prospective trial (NCT07117266). Our system outperforms state-of-the-art X-ray report generation models in automated report generation, surpassing even larger-scale models including ChatGPT 4o (200B parameters), while demonstrating reliable detection of six clinically critical radiographic findings. Retrospective evaluation confirms significantly higher report accuracy than Janus-Pro and ChatGPT 4o. In prospective clinical deployment, AI assistance significantly improved report quality scores, reduced interpretation time by 18.3% (P < 0.001), and was preferred by a majority of experts in 54.3% of cases. Through lightweight architecture and domain-specific optimization, Janus-Pro-CXR improves diagnostic reliability and workflow efficiency, particularly in resource-constrained settings. The model architecture and implementation framework will be open-sourced to facilitate the clinical translation of AI-assisted radiology solutions.
From Context to EDUs: Faithful and Structured Context Compression via Elementary Discourse Unit Decomposition
Dec 18, 2025Managing extensive context remains a critical bottleneck for Large Language Models (LLMs), particularly in applications like long-document question answering and autonomous agents where lengthy inputs incur high computational costs and introduce noise. Existing compression techniques often disrupt local coherence through discrete token removal or rely on implicit latent encoding that suffers from positional bias and incompatibility with closed-source APIs. To address these limitations, we introduce the EDU-based Context Compressor, a novel explicit compression framework designed to preserve both global structure and fine-grained details. Our approach reformulates context compression as a structure-then-select process. First, our LingoEDU transforms linear text into a structural relation tree of Elementary Discourse Units (EDUs) which are anchored strictly to source indices to eliminate hallucination. Second, a lightweight ranking module selects query-relevant sub-trees for linearization. To rigorously evaluate structural understanding, we release StructBench, a manually annotated dataset of 248 diverse documents. Empirical results demonstrate that our method achieves state-of-the-art structural prediction accuracy and significantly outperforms frontier LLMs while reducing costs. Furthermore, our structure-aware compression substantially enhances performance across downstream tasks ranging from long-context tasks to complex Deep Search scenarios.
From Masks to Worlds: A Hitchhiker's Guide to World Models
Oct 23, 2025This is not a typical survey of world models; it is a guide for those who want to build worlds. We do not aim to catalog every paper that has ever mentioned a ``world model". Instead, we follow one clear road: from early masked models that unified representation learning across modalities, to unified architectures that share a single paradigm, then to interactive generative models that close the action-perception loop, and finally to memory-augmented systems that sustain consistent worlds over time. We bypass loosely related branches to focus on the core: the generative heart, the interactive loop, and the memory system. We show that this is the most promising path towards true world models.