 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Spatial Implicit Neural Representation Learning for 3D MRI-Ultrasound Deformable Image Registration in HDR Prostate Brachytherapy
Mar 18, 2025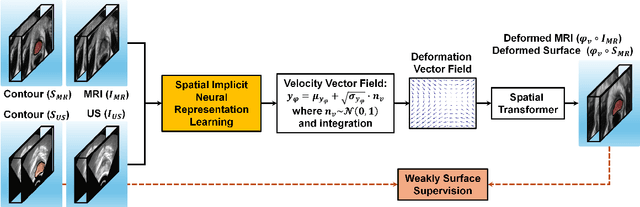



Purpose: Accurate 3D MRI-ultrasound (US) deformable registration is critical for real-time guidance in high-dose-rate (HDR) prostate brachytherapy. We present a weakly supervised spatial implicit neural representation (SINR) method to address modality differences and pelvic anatomy challenges. Methods: The framework uses sparse surface supervision from MRI/US segmentations instead of dense intensity matching. SINR models deformations as continuous spatial functions, with patient-specific surface priors guiding a stationary velocity field for biologically plausible deformations. Validation included 20 public Prostate-MRI-US-Biopsy cases and 10 institutional HDR cases, evaluated via Dice similarity coefficient (DSC), mean surface distance (MSD), and 95% Hausdorff distance (HD95). Results: The proposed method achieved robust registration. For the public dataset, prostate DSC was $0.93 \pm 0.05$, MSD $0.87 \pm 0.10$ mm, and HD95 $1.58 \pm 0.37$ mm. For the institutional dataset, prostate CTV achieved DSC $0.88 \pm 0.09$, MSD $1.21 \pm 0.38$ mm, and HD95 $2.09 \pm 1.48$ mm. Bladder and rectum performance was lower due to ultrasound's limited field of view. Visual assessments confirmed accurate alignment with minimal discrepancies. Conclusion: This study introduces a novel weakly supervised SINR-based approach for 3D MRI-US deformable registration. By leveraging sparse surface supervision and spatial priors, it achieves accurate, robust, and computationally efficient registration, enhancing real-time image guidance in HDR prostate brachytherapy and improving treatment precision.
Typhoon Intensity Prediction with Vision Transformer
Dec 04, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
Adaptive-Labeling for Enhancing Remote Sensing Cloud Understanding
Nov 09, 2023Cloud analysis is a critical component of weather and climate science, impacting various sectors like disaster management. However, achieving fine-grained cloud analysis, such as cloud segmentation, in remote sensing remains challenging due to the inherent difficulties in obtaining accurate labels, leading to significant labeling errors in training data. Existing methods often assume the availability of reliable segmentation annotations, limiting their overall performance. To address this inherent limitation, we introduce an innovative model-agnostic Cloud Adaptive-Labeling (CAL) approach, which operates iteratively to enhance the quality of training data annotations and consequently improve the performance of the learned model. Our methodology commences by training a cloud segmentation model using the original annotations. Subsequently, it introduces a trainable pixel intensity threshold for adaptively labeling the cloud training images on the fly. The newly generated labels are then employed to fine-tune the model. Extensive experiments conducted on multiple standard cloud segmentation benchmarks demonstrate the effectiveness of our approach in significantly boosting the performance of existing segmentation models. Our CAL method establishes new state-of-the-art results when compared to a wide array of existing alternatives.
Variable Augmented Network for Invertible Modality Synthesis-Fusion
Sep 02, 2021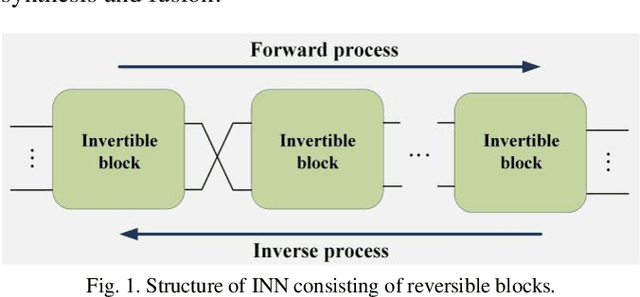



As an effective way to integrate the information contained in multiple medical images under different modalities, medical image synthesis and fusion have emerged in various clinical applications such as disease diagnosis and treatment planning. In this paper, an invertible and variable augmented network (iVAN) is proposed for medical image synthesis and fusion. In iVAN, the channel number of the network input and output is the same through variable augmentation technology, and data relevance is enhanced, which is conducive to the generation of characterization information. Meanwhile, the invertible network is used to achieve the bidirectional inference processes. Due to the invertible and variable augmentation schemes, iVAN can not only be applied to the mappings of multi-input to one-output and multi-input to multi-output, but also be applied to one-input to multi-output. Experimental results demonstrated that the proposed method can obtain competitive or superior performance in comparison to representative medical image synthesis and fusion methods.