 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTyphoon Intensity Prediction with Vision Transformer
Dec 04, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
REFUGE Challenge: A Unified Framework for Evaluating Automated Methods for Glaucoma Assessment from Fundus Photographs
Oct 08, 2019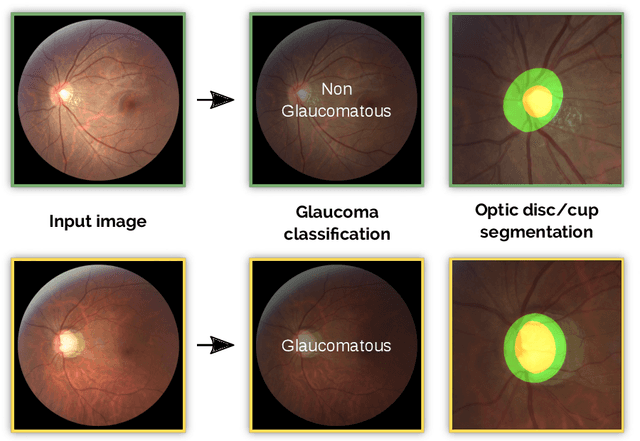
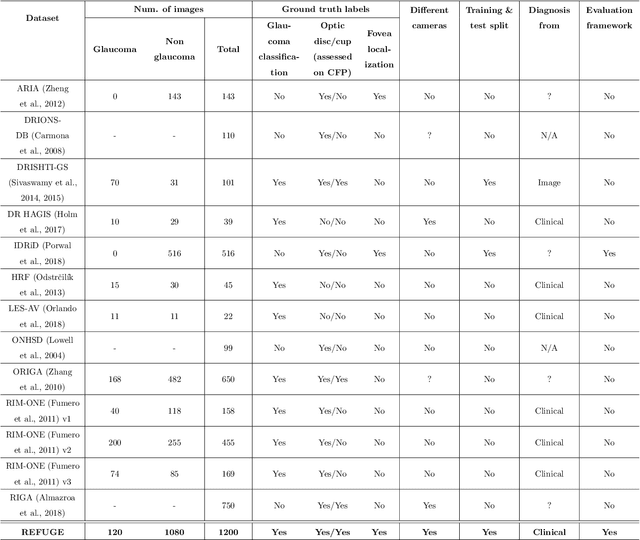

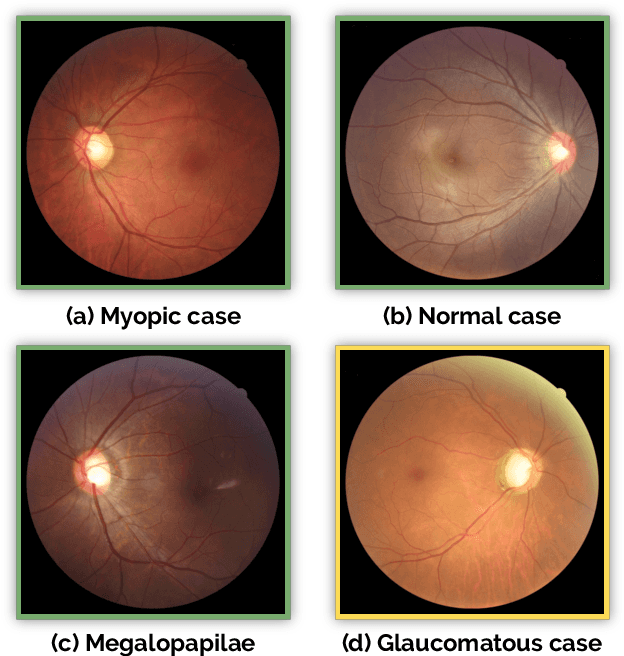
Glaucoma is one of the leading causes of irreversible but preventable blindness in working age populations. Color fundus photography (CFP) is the most cost-effective imaging modality to screen for retinal disorders. However, its application to glaucoma has been limited to the computation of a few related biomarkers such as the vertical cup-to-disc ratio. Deep learning approaches, although widely applied for medical image analysis, have not been extensively used for glaucoma assessment due to the limited size of the available data sets. Furthermore, the lack of a standardize benchmark strategy makes difficult to compare existing methods in a uniform way. In order to overcome these issues we set up the Retinal Fundus Glaucoma Challenge, REFUGE (\url{https://refuge.grand-challenge.org}), held in conjunction with MICCAI 2018. The challenge consisted of two primary tasks, namely optic disc/cup segmentation and glaucoma classification. As part of REFUGE, we have publicly released a data set of 1200 fundus images with ground truth segmentations and clinical glaucoma labels, currently the largest existing one. We have also built an evaluation framework to ease and ensure fairness in the comparison of different models, encouraging the development of novel techniques in the field. 12 teams qualified and participated in the online challenge. This paper summarizes their methods and analyzes their corresponding results. In particular, we observed that two of the top-ranked teams outperformed two human experts in the glaucoma classification task. Furthermore, the segmentation results were in general consistent with the ground truth annotations, with complementary outcomes that can be further exploited by ensembling the results.