 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Blind but Silenced: Rebalancing Vision and Language via Adversarial Counter-Commonsense Equilibrium
May 11, 2026During MLLM decoding, attention often abnormally concentrates on irrelevant image tokens. While existing research dismisses this as invalid noise and forcibly redirects attention to compel focusing on key image information, we argue these tokens are critical carriers of visual and narrative logic, and such coercive corrections exacerbate visual-language imbalance. Adopting a "decoding-as-game" perspective, we reveal that hallucinations stem from an equilibrium imbalance between linguistic priors and visual information. We propose Adversarial Counter-Commonsense Equilibrium (ACE), a training-free framework that perturbs visual context via counter-commonsense patches. Leveraging the fact that authentic visual features remain stable under perturbation while hallucinations fluctuate, ACE implements a dynamic game decoding strategy. This approach precisely suppresses perturbation-sensitive priors while compensating for stable visual signals to restore balance. Extensive experiments demonstrate that ACE, as a plug-and-play strategy, enhances model trustworthiness with negligible inference overhead.
UAV-CB: A Complex-Background RGB-T Dataset and Local Frequency Bridge Network for UAV Detection
Mar 18, 2026Detecting Unmanned Aerial Vehicles (UAVs) in low-altitude environments is essential for perception and defense systems but remains highly challenging due to complex backgrounds, camouflage, and multimodal interference. In real-world scenarios, UAVs are frequently visually blended with surrounding structures such as buildings, vegetation, and power lines, resulting in low contrast, weak boundaries, and strong confusion with cluttered background textures. Existing UAV detection datasets, though diverse, are not specifically designed to capture these camouflage and complex-background challenges, which limits progress toward robust real-world perception. To fill this gap, we construct UAV-CB, a new RGB-T UAV detection dataset deliberately curated to emphasize complex low-altitude backgrounds and camouflage characteristics. Furthermore, we propose the Local Frequency Bridge Network (LFBNet), which models features in localized frequency space to bridge both the frequency-spatial fusion gap and the cross-modality discrepancy gap in RGB-T fusion. Extensive experiments on UAV-CB and public benchmarks demonstrate that LFBNet achieves state-of-the-art detection performance and strong robustness under camouflaged and cluttered conditions, offering a frequency-aware perspective on multimodal UAV perception in real-world applications.
RoboRouter: Training-Free Policy Routing for Robotic Manipulation
Mar 12, 2026Research on robotic manipulation has developed a diverse set of policy paradigms, including vision-language-action (VLA) models, vision-action (VA) policies, and code-based compositional approaches. Concrete policies typically attain high success rates on specific task distributions but lim-ited generalization beyond it. Rather than proposing an other monolithic policy, we propose to leverage the complementary strengths of existing approaches through intelligent policy routing. We introduce RoboRouter, a training-free framework that maintains a pool of heterogeneous policies and learns to select the best-performing policy for each task through accumulated execution experience. Given a new task, RoboRouter constructs a semantic task representation, retrieves historical records of similar tasks, predicts the optimal policy choice without requiring trial-and-error, and incorporates structured feedback to refine subsequent routing decisions. Integrating a new policy into the system requires only lightweight evaluation and incurs no training overhead. Across simulation benchmark and real-world evaluations, RoboRouter consistently outperforms than in-dividual policies, improving average success rate by more than 3% in simulation and over 13% in real-world settings, while preserving execution efficiency. Our results demonstrate that intelligent routing across heterogeneous, off-the-shelf policies provides a practical and scalable pathway toward building more capable robotic systems.
T-Rex: Task-Adaptive Spatial Representation Extraction for Robotic Manipulation with Vision-Language Models
Jun 24, 2025Building a general robotic manipulation system capable of performing a wide variety of tasks in real-world settings is a challenging task. Vision-Language Models (VLMs) have demonstrated remarkable potential in robotic manipulation tasks, primarily due to the extensive world knowledge they gain from large-scale datasets. In this process, Spatial Representations (such as points representing object positions or vectors representing object orientations) act as a bridge between VLMs and real-world scene, effectively grounding the reasoning abilities of VLMs and applying them to specific task scenarios. However, existing VLM-based robotic approaches often adopt a fixed spatial representation extraction scheme for various tasks, resulting in insufficient representational capability or excessive extraction time. In this work, we introduce T-Rex, a Task-Adaptive Framework for Spatial Representation Extraction, which dynamically selects the most appropriate spatial representation extraction scheme for each entity based on specific task requirements. Our key insight is that task complexity determines the types and granularity of spatial representations, and Stronger representational capabilities are typically associated with Higher overall system operation costs. Through comprehensive experiments in real-world robotic environments, we show that our approach delivers significant advantages in spatial understanding, efficiency, and stability without additional training.
AntiGrounding: Lifting Robotic Actions into VLM Representation Space for Decision Making
Jun 14, 2025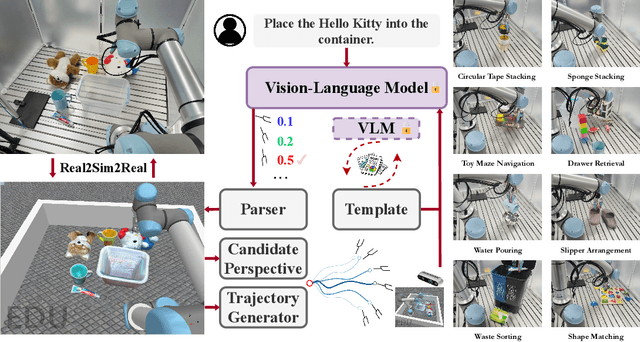
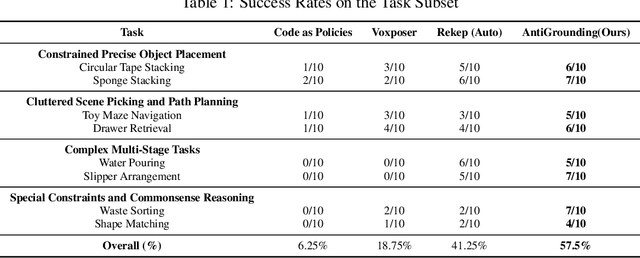
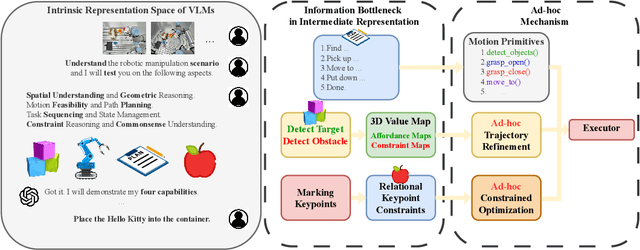

Vision-Language Models (VLMs) encode knowledge and reasoning capabilities for robotic manipulation within high-dimensional representation spaces. However, current approaches often project them into compressed intermediate representations, discarding important task-specific information such as fine-grained spatial or semantic details. To address this, we propose AntiGrounding, a new framework that reverses the instruction grounding process. It lifts candidate actions directly into the VLM representation space, renders trajectories from multiple views, and uses structured visual question answering for instruction-based decision making. This enables zero-shot synthesis of optimal closed-loop robot trajectories for new tasks. We also propose an offline policy refinement module that leverages past experience to enhance long-term performance. Experiments in both simulation and real-world environments show that our method outperforms baselines across diverse robotic manipulation tasks.
Inverse Materials Design by Large Language Model-Assisted Generative Framework
Feb 25, 2025Deep generative models hold great promise for inverse materials design, yet their efficiency and accuracy remain constrained by data scarcity and model architecture. Here, we introduce AlloyGAN, a closed-loop framework that integrates Large Language Model (LLM)-assisted text mining with Conditional Generative Adversarial Networks (CGANs) to enhance data diversity and improve inverse design. Taking alloy discovery as a case study, AlloyGAN systematically refines material candidates through iterative screening and experimental validation. For metallic glasses, the framework predicts thermodynamic properties with discrepancies of less than 8% from experiments, demonstrating its robustness. By bridging generative AI with domain knowledge and validation workflows, AlloyGAN offers a scalable approach to accelerate the discovery of materials with tailored properties, paving the way for broader applications in materials science.
IPVTON: Image-based 3D Virtual Try-on with Image Prompt Adapter
Jan 26, 2025
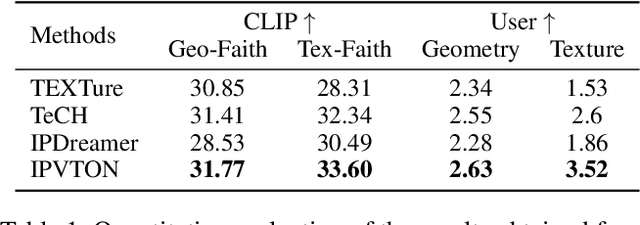
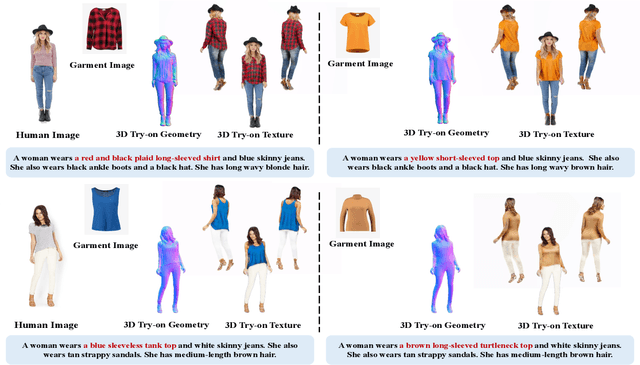
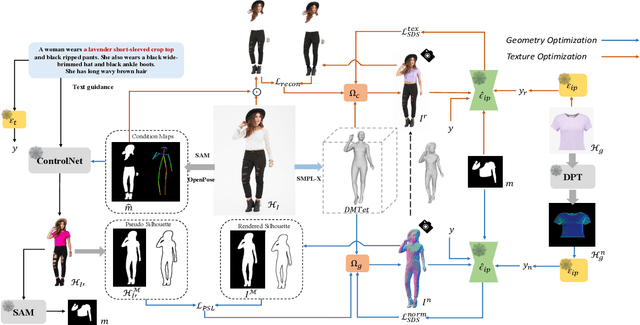
Given a pair of images depicting a person and a garment separately, image-based 3D virtual try-on methods aim to reconstruct a 3D human model that realistically portrays the person wearing the desired garment. In this paper, we present IPVTON, a novel image-based 3D virtual try-on framework. IPVTON employs score distillation sampling with image prompts to optimize a hybrid 3D human representation, integrating target garment features into diffusion priors through an image prompt adapter. To avoid interference with non-target areas, we leverage mask-guided image prompt embeddings to focus the image features on the try-on regions. Moreover, we impose geometric constraints on the 3D model with a pseudo silhouette generated by ControlNet, ensuring that the clothed 3D human model retains the shape of the source identity while accurately wearing the target garments. Extensive qualitative and quantitative experiments demonstrate that IPVTON outperforms previous methods in image-based 3D virtual try-on tasks, excelling in both geometry and texture.
Hybrid Classification-Regression Adaptive Loss for Dense Object Detection
Aug 30, 2024



For object detection detectors, enhancing model performance hinges on the ability to simultaneously consider inconsistencies across tasks and focus on difficult-to-train samples. Achieving this necessitates incorporating information from both the classification and regression tasks. However, prior work tends to either emphasize difficult-to-train samples within their respective tasks or simply compute classification scores with IoU, often leading to suboptimal model performance. In this paper, we propose a Hybrid Classification-Regression Adaptive Loss, termed as HCRAL. Specifically, we introduce the Residual of Classification and IoU (RCI) module for cross-task supervision, addressing task inconsistencies, and the Conditioning Factor (CF) to focus on difficult-to-train samples within each task. Furthermore, we introduce a new strategy named Expanded Adaptive Training Sample Selection (EATSS) to provide additional samples that exhibit classification and regression inconsistencies. To validate the effectiveness of the proposed method, we conduct extensive experiments on COCO test-dev. Experimental evaluations demonstrate the superiority of our approachs. Additionally, we designed experiments by separately combining the classification and regression loss with regular loss functions in popular one-stage models, demonstrating improved performance.
DeCo: Decoupled Human-Centered Diffusion Video Editing with Motion Consistency
Aug 14, 2024
Diffusion models usher a new era of video editing, flexibly manipulating the video contents with text prompts. Despite the widespread application demand in editing human-centered videos, these models face significant challenges in handling complex objects like humans. In this paper, we introduce DeCo, a novel video editing framework specifically designed to treat humans and the background as separate editable targets, ensuring global spatial-temporal consistency by maintaining the coherence of each individual component. Specifically, we propose a decoupled dynamic human representation that utilizes a parametric human body prior to generate tailored humans while preserving the consistent motions as the original video. In addition, we consider the background as a layered atlas to apply text-guided image editing approaches on it. To further enhance the geometry and texture of humans during the optimization, we extend the calculation of score distillation sampling into normal space and image space. Moreover, we tackle inconsistent lighting between the edited targets by leveraging a lighting-aware video harmonizer, a problem previously overlooked in decompose-edit-combine approaches. Extensive qualitative and numerical experiments demonstrate that DeCo outperforms prior video editing methods in human-centered videos, especially in longer videos.
Spatial-Semantic Collaborative Cropping for User Generated Content
Jan 16, 2024A large amount of User Generated Content (UGC) is uploaded to the Internet daily and displayed to people world-widely through the client side (e.g., mobile and PC). This requires the cropping algorithms to produce the aesthetic thumbnail within a specific aspect ratio on different devices. However, existing image cropping works mainly focus on landmark or landscape images, which fail to model the relations among the multi-objects with the complex background in UGC. Besides, previous methods merely consider the aesthetics of the cropped images while ignoring the content integrity, which is crucial for UGC cropping. In this paper, we propose a Spatial-Semantic Collaborative cropping network (S2CNet) for arbitrary user generated content accompanied by a new cropping benchmark. Specifically, we first mine the visual genes of the potential objects. Then, the suggested adaptive attention graph recasts this task as a procedure of information association over visual nodes. The underlying spatial and semantic relations are ultimately centralized to the crop candidate through differentiable message passing, which helps our network efficiently to preserve both the aesthetics and the content integrity. Extensive experiments on the proposed UGCrop5K and other public datasets demonstrate the superiority of our approach over state-of-the-art counterparts. Our project is available at https://github.com/suyukun666/S2CNet.