 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXUAT-Copilot: Multi-Agent Collaborative System for Automated User Acceptance Testing with Large Language Model
Jan 10, 2024In past years, we have been dedicated to automating user acceptance testing (UAT) process of WeChat Pay, one of the most influential mobile payment applications in China. A system titled XUAT has been developed for this purpose. However, there is still a human-labor-intensive stage, i.e, test scripts generation, in the current system. Therefore, in this paper, we concentrate on methods of boosting the automation level of the current system, particularly the stage of test scripts generation. With recent notable successes, large language models (LLMs) demonstrate significant potential in attaining human-like intelligence and there has been a growing research area that employs LLMs as autonomous agents to obtain human-like decision-making capabilities. Inspired by these works, we propose an LLM-powered multi-agent collaborative system, named XUAT-Copilot, for automated UAT. The proposed system mainly consists of three LLM-based agents responsible for action planning, state checking and parameter selecting, respectively, and two additional modules for state sensing and case rewriting. The agents interact with testing device, make human-like decision and generate action command in a collaborative way. The proposed multi-agent system achieves a close effectiveness to human testers in our experimental studies and gains a significant improvement of Pass@1 accuracy compared with single-agent architecture. More importantly, the proposed system has launched in the formal testing environment of WeChat Pay mobile app, which saves a considerable amount of manpower in the daily development work.
Variance-insensitive and Target-preserving Mask Refinement for Interactive Image Segmentation
Dec 22, 2023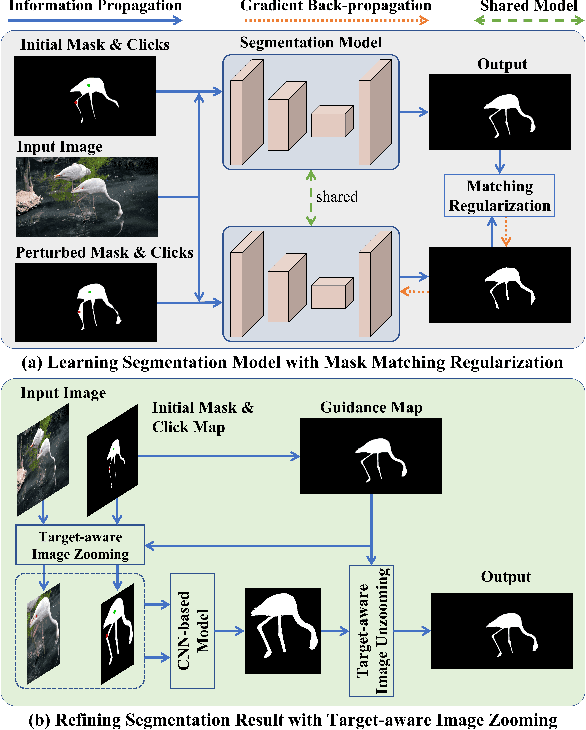
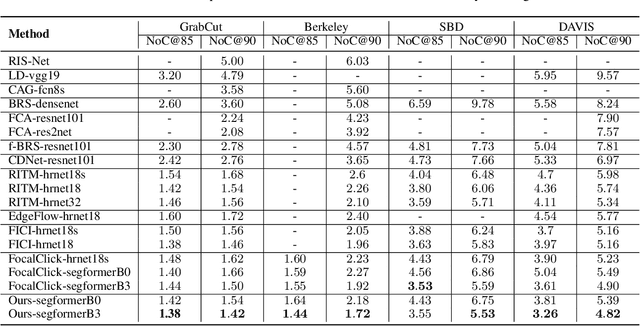

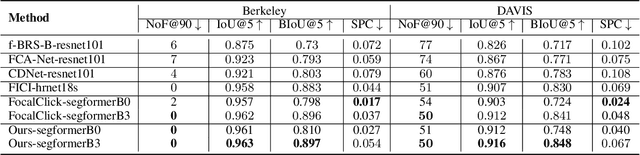
Point-based interactive image segmentation can ease the burden of mask annotation in applications such as semantic segmentation and image editing. However, fully extracting the target mask with limited user inputs remains challenging. We introduce a novel method, Variance-Insensitive and Target-Preserving Mask Refinement to enhance segmentation quality with fewer user inputs. Regarding the last segmentation result as the initial mask, an iterative refinement process is commonly employed to continually enhance the initial mask. Nevertheless, conventional techniques suffer from sensitivity to the variance in the initial mask. To circumvent this problem, our proposed method incorporates a mask matching algorithm for ensuring consistent inferences from different types of initial masks. We also introduce a target-aware zooming algorithm to preserve object information during downsampling, balancing efficiency and accuracy. Experiments on GrabCut, Berkeley, SBD, and DAVIS datasets demonstrate our method's state-of-the-art performance in interactive image segmentation.
Retrieval-Augmented Meta Learning for Low-Resource Text Classification
Sep 10, 2023Meta learning have achieved promising performance in low-resource text classification which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. However, due to the limited training data in the meta-learning scenario and the inherent properties of parameterized neural networks, poor generalization performance has become a pressing problem that needs to be addressed. To deal with this issue, we propose a meta-learning based method called Retrieval-Augmented Meta Learning(RAML). It not only uses parameterization for inference but also retrieves non-parametric knowledge from an external corpus to make inferences, which greatly alleviates the problem of poor generalization performance caused by the lack of diverse training data in meta-learning. This method differs from previous models that solely rely on parameters, as it explicitly emphasizes the importance of non-parametric knowledge, aiming to strike a balance between parameterized neural networks and non-parametric knowledge. The model is required to determine which knowledge to access and utilize during inference. Additionally, our multi-view passages fusion network module can effectively and efficiently integrate the retrieved information into low-resource classification task. The extensive experiments demonstrate that RAML significantly outperforms current SOTA low-resource text classification models.
Prompt Learning With Knowledge Memorizing Prototypes For Generalized Few-Shot Intent Detection
Sep 10, 2023Generalized Few-Shot Intent Detection (GFSID) is challenging and realistic because it needs to categorize both seen and novel intents simultaneously. Previous GFSID methods rely on the episodic learning paradigm, which makes it hard to extend to a generalized setup as they do not explicitly learn the classification of seen categories and the knowledge of seen intents. To address the dilemma, we propose to convert the GFSID task into the class incremental learning paradigm. Specifically, we propose a two-stage learning framework, which sequentially learns the knowledge of different intents in various periods via prompt learning. And then we exploit prototypes for categorizing both seen and novel intents. Furthermore, to achieve the transfer knowledge of intents in different stages, for different scenarios we design two knowledge preservation methods which close to realistic applications. Extensive experiments and detailed analyses on two widely used datasets show that our framework based on the class incremental learning paradigm achieves promising performance.
WMFormer++: Nested Transformer for Visible Watermark Removal via Implict Joint Learning
Aug 22, 2023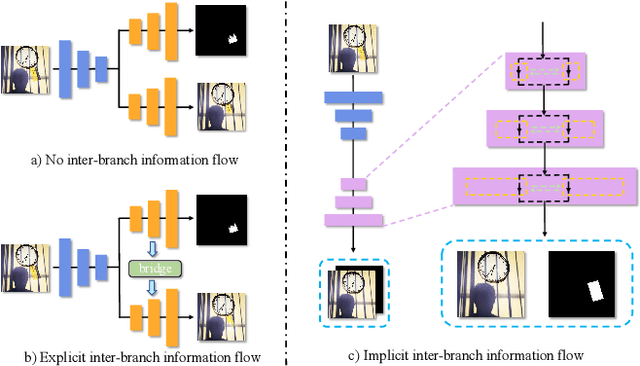
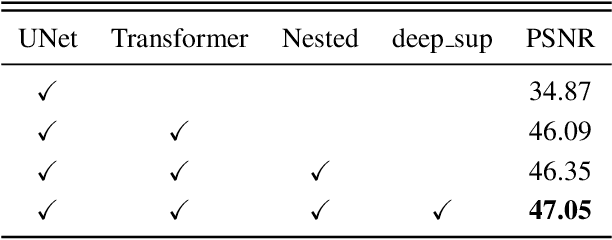
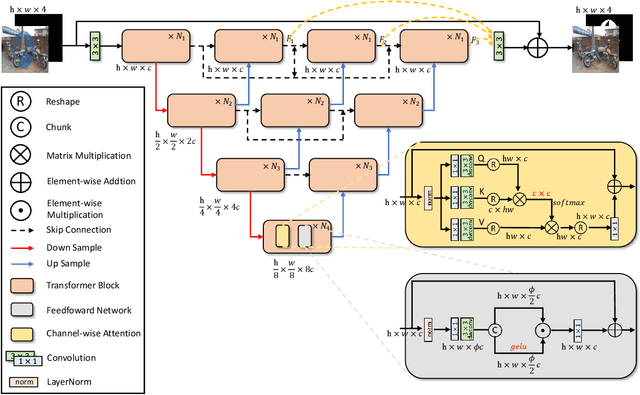
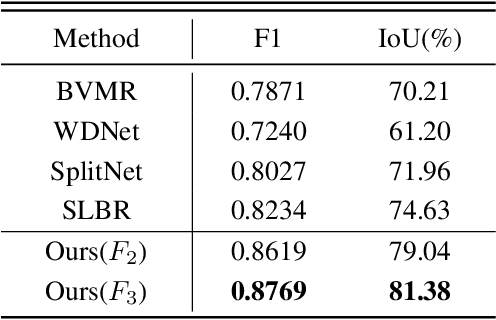
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches--one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach's remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Partial Information as Full: Reward Imputation with Sketching in Bandits
Oct 20, 2022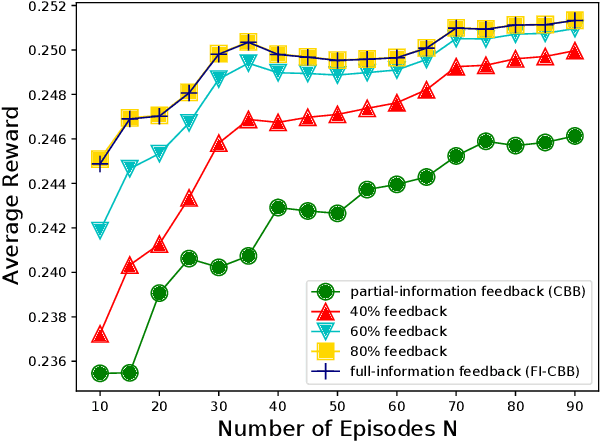

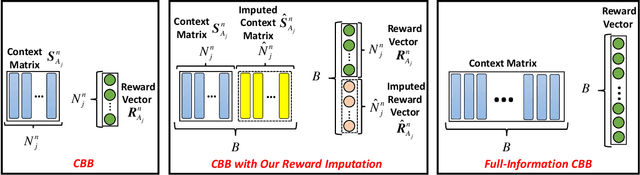
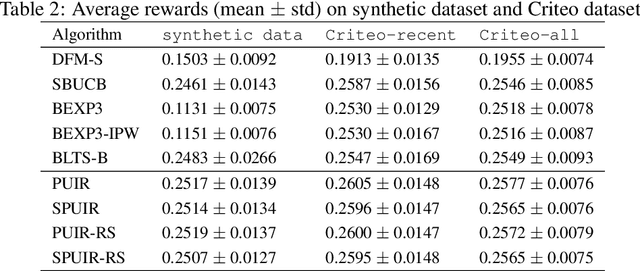
We focus on the setting of contextual batched bandit (CBB), where a batch of rewards is observed from the environment in each episode. But the rewards of the non-executed actions are unobserved (i.e., partial-information feedbacks). Existing approaches for CBB usually ignore the rewards of the non-executed actions, resulting in feedback information being underutilized. In this paper, we propose an efficient reward imputation approach using sketching for CBB, which completes the unobserved rewards with the imputed rewards approximating the full-information feedbacks. Specifically, we formulate the reward imputation as a problem of imputation regularized ridge regression, which captures the feedback mechanisms of both the non-executed and executed actions. To reduce the time complexity of reward imputation, we solve the regression problem using randomized sketching. We prove that our reward imputation approach obtains a relative-error bound for sketching approximation, achieves an instantaneous regret with a controllable bias and a smaller variance than that without reward imputation, and enjoys a sublinear regret bound against the optimal policy. Moreover, we present two extensions of our approach, including the rate-scheduled version and the version for nonlinear rewards, making our approach more feasible. Experimental results demonstrated that our approach can outperform the state-of-the-art baselines on synthetic and real-world datasets.
Pairwise Learning for Neural Link Prediction
Dec 22, 2021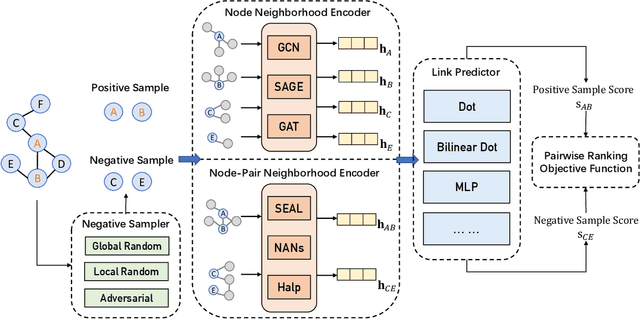

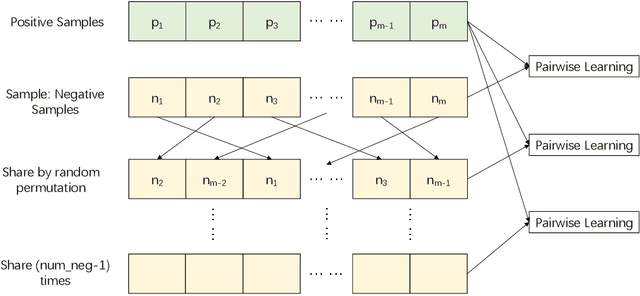
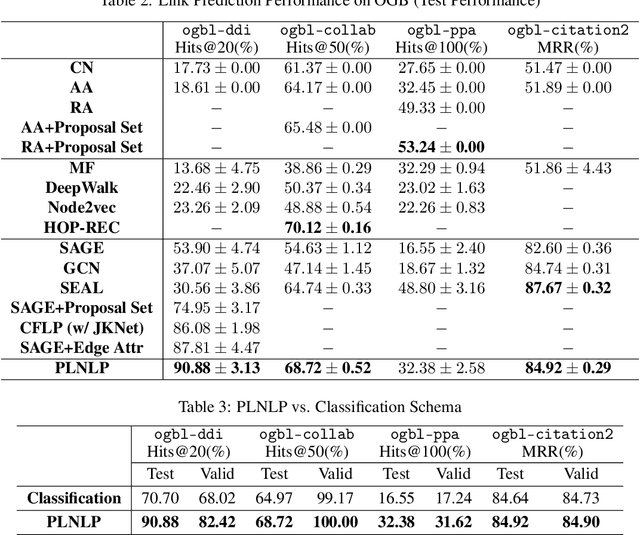
In this paper, we aim at providing an effective Pairwise Learning Neural Link Prediction (PLNLP) framework. The framework treats link prediction as a pairwise learning to rank problem and consists of four main components, i.e., neighborhood encoder, link predictor, negative sampler and objective function. The framework is flexible that any generic graph neural convolution or link prediction specific neural architecture could be employed as neighborhood encoder. For link predictor, we design different scoring functions, which could be selected based on different types of graphs. In negative sampler, we provide several sampling strategies, which are problem specific. As for objective function, we propose to use an effective ranking loss, which approximately maximizes the standard ranking metric AUC. We evaluate the proposed PLNLP framework on 4 link property prediction datasets of Open Graph Benchmark, including ogbl-ddi, ogbl-collab, ogbl-ppa and ogbl-ciation2. PLNLP achieves top 1 performance on ogbl-ddi and ogbl-collab, and top 2 performance on ogbl-ciation2 only with basic neural architecture. The performance demonstrates the effectiveness of PLNLP.