 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAD-Bench: A Comprehensive Benchmark for Embedding-Based Text Anomaly Detection
Jan 21, 2025



Text anomaly detection is crucial for identifying spam, misinformation, and offensive language in natural language processing tasks. Despite the growing adoption of embedding-based methods, their effectiveness and generalizability across diverse application scenarios remain under-explored. To address this, we present TAD-Bench, a comprehensive benchmark designed to systematically evaluate embedding-based approaches for text anomaly detection. TAD-Bench integrates multiple datasets spanning different domains, combining state-of-the-art embeddings from large language models with a variety of anomaly detection algorithms. Through extensive experiments, we analyze the interplay between embeddings and detection methods, uncovering their strengths, weaknesses, and applicability to different tasks. These findings offer new perspectives on building more robust, efficient, and generalizable anomaly detection systems for real-world applications.
Curriculum-style Data Augmentation for LLM-based Metaphor Detection
Dec 04, 2024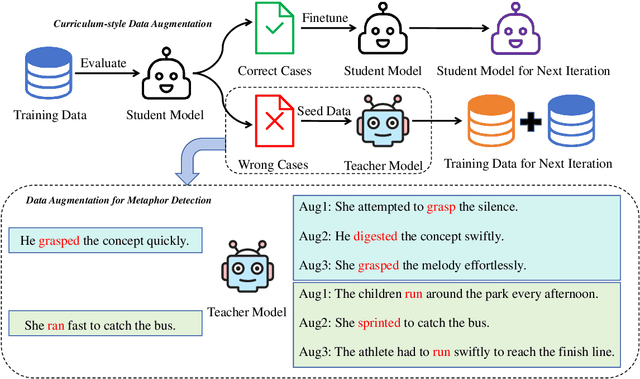

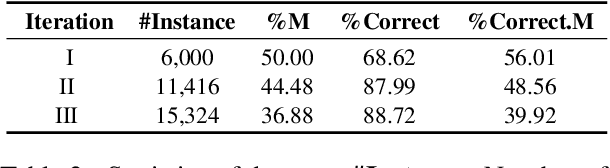
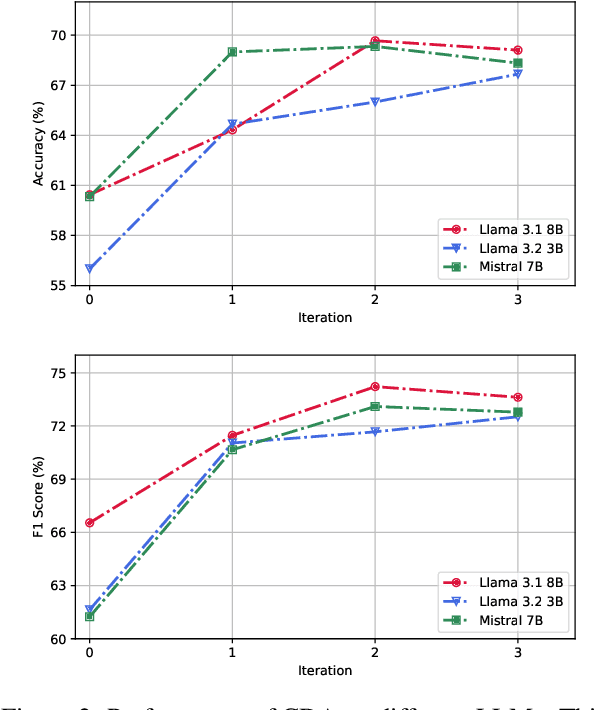
Recently, utilizing large language models (LLMs) for metaphor detection has achieved promising results. However, these methods heavily rely on the capabilities of closed-source LLMs, which come with relatively high inference costs and latency. To address this, we propose a method for metaphor detection by fine-tuning open-source LLMs, effectively reducing inference costs and latency with a single inference step. Furthermore, metaphor detection suffers from a severe data scarcity problem, which hinders effective fine-tuning of LLMs. To tackle this, we introduce Curriculum-style Data Augmentation (CDA). Specifically, before fine-tuning, we evaluate the training data to identify correctly predicted instances for fine-tuning, while incorrectly predicted instances are used as seed data for data augmentation. This approach enables the model to quickly learn simpler knowledge and progressively acquire more complex knowledge, thereby improving performance incrementally. Experimental results demonstrate that our method achieves state-of-the-art performance across all baselines. Additionally, we provide detailed ablation studies to validate the effectiveness of CDA.
Enhancing Metaphor Detection through Soft Labels and Target Word Prediction
Apr 09, 2024



Metaphors play a significant role in our everyday communication, yet detecting them presents a challenge. Traditional methods often struggle with improper application of language rules and a tendency to overlook data sparsity. To address these issues, we integrate knowledge distillation and prompt learning into metaphor detection. Our approach revolves around a tailored prompt learning framework specifically designed for metaphor detection. By strategically masking target words and providing relevant prompt data, we guide the model to accurately predict the contextual meanings of these words. This approach not only mitigates confusion stemming from the literal meanings of the words but also ensures effective application of language rules for metaphor detection. Furthermore, we've introduced a teacher model to generate valuable soft labels. These soft labels provide a similar effect to label smoothing and help prevent the model from becoming over confident and effectively addresses the challenge of data sparsity. Experimental results demonstrate that our model has achieved state-of-the-art performance, as evidenced by its remarkable results across various datasets.
Towards Compact 3D Representations via Point Feature Enhancement Masked Autoencoders
Dec 17, 2023Learning 3D representation plays a critical role in masked autoencoder (MAE) based pre-training methods for point cloud, including single-modal and cross-modal based MAE. Specifically, although cross-modal MAE methods learn strong 3D representations via the auxiliary of other modal knowledge, they often suffer from heavy computational burdens and heavily rely on massive cross-modal data pairs that are often unavailable, which hinders their applications in practice. Instead, single-modal methods with solely point clouds as input are preferred in real applications due to their simplicity and efficiency. However, such methods easily suffer from limited 3D representations with global random mask input. To learn compact 3D representations, we propose a simple yet effective Point Feature Enhancement Masked Autoencoders (Point-FEMAE), which mainly consists of a global branch and a local branch to capture latent semantic features. Specifically, to learn more compact features, a share-parameter Transformer encoder is introduced to extract point features from the global and local unmasked patches obtained by global random and local block mask strategies, followed by a specific decoder to reconstruct. Meanwhile, to further enhance features in the local branch, we propose a Local Enhancement Module with local patch convolution to perceive fine-grained local context at larger scales. Our method significantly improves the pre-training efficiency compared to cross-modal alternatives, and extensive downstream experiments underscore the state-of-the-art effectiveness, particularly outperforming our baseline (Point-MAE) by 5.16%, 5.00%, and 5.04% in three variants of ScanObjectNN, respectively. The code is available at https://github.com/zyh16143998882/AAAI24-PointFEMAE.
Retrieval-Augmented Meta Learning for Low-Resource Text Classification
Sep 10, 2023Meta learning have achieved promising performance in low-resource text classification which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. However, due to the limited training data in the meta-learning scenario and the inherent properties of parameterized neural networks, poor generalization performance has become a pressing problem that needs to be addressed. To deal with this issue, we propose a meta-learning based method called Retrieval-Augmented Meta Learning(RAML). It not only uses parameterization for inference but also retrieves non-parametric knowledge from an external corpus to make inferences, which greatly alleviates the problem of poor generalization performance caused by the lack of diverse training data in meta-learning. This method differs from previous models that solely rely on parameters, as it explicitly emphasizes the importance of non-parametric knowledge, aiming to strike a balance between parameterized neural networks and non-parametric knowledge. The model is required to determine which knowledge to access and utilize during inference. Additionally, our multi-view passages fusion network module can effectively and efficiently integrate the retrieved information into low-resource classification task. The extensive experiments demonstrate that RAML significantly outperforms current SOTA low-resource text classification models.
Prompt Learning With Knowledge Memorizing Prototypes For Generalized Few-Shot Intent Detection
Sep 10, 2023Generalized Few-Shot Intent Detection (GFSID) is challenging and realistic because it needs to categorize both seen and novel intents simultaneously. Previous GFSID methods rely on the episodic learning paradigm, which makes it hard to extend to a generalized setup as they do not explicitly learn the classification of seen categories and the knowledge of seen intents. To address the dilemma, we propose to convert the GFSID task into the class incremental learning paradigm. Specifically, we propose a two-stage learning framework, which sequentially learns the knowledge of different intents in various periods via prompt learning. And then we exploit prototypes for categorizing both seen and novel intents. Furthermore, to achieve the transfer knowledge of intents in different stages, for different scenarios we design two knowledge preservation methods which close to realistic applications. Extensive experiments and detailed analyses on two widely used datasets show that our framework based on the class incremental learning paradigm achieves promising performance.