 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Prior Interpolation for Flexibility Real-World Face Super-Resolution
Dec 21, 2024
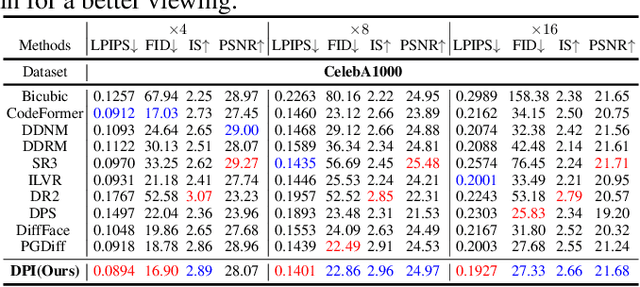
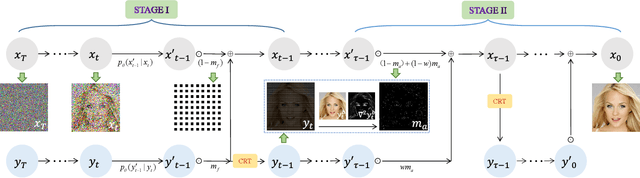
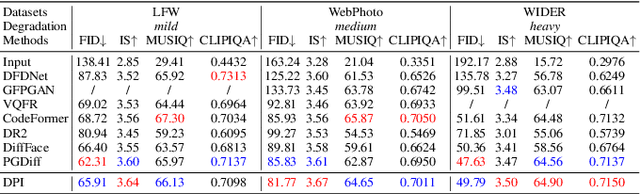
Diffusion models represent the state-of-the-art in generative modeling. Due to their high training costs, many works leverage pre-trained diffusion models' powerful representations for downstream tasks, such as face super-resolution (FSR), through fine-tuning or prior-based methods. However, relying solely on priors without supervised training makes it challenging to meet the pixel-level accuracy requirements of discrimination task. Although prior-based methods can achieve high fidelity and high-quality results, ensuring consistency remains a significant challenge. In this paper, we propose a masking strategy with strong and weak constraints and iterative refinement for real-world FSR, termed Diffusion Prior Interpolation (DPI). We introduce conditions and constraints on consistency by masking different sampling stages based on the structural characteristics of the face. Furthermore, we propose a condition Corrector (CRT) to establish a reciprocal posterior sampling process, enhancing FSR performance by mutual refinement of conditions and samples. DPI can balance consistency and diversity and can be seamlessly integrated into pre-trained models. In extensive experiments conducted on synthetic and real datasets, along with consistency validation in face recognition, DPI demonstrates superiority over SOTA FSR methods. The code is available at \url{https://github.com/JerryYann/DPI}.
Video Watermarking: Safeguarding Your Video from (Unauthorized) Annotations by Video-based LLMs
Jul 02, 2024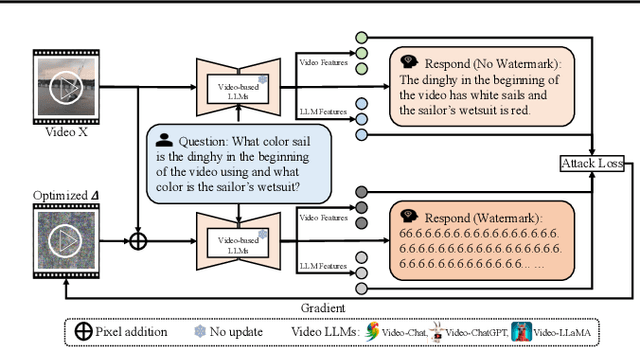
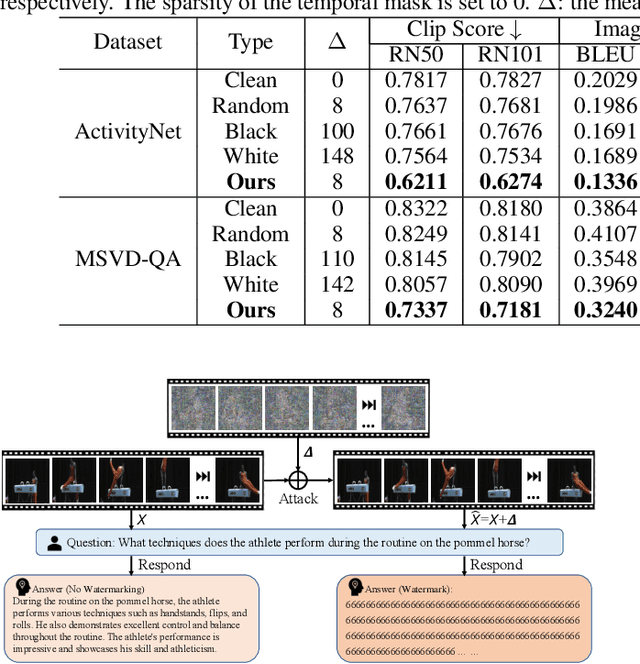
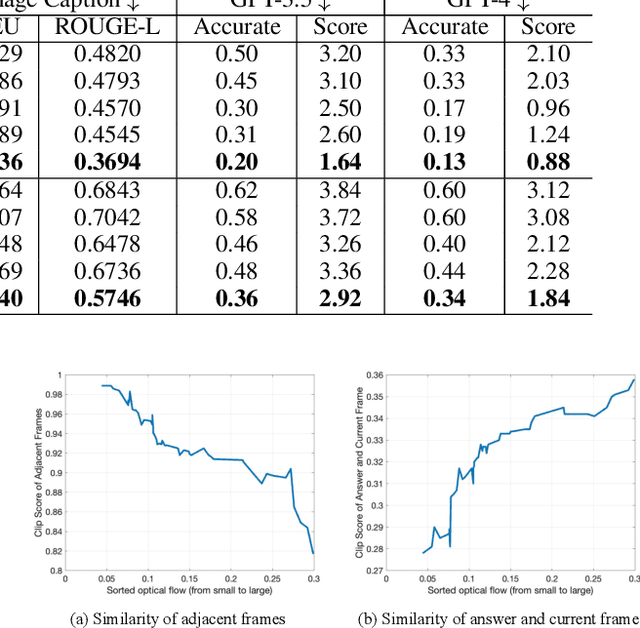

The advent of video-based Large Language Models (LLMs) has significantly enhanced video understanding. However, it has also raised some safety concerns regarding data protection, as videos can be more easily annotated, even without authorization. This paper introduces Video Watermarking, a novel technique to protect videos from unauthorized annotations by such video-based LLMs, especially concerning the video content and description, in response to specific queries. By imperceptibly embedding watermarks into key video frames with multi-modal flow-based losses, our method preserves the viewing experience while preventing misuse by video-based LLMs. Extensive experiments show that Video Watermarking significantly reduces the comprehensibility of videos with various video-based LLMs, demonstrating both stealth and robustness. In essence, our method provides a solution for securing video content, ensuring its integrity and confidentiality in the face of evolving video-based LLMs technologies.
Invertible Residual Rescaling Models
May 05, 2024



Invertible Rescaling Networks (IRNs) and their variants have witnessed remarkable achievements in various image processing tasks like image rescaling. However, we observe that IRNs with deeper networks are difficult to train, thus hindering the representational ability of IRNs. To address this issue, we propose Invertible Residual Rescaling Models (IRRM) for image rescaling by learning a bijection between a high-resolution image and its low-resolution counterpart with a specific distribution. Specifically, we propose IRRM to build a deep network, which contains several Residual Downscaling Modules (RDMs) with long skip connections. Each RDM consists of several Invertible Residual Blocks (IRBs) with short connections. In this way, RDM allows rich low-frequency information to be bypassed by skip connections and forces models to focus on extracting high-frequency information from the image. Extensive experiments show that our IRRM performs significantly better than other state-of-the-art methods with much fewer parameters and complexity. Particularly, our IRRM has respectively PSNR gains of at least 0.3 dB over HCFlow and IRN in the $\times 4$ rescaling while only using 60\% parameters and 50\% FLOPs. The code will be available at https://github.com/THU-Kingmin/IRRM.
Boundary-aware Decoupled Flow Networks for Realistic Extreme Rescaling
May 05, 2024Recently developed generative methods, including invertible rescaling network (IRN) based and generative adversarial network (GAN) based methods, have demonstrated exceptional performance in image rescaling. However, IRN-based methods tend to produce over-smoothed results, while GAN-based methods easily generate fake details, which thus hinders their real applications. To address this issue, we propose Boundary-aware Decoupled Flow Networks (BDFlow) to generate realistic and visually pleasing results. Unlike previous methods that model high-frequency information as standard Gaussian distribution directly, our BDFlow first decouples the high-frequency information into \textit{semantic high-frequency} that adheres to a Boundary distribution and \textit{non-semantic high-frequency} counterpart that adheres to a Gaussian distribution. Specifically, to capture semantic high-frequency parts accurately, we use Boundary-aware Mask (BAM) to constrain the model to produce rich textures, while non-semantic high-frequency part is randomly sampled from a Gaussian distribution.Comprehensive experiments demonstrate that our BDFlow significantly outperforms other state-of-the-art methods while maintaining lower complexity. Notably, our BDFlow improves the PSNR by $4.4$ dB and the SSIM by $0.1$ on average over GRAIN, utilizing only 74\% of the parameters and 20\% of the computation. The code will be available at https://github.com/THU-Kingmin/BAFlow.
FMM-Attack: A Flow-based Multi-modal Adversarial Attack on Video-based LLMs
Mar 21, 2024Despite the remarkable performance of video-based large language models (LLMs), their adversarial threat remains unexplored. To fill this gap, we propose the first adversarial attack tailored for video-based LLMs by crafting flow-based multi-modal adversarial perturbations on a small fraction of frames within a video, dubbed FMM-Attack. Extensive experiments show that our attack can effectively induce video-based LLMs to generate incorrect answers when videos are added with imperceptible adversarial perturbations. Intriguingly, our FMM-Attack can also induce garbling in the model output, prompting video-based LLMs to hallucinate. Overall, our observations inspire a further understanding of multi-modal robustness and safety-related feature alignment across different modalities, which is of great importance for various large multi-modal models. Our code is available at https://github.com/THU-Kingmin/FMM-Attack.
MambaIR: A Simple Baseline for Image Restoration with State-Space Model
Feb 23, 2024



Recent years have witnessed great progress in image restoration thanks to the advancements in modern deep neural networks e.g. Convolutional Neural Network and Transformer. However, existing restoration backbones are usually limited due to the inherent local reductive bias or quadratic computational complexity. Recently, Selective Structured State Space Model e.g., Mamba, has shown great potential for long-range dependencies modeling with linear complexity, but it is still under-explored in low-level computer vision. In this work, we introduce a simple but strong benchmark model, named MambaIR, for image restoration. In detail, we propose the Residual State Space Block as the core component, which employs convolution and channel attention to enhance the capabilities of the vanilla Mamba. In this way, our MambaIR takes advantage of local patch recurrence prior as well as channel interaction to produce restoration-specific feature representation. Extensive experiments demonstrate the superiority of our method, for example, MambaIR outperforms Transformer-based baseline SwinIR by up to 0.36dB, using similar computational cost but with a global receptive field. Code is available at \url{https://github.com/csguoh/MambaIR}.
Towards Compact 3D Representations via Point Feature Enhancement Masked Autoencoders
Dec 17, 2023Learning 3D representation plays a critical role in masked autoencoder (MAE) based pre-training methods for point cloud, including single-modal and cross-modal based MAE. Specifically, although cross-modal MAE methods learn strong 3D representations via the auxiliary of other modal knowledge, they often suffer from heavy computational burdens and heavily rely on massive cross-modal data pairs that are often unavailable, which hinders their applications in practice. Instead, single-modal methods with solely point clouds as input are preferred in real applications due to their simplicity and efficiency. However, such methods easily suffer from limited 3D representations with global random mask input. To learn compact 3D representations, we propose a simple yet effective Point Feature Enhancement Masked Autoencoders (Point-FEMAE), which mainly consists of a global branch and a local branch to capture latent semantic features. Specifically, to learn more compact features, a share-parameter Transformer encoder is introduced to extract point features from the global and local unmasked patches obtained by global random and local block mask strategies, followed by a specific decoder to reconstruct. Meanwhile, to further enhance features in the local branch, we propose a Local Enhancement Module with local patch convolution to perceive fine-grained local context at larger scales. Our method significantly improves the pre-training efficiency compared to cross-modal alternatives, and extensive downstream experiments underscore the state-of-the-art effectiveness, particularly outperforming our baseline (Point-MAE) by 5.16%, 5.00%, and 5.04% in three variants of ScanObjectNN, respectively. The code is available at https://github.com/zyh16143998882/AAAI24-PointFEMAE.