 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP Loss: Channel-wise Perceptual Loss for Time Series Forecasting
Jan 25, 2026Multi-channel time-series data, prevalent across diverse applications, is characterized by significant heterogeneity in its different channels. However, existing forecasting models are typically guided by channel-agnostic loss functions like MSE, which apply a uniform metric across all channels. This often leads to fail to capture channel-specific dynamics such as sharp fluctuations or trend shifts. To address this, we propose a Channel-wise Perceptual Loss (CP Loss). Its core idea is to learn a unique perceptual space for each channel that is adapted to its characteristics, and to compute the loss within this space. Specifically, we first design a learnable channel-wise filter that decomposes the raw signal into disentangled multi-scale representations, which form the basis of our perceptual space. Crucially, the filter is optimized jointly with the main forecasting model, ensuring that the learned perceptual space is explicitly oriented towards the prediction task. Finally, losses are calculated within these perception spaces to optimize the model. Code is available at https://github.com/zyh16143998882/CP_Loss.
CASL: Curvature-Augmented Self-supervised Learning for 3D Anomaly Detection
Nov 17, 2025Deep learning-based 3D anomaly detection methods have demonstrated significant potential in industrial manufacturing. However, many approaches are specifically designed for anomaly detection tasks, which limits their generalizability to other 3D understanding tasks. In contrast, self-supervised point cloud models aim for general-purpose representation learning, yet our investigation reveals that these classical models are suboptimal at anomaly detection under the unified fine-tuning paradigm. This motivates us to develop a more generalizable 3D model that can effectively detect anomalies without relying on task-specific designs. Interestingly, we find that using only the curvature of each point as its anomaly score already outperforms several classical self-supervised and dedicated anomaly detection models, highlighting the critical role of curvature in 3D anomaly detection. In this paper, we propose a Curvature-Augmented Self-supervised Learning (CASL) framework based on a reconstruction paradigm. Built upon the classical U-Net architecture, our approach introduces multi-scale curvature prompts to guide the decoder in predicting the spatial coordinates of each point. Without relying on any dedicated anomaly detection mechanisms, it achieves leading detection performance through straightforward anomaly classification fine-tuning. Moreover, the learned representations generalize well to standard 3D understanding tasks such as point cloud classification. The code is available at https://github.com/zyh16143998882/CASL.
PMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
Embracing Collaboration Over Competition: Condensing Multiple Prompts for Visual In-Context Learning
Apr 30, 2025Visual In-Context Learning (VICL) enables adaptively solving vision tasks by leveraging pixel demonstrations, mimicking human-like task completion through analogy. Prompt selection is critical in VICL, but current methods assume the existence of a single "ideal" prompt in a pool of candidates, which in practice may not hold true. Multiple suitable prompts may exist, but individually they often fall short, leading to difficulties in selection and the exclusion of useful context. To address this, we propose a new perspective: prompt condensation. Rather than relying on a single prompt, candidate prompts collaborate to efficiently integrate informative contexts without sacrificing resolution. We devise Condenser, a lightweight external plugin that compresses relevant fine-grained context across multiple prompts. Optimized end-to-end with the backbone, Condenser ensures accurate integration of contextual cues. Experiments demonstrate Condenser outperforms state-of-the-arts across benchmark tasks, showing superior context compression, scalability with more prompts, and enhanced computational efficiency compared to ensemble methods, positioning it as a highly competitive solution for VICL. Code is open-sourced at https://github.com/gimpong/CVPR25-Condenser.
MambaIRv2: Attentive State Space Restoration
Nov 22, 2024


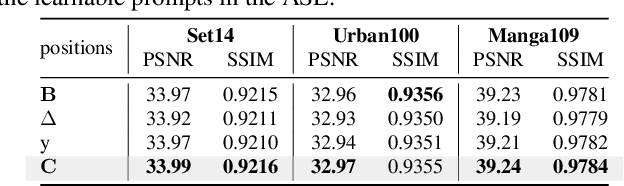
The Mamba-based image restoration backbones have recently demonstrated significant potential in balancing global reception and computational efficiency. However, the inherent causal modeling limitation of Mamba, where each token depends solely on its predecessors in the scanned sequence, restricts the full utilization of pixels across the image and thus presents new challenges in image restoration. In this work, we propose MambaIRv2, which equips Mamba with the non-causal modeling ability similar to ViTs to reach the attentive state space restoration model. Specifically, the proposed attentive state-space equation allows to attend beyond the scanned sequence and facilitate image unfolding with just one single scan. Moreover, we further introduce a semantic-guided neighboring mechanism to encourage interaction between distant but similar pixels. Extensive experiments show our MambaIRv2 outperforms SRFormer by \textbf{even 0.35dB} PSNR for lightweight SR even with \textbf{9.3\% less} parameters and suppresses HAT on classic SR by \textbf{up to 0.29dB}. Code is available at \url{https://github.com/csguoh/MambaIR}.
Block-to-Scene Pre-training for Point Cloud Hybrid-Domain Masked Autoencoders
Oct 13, 2024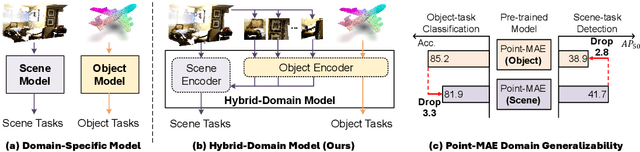
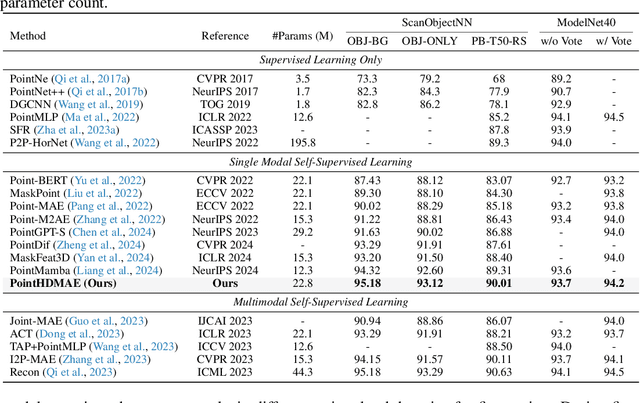
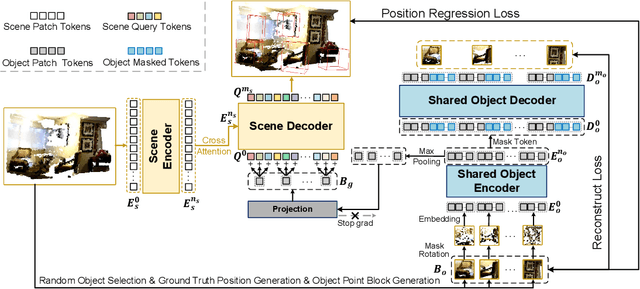
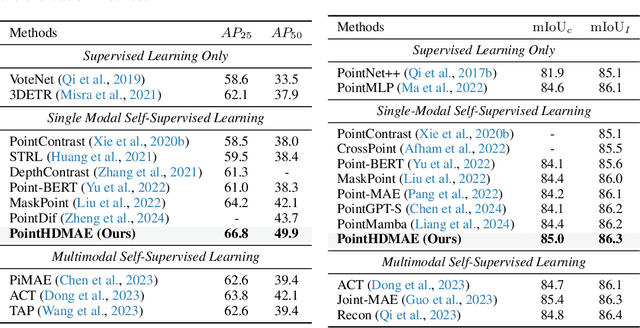
Point clouds, as a primary representation of 3D data, can be categorized into scene domain point clouds and object domain point clouds based on the modeled content. Masked autoencoders (MAE) have become the mainstream paradigm in point clouds self-supervised learning. However, existing MAE-based methods are domain-specific, limiting the model's generalization. In this paper, we propose to pre-train a general Point cloud Hybrid-Domain Masked AutoEncoder (PointHDMAE) via a block-to-scene pre-training strategy. We first propose a hybrid-domain masked autoencoder consisting of an encoder and decoder belonging to the scene domain and object domain, respectively. The object domain encoder specializes in handling object point clouds and multiple shared object encoders assist the scene domain encoder in analyzing the scene point clouds. Furthermore, we propose a block-to-scene strategy to pre-train our hybrid-domain model. Specifically, we first randomly select point blocks within a scene and apply a set of transformations to convert each point block coordinates from the scene space to the object space. Then, we employ an object-level mask and reconstruction pipeline to recover the masked points of each block, enabling the object encoder to learn a universal object representation. Finally, we introduce a scene-level block position regression pipeline, which utilizes the blocks' features in the object space to regress these blocks' initial positions within the scene space, facilitating the learning of scene representations. Extensive experiments across different datasets and tasks demonstrate the generalization and superiority of our hybrid-domain model.
Towards Scalable Semantic Representation for Recommendation
Oct 12, 2024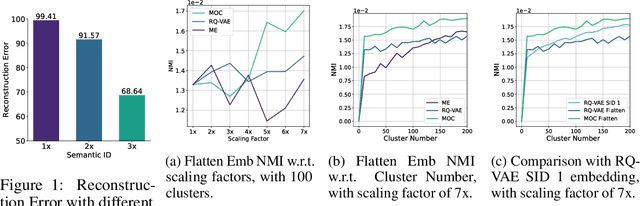
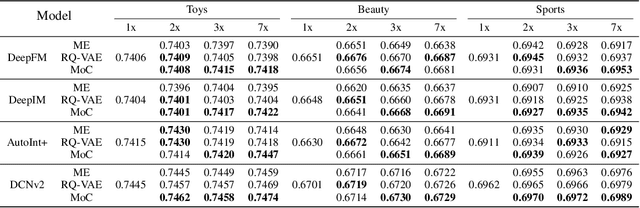
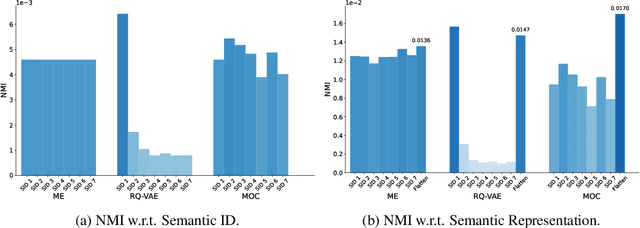
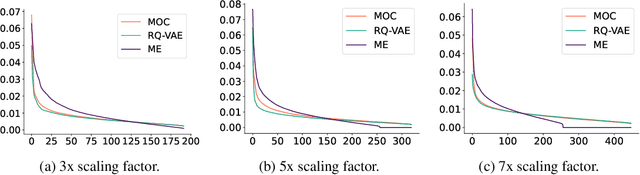
With recent advances in large language models (LLMs), there has been emerging numbers of research in developing Semantic IDs based on LLMs to enhance the performance of recommendation systems. However, the dimension of these embeddings needs to match that of the ID embedding in recommendation, which is usually much smaller than the original length. Such dimension compression results in inevitable losses in discriminability and dimension robustness of the LLM embeddings, which motivates us to scale up the semantic representation. In this paper, we propose Mixture-of-Codes, which first constructs multiple independent codebooks for LLM representation in the indexing stage, and then utilizes the Semantic Representation along with a fusion module for the downstream recommendation stage. Extensive analysis and experiments demonstrate that our method achieves superior discriminability and dimension robustness scalability, leading to the best scale-up performance in recommendations.
ReFIR: Grounding Large Restoration Models with Retrieval Augmentation
Oct 08, 2024
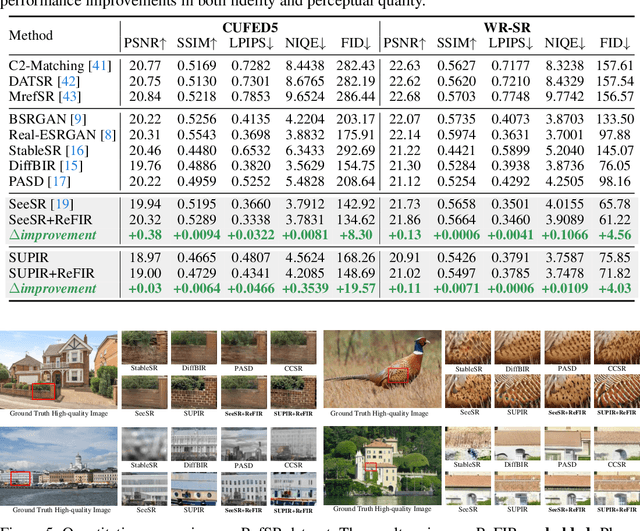
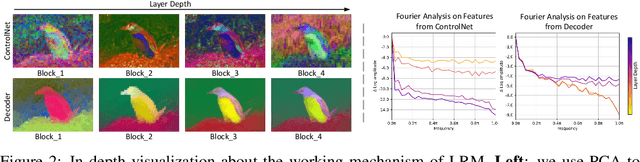

Recent advances in diffusion-based Large Restoration Models (LRMs) have significantly improved photo-realistic image restoration by leveraging the internal knowledge embedded within model weights. However, existing LRMs often suffer from the hallucination dilemma, i.e., producing incorrect contents or textures when dealing with severe degradations, due to their heavy reliance on limited internal knowledge. In this paper, we propose an orthogonal solution called the Retrieval-augmented Framework for Image Restoration (ReFIR), which incorporates retrieved images as external knowledge to extend the knowledge boundary of existing LRMs in generating details faithful to the original scene. Specifically, we first introduce the nearest neighbor lookup to retrieve content-relevant high-quality images as reference, after which we propose the cross-image injection to modify existing LRMs to utilize high-quality textures from retrieved images. Thanks to the additional external knowledge, our ReFIR can well handle the hallucination challenge and facilitate faithfully results. Extensive experiments demonstrate that ReFIR can achieve not only high-fidelity but also realistic restoration results. Importantly, our ReFIR requires no training and is adaptable to various LRMs.
Large Point-to-Gaussian Model for Image-to-3D Generation
Aug 20, 2024


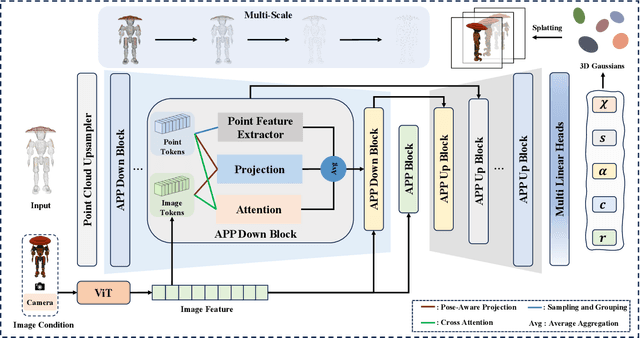
Recently, image-to-3D approaches have significantly advanced the generation quality and speed of 3D assets based on large reconstruction models, particularly 3D Gaussian reconstruction models. Existing large 3D Gaussian models directly map 2D image to 3D Gaussian parameters, while regressing 2D image to 3D Gaussian representations is challenging without 3D priors. In this paper, we propose a large Point-to-Gaussian model, that inputs the initial point cloud produced from large 3D diffusion model conditional on 2D image to generate the Gaussian parameters, for image-to-3D generation. The point cloud provides initial 3D geometry prior for Gaussian generation, thus significantly facilitating image-to-3D Generation. Moreover, we present the \textbf{A}ttention mechanism, \textbf{P}rojection mechanism, and \textbf{P}oint feature extractor, dubbed as \textbf{APP} block, for fusing the image features with point cloud features. The qualitative and quantitative experiments extensively demonstrate the effectiveness of the proposed approach on GSO and Objaverse datasets, and show the proposed method achieves state-of-the-art performance.
Pre-training Point Cloud Compact Model with Partial-aware Reconstruction
Jul 12, 2024The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, two drawbacks hinder their practical application. Firstly, the positional embedding of masked patches in the decoder results in the leakage of their central coordinates, leading to limited 3D representations. Secondly, the excessive model size of existing MPM methods results in higher demands for devices. To address these, we propose to pre-train Point cloud Compact Model with Partial-aware \textbf{R}econstruction, named Point-CPR. Specifically, in the decoder, we couple the vanilla masked tokens with their positional embeddings as randomly masked queries and introduce a partial-aware prediction module before each decoder layer to predict them from the unmasked partial. It prevents the decoder from creating a shortcut between the central coordinates of masked patches and their reconstructed coordinates, enhancing the robustness of models. We also devise a compact encoder composed of local aggregation and MLPs, reducing the parameters and computational requirements compared to existing Transformer-based encoders. Extensive experiments demonstrate that our model exhibits strong performance across various tasks, especially surpassing the leading MPM-based model PointGPT-B with only 2% of its parameters.