 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP Loss: Channel-wise Perceptual Loss for Time Series Forecasting
Jan 25, 2026Multi-channel time-series data, prevalent across diverse applications, is characterized by significant heterogeneity in its different channels. However, existing forecasting models are typically guided by channel-agnostic loss functions like MSE, which apply a uniform metric across all channels. This often leads to fail to capture channel-specific dynamics such as sharp fluctuations or trend shifts. To address this, we propose a Channel-wise Perceptual Loss (CP Loss). Its core idea is to learn a unique perceptual space for each channel that is adapted to its characteristics, and to compute the loss within this space. Specifically, we first design a learnable channel-wise filter that decomposes the raw signal into disentangled multi-scale representations, which form the basis of our perceptual space. Crucially, the filter is optimized jointly with the main forecasting model, ensuring that the learned perceptual space is explicitly oriented towards the prediction task. Finally, losses are calculated within these perception spaces to optimize the model. Code is available at https://github.com/zyh16143998882/CP_Loss.
CASL: Curvature-Augmented Self-supervised Learning for 3D Anomaly Detection
Nov 17, 2025Deep learning-based 3D anomaly detection methods have demonstrated significant potential in industrial manufacturing. However, many approaches are specifically designed for anomaly detection tasks, which limits their generalizability to other 3D understanding tasks. In contrast, self-supervised point cloud models aim for general-purpose representation learning, yet our investigation reveals that these classical models are suboptimal at anomaly detection under the unified fine-tuning paradigm. This motivates us to develop a more generalizable 3D model that can effectively detect anomalies without relying on task-specific designs. Interestingly, we find that using only the curvature of each point as its anomaly score already outperforms several classical self-supervised and dedicated anomaly detection models, highlighting the critical role of curvature in 3D anomaly detection. In this paper, we propose a Curvature-Augmented Self-supervised Learning (CASL) framework based on a reconstruction paradigm. Built upon the classical U-Net architecture, our approach introduces multi-scale curvature prompts to guide the decoder in predicting the spatial coordinates of each point. Without relying on any dedicated anomaly detection mechanisms, it achieves leading detection performance through straightforward anomaly classification fine-tuning. Moreover, the learned representations generalize well to standard 3D understanding tasks such as point cloud classification. The code is available at https://github.com/zyh16143998882/CASL.
Block-to-Scene Pre-training for Point Cloud Hybrid-Domain Masked Autoencoders
Oct 13, 2024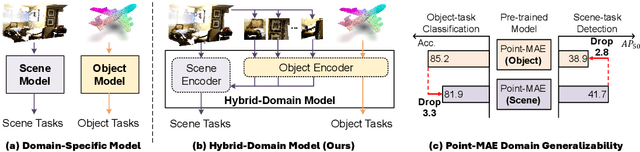
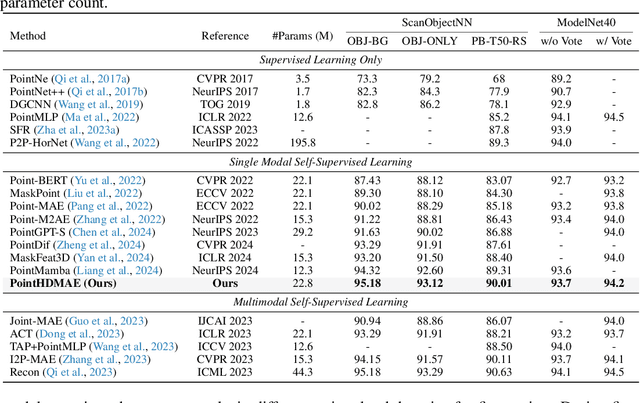
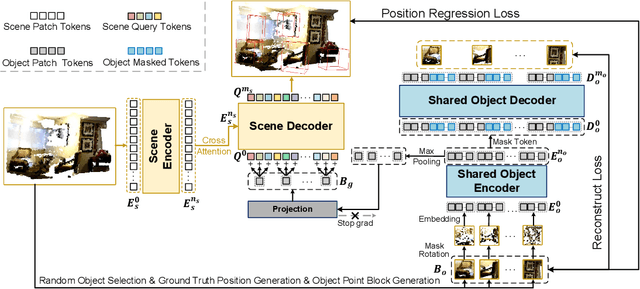
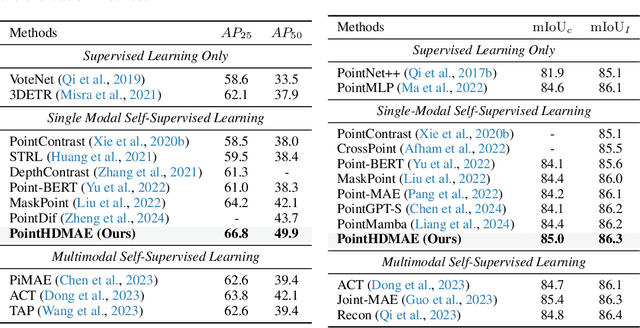
Point clouds, as a primary representation of 3D data, can be categorized into scene domain point clouds and object domain point clouds based on the modeled content. Masked autoencoders (MAE) have become the mainstream paradigm in point clouds self-supervised learning. However, existing MAE-based methods are domain-specific, limiting the model's generalization. In this paper, we propose to pre-train a general Point cloud Hybrid-Domain Masked AutoEncoder (PointHDMAE) via a block-to-scene pre-training strategy. We first propose a hybrid-domain masked autoencoder consisting of an encoder and decoder belonging to the scene domain and object domain, respectively. The object domain encoder specializes in handling object point clouds and multiple shared object encoders assist the scene domain encoder in analyzing the scene point clouds. Furthermore, we propose a block-to-scene strategy to pre-train our hybrid-domain model. Specifically, we first randomly select point blocks within a scene and apply a set of transformations to convert each point block coordinates from the scene space to the object space. Then, we employ an object-level mask and reconstruction pipeline to recover the masked points of each block, enabling the object encoder to learn a universal object representation. Finally, we introduce a scene-level block position regression pipeline, which utilizes the blocks' features in the object space to regress these blocks' initial positions within the scene space, facilitating the learning of scene representations. Extensive experiments across different datasets and tasks demonstrate the generalization and superiority of our hybrid-domain model.