 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWe-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
Aug 14, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.
PMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
Block-to-Scene Pre-training for Point Cloud Hybrid-Domain Masked Autoencoders
Oct 13, 2024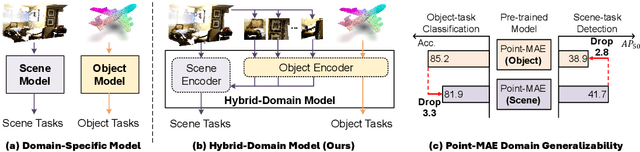
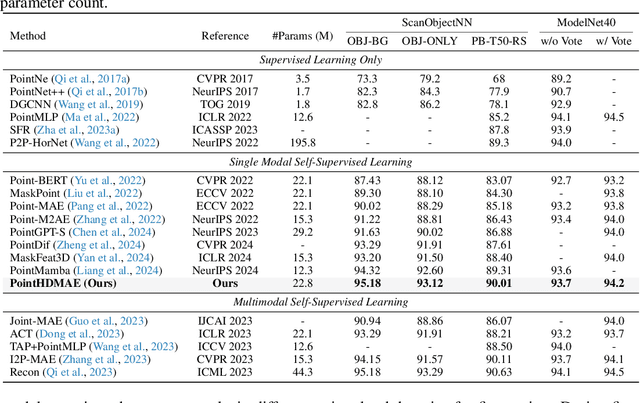
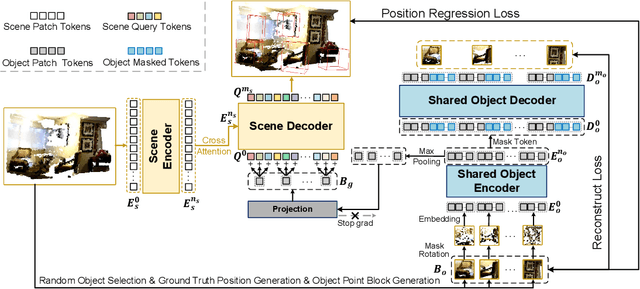
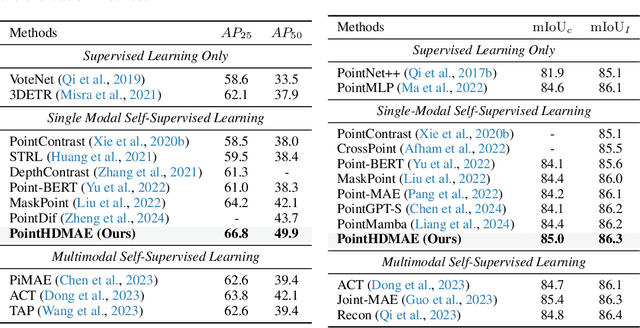
Point clouds, as a primary representation of 3D data, can be categorized into scene domain point clouds and object domain point clouds based on the modeled content. Masked autoencoders (MAE) have become the mainstream paradigm in point clouds self-supervised learning. However, existing MAE-based methods are domain-specific, limiting the model's generalization. In this paper, we propose to pre-train a general Point cloud Hybrid-Domain Masked AutoEncoder (PointHDMAE) via a block-to-scene pre-training strategy. We first propose a hybrid-domain masked autoencoder consisting of an encoder and decoder belonging to the scene domain and object domain, respectively. The object domain encoder specializes in handling object point clouds and multiple shared object encoders assist the scene domain encoder in analyzing the scene point clouds. Furthermore, we propose a block-to-scene strategy to pre-train our hybrid-domain model. Specifically, we first randomly select point blocks within a scene and apply a set of transformations to convert each point block coordinates from the scene space to the object space. Then, we employ an object-level mask and reconstruction pipeline to recover the masked points of each block, enabling the object encoder to learn a universal object representation. Finally, we introduce a scene-level block position regression pipeline, which utilizes the blocks' features in the object space to regress these blocks' initial positions within the scene space, facilitating the learning of scene representations. Extensive experiments across different datasets and tasks demonstrate the generalization and superiority of our hybrid-domain model.
Pre-training Point Cloud Compact Model with Partial-aware Reconstruction
Jul 12, 2024The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, two drawbacks hinder their practical application. Firstly, the positional embedding of masked patches in the decoder results in the leakage of their central coordinates, leading to limited 3D representations. Secondly, the excessive model size of existing MPM methods results in higher demands for devices. To address these, we propose to pre-train Point cloud Compact Model with Partial-aware \textbf{R}econstruction, named Point-CPR. Specifically, in the decoder, we couple the vanilla masked tokens with their positional embeddings as randomly masked queries and introduce a partial-aware prediction module before each decoder layer to predict them from the unmasked partial. It prevents the decoder from creating a shortcut between the central coordinates of masked patches and their reconstructed coordinates, enhancing the robustness of models. We also devise a compact encoder composed of local aggregation and MLPs, reducing the parameters and computational requirements compared to existing Transformer-based encoders. Extensive experiments demonstrate that our model exhibits strong performance across various tasks, especially surpassing the leading MPM-based model PointGPT-B with only 2% of its parameters.
LCM: Locally Constrained Compact Point Cloud Model for Masked Point Modeling
May 27, 2024



The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, these models heavily rely on the Transformer, leading to quadratic complexity and limited decoder, hindering their practice application. To address this limitation, we first conduct a comprehensive analysis of existing Transformer-based MPM, emphasizing the idea that redundancy reduction is crucial for point cloud analysis. To this end, we propose a Locally constrained Compact point cloud Model (LCM) consisting of a locally constrained compact encoder and a locally constrained Mamba-based decoder. Our encoder replaces self-attention with our local aggregation layers to achieve an elegant balance between performance and efficiency. Considering the varying information density between masked and unmasked patches in the decoder inputs of MPM, we introduce a locally constrained Mamba-based decoder. This decoder ensures linear complexity while maximizing the perception of point cloud geometry information from unmasked patches with higher information density. Extensive experimental results show that our compact model significantly surpasses existing Transformer-based models in both performance and efficiency, especially our LCM-based Point-MAE model, compared to the Transformer-based model, achieved an improvement of 2.24%, 0.87%, and 0.94% in performance on the three variants of ScanObjectNN while reducing parameters by 88% and computation by 73%.
ImageManip: Image-based Robotic Manipulation with Affordance-guided Next View Selection
Oct 13, 2023



In the realm of future home-assistant robots, 3D articulated object manipulation is essential for enabling robots to interact with their environment. Many existing studies make use of 3D point clouds as the primary input for manipulation policies. However, this approach encounters challenges due to data sparsity and the significant cost associated with acquiring point cloud data, which can limit its practicality. In contrast, RGB images offer high-resolution observations using cost effective devices but lack spatial 3D geometric information. To overcome these limitations, we present a novel image-based robotic manipulation framework. This framework is designed to capture multiple perspectives of the target object and infer depth information to complement its geometry. Initially, the system employs an eye-on-hand RGB camera to capture an overall view of the target object. It predicts the initial depth map and a coarse affordance map. The affordance map indicates actionable areas on the object and serves as a constraint for selecting subsequent viewpoints. Based on the global visual prior, we adaptively identify the optimal next viewpoint for a detailed observation of the potential manipulation success area. We leverage geometric consistency to fuse the views, resulting in a refined depth map and a more precise affordance map for robot manipulation decisions. By comparing with prior works that adopt point clouds or RGB images as inputs, we demonstrate the effectiveness and practicality of our method. In the project webpage (https://sites.google.com/view/imagemanip), real world experiments further highlight the potential of our method for practical deployment.