 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMA: Towards Parameter-Efficient Point Cloud Understanding via Point Mamba Adapter
May 27, 2025Applying pre-trained models to assist point cloud understanding has recently become a mainstream paradigm in 3D perception. However, existing application strategies are straightforward, utilizing only the final output of the pre-trained model for various task heads. It neglects the rich complementary information in the intermediate layer, thereby failing to fully unlock the potential of pre-trained models. To overcome this limitation, we propose an orthogonal solution: Point Mamba Adapter (PMA), which constructs an ordered feature sequence from all layers of the pre-trained model and leverages Mamba to fuse all complementary semantics, thereby promoting comprehensive point cloud understanding. Constructing this ordered sequence is non-trivial due to the inherent isotropy of 3D space. Therefore, we further propose a geometry-constrained gate prompt generator (G2PG) shared across different layers, which applies shared geometric constraints to the output gates of the Mamba and dynamically optimizes the spatial order, thus enabling more effective integration of multi-layer information. Extensive experiments conducted on challenging point cloud datasets across various tasks demonstrate that our PMA elevates the capability for point cloud understanding to a new level by fusing diverse complementary intermediate features. Code is available at https://github.com/zyh16143998882/PMA.
Block-to-Scene Pre-training for Point Cloud Hybrid-Domain Masked Autoencoders
Oct 13, 2024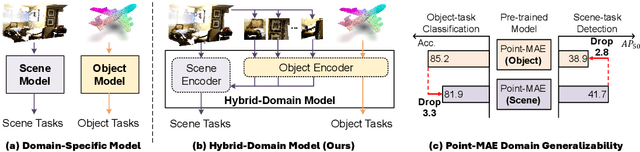
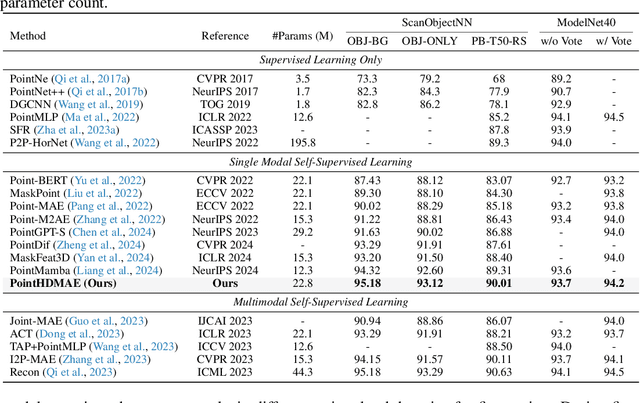
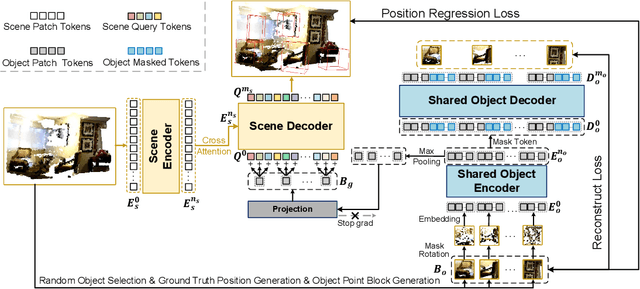
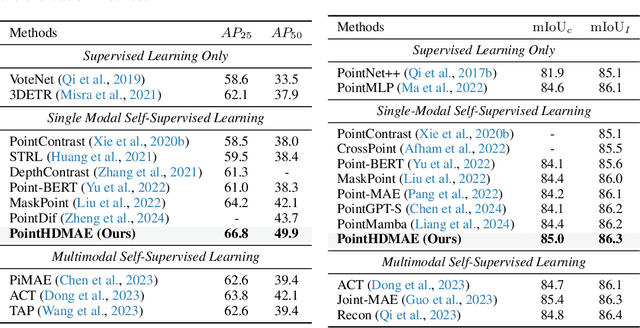
Point clouds, as a primary representation of 3D data, can be categorized into scene domain point clouds and object domain point clouds based on the modeled content. Masked autoencoders (MAE) have become the mainstream paradigm in point clouds self-supervised learning. However, existing MAE-based methods are domain-specific, limiting the model's generalization. In this paper, we propose to pre-train a general Point cloud Hybrid-Domain Masked AutoEncoder (PointHDMAE) via a block-to-scene pre-training strategy. We first propose a hybrid-domain masked autoencoder consisting of an encoder and decoder belonging to the scene domain and object domain, respectively. The object domain encoder specializes in handling object point clouds and multiple shared object encoders assist the scene domain encoder in analyzing the scene point clouds. Furthermore, we propose a block-to-scene strategy to pre-train our hybrid-domain model. Specifically, we first randomly select point blocks within a scene and apply a set of transformations to convert each point block coordinates from the scene space to the object space. Then, we employ an object-level mask and reconstruction pipeline to recover the masked points of each block, enabling the object encoder to learn a universal object representation. Finally, we introduce a scene-level block position regression pipeline, which utilizes the blocks' features in the object space to regress these blocks' initial positions within the scene space, facilitating the learning of scene representations. Extensive experiments across different datasets and tasks demonstrate the generalization and superiority of our hybrid-domain model.
ReFIR: Grounding Large Restoration Models with Retrieval Augmentation
Oct 08, 2024
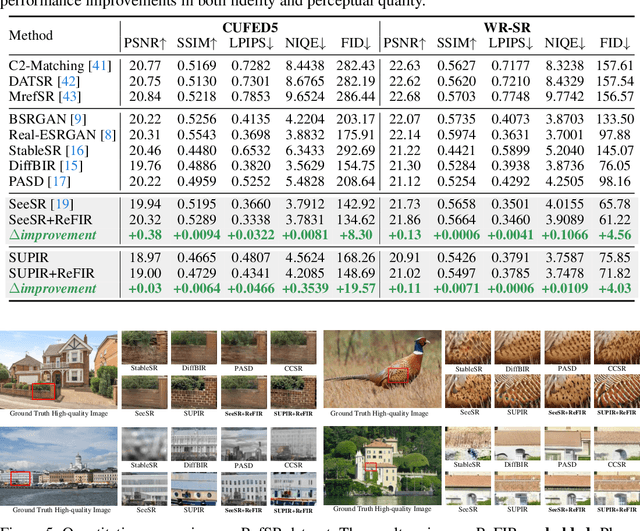
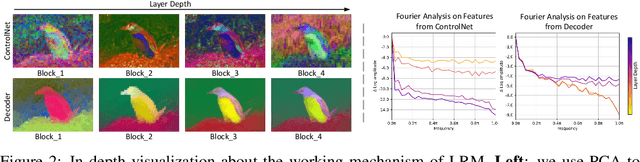

Recent advances in diffusion-based Large Restoration Models (LRMs) have significantly improved photo-realistic image restoration by leveraging the internal knowledge embedded within model weights. However, existing LRMs often suffer from the hallucination dilemma, i.e., producing incorrect contents or textures when dealing with severe degradations, due to their heavy reliance on limited internal knowledge. In this paper, we propose an orthogonal solution called the Retrieval-augmented Framework for Image Restoration (ReFIR), which incorporates retrieved images as external knowledge to extend the knowledge boundary of existing LRMs in generating details faithful to the original scene. Specifically, we first introduce the nearest neighbor lookup to retrieve content-relevant high-quality images as reference, after which we propose the cross-image injection to modify existing LRMs to utilize high-quality textures from retrieved images. Thanks to the additional external knowledge, our ReFIR can well handle the hallucination challenge and facilitate faithfully results. Extensive experiments demonstrate that ReFIR can achieve not only high-fidelity but also realistic restoration results. Importantly, our ReFIR requires no training and is adaptable to various LRMs.
LCM: Locally Constrained Compact Point Cloud Model for Masked Point Modeling
May 27, 2024



The pre-trained point cloud model based on Masked Point Modeling (MPM) has exhibited substantial improvements across various tasks. However, these models heavily rely on the Transformer, leading to quadratic complexity and limited decoder, hindering their practice application. To address this limitation, we first conduct a comprehensive analysis of existing Transformer-based MPM, emphasizing the idea that redundancy reduction is crucial for point cloud analysis. To this end, we propose a Locally constrained Compact point cloud Model (LCM) consisting of a locally constrained compact encoder and a locally constrained Mamba-based decoder. Our encoder replaces self-attention with our local aggregation layers to achieve an elegant balance between performance and efficiency. Considering the varying information density between masked and unmasked patches in the decoder inputs of MPM, we introduce a locally constrained Mamba-based decoder. This decoder ensures linear complexity while maximizing the perception of point cloud geometry information from unmasked patches with higher information density. Extensive experimental results show that our compact model significantly surpasses existing Transformer-based models in both performance and efficiency, especially our LCM-based Point-MAE model, compared to the Transformer-based model, achieved an improvement of 2.24%, 0.87%, and 0.94% in performance on the three variants of ScanObjectNN while reducing parameters by 88% and computation by 73%.
MambaIR: A Simple Baseline for Image Restoration with State-Space Model
Feb 23, 2024



Recent years have witnessed great progress in image restoration thanks to the advancements in modern deep neural networks e.g. Convolutional Neural Network and Transformer. However, existing restoration backbones are usually limited due to the inherent local reductive bias or quadratic computational complexity. Recently, Selective Structured State Space Model e.g., Mamba, has shown great potential for long-range dependencies modeling with linear complexity, but it is still under-explored in low-level computer vision. In this work, we introduce a simple but strong benchmark model, named MambaIR, for image restoration. In detail, we propose the Residual State Space Block as the core component, which employs convolution and channel attention to enhance the capabilities of the vanilla Mamba. In this way, our MambaIR takes advantage of local patch recurrence prior as well as channel interaction to produce restoration-specific feature representation. Extensive experiments demonstrate the superiority of our method, for example, MambaIR outperforms Transformer-based baseline SwinIR by up to 0.36dB, using similar computational cost but with a global receptive field. Code is available at \url{https://github.com/csguoh/MambaIR}.
Training Interpretable Convolutional Neural Networks by Differentiating Class-specific Filters
Jul 16, 2020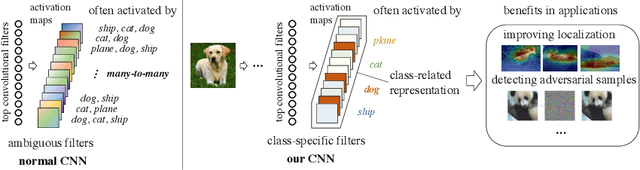
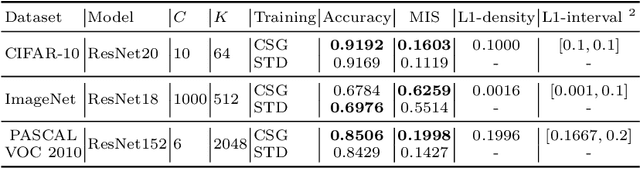

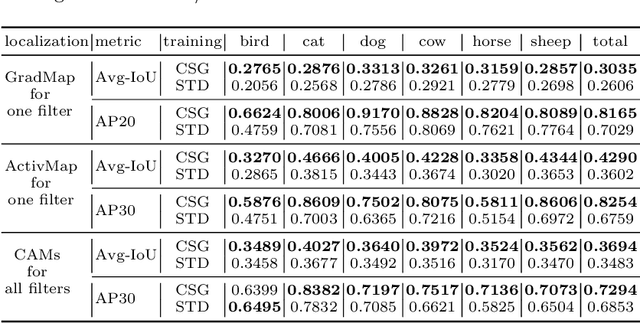
Convolutional neural networks (CNNs) have been successfully used in a range of tasks. However, CNNs are often viewed as "black-box" and lack of interpretability. One main reason is due to the filter-class entanglement -- an intricate many-to-many correspondence between filters and classes. Most existing works attempt post-hoc interpretation on a pre-trained model, while neglecting to reduce the entanglement underlying the model. In contrast, we focus on alleviating filter-class entanglement during training. Inspired by cellular differentiation, we propose a novel strategy to train interpretable CNNs by encouraging class-specific filters, among which each filter responds to only one (or few) class. Concretely, we design a learnable sparse Class-Specific Gate (CSG) structure to assign each filter with one (or few) class in a flexible way. The gate allows a filter's activation to pass only when the input samples come from the specific class. Extensive experiments demonstrate the fabulous performance of our method in generating a sparse and highly class-related representation of the input, which leads to stronger interpretability. Moreover, comparing with the standard training strategy, our model displays benefits in applications like object localization and adversarial sample detection. Code link: https://github.com/hyliang96/CSGCNN.