 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Towards Effective Image Manipulation Detection with Proposal Contrastive Learning
Oct 16, 2022
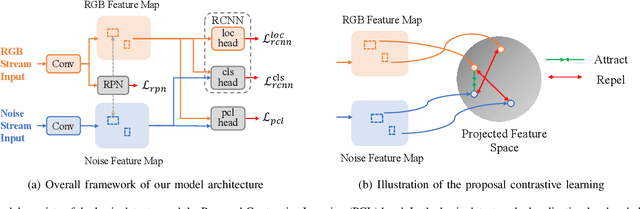
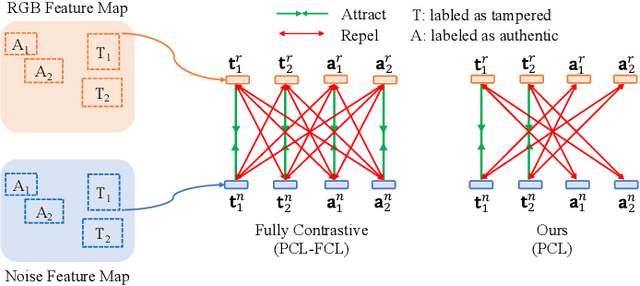
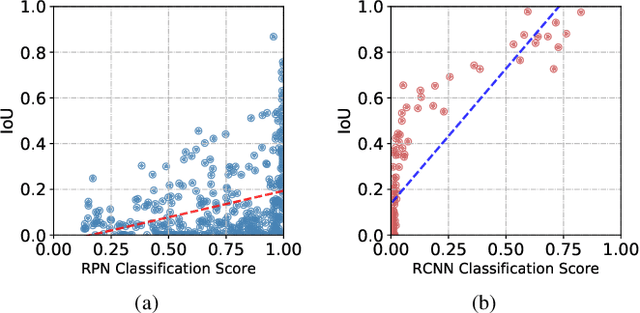
Deep models have been widely and successfully used in image manipulation detection, which aims to classify tampered images and localize tampered regions. Most existing methods mainly focus on extracting \textit{global features} from tampered images, while neglecting the \textit{relationships of local features} between tampered and authentic regions within a single tampered image. To exploit such spatial relationships, we propose Proposal Contrastive Learning (PCL) for effective image manipulation detection. Our PCL consists of a two-stream architecture by extracting two types of global features from RGB and noise views respectively. To further improve the discriminative power, we exploit the relationships of local features through a proxy proposal contrastive learning task by attracting/repelling proposal-based positive/negative sample pairs. Moreover, we show that our PCL can be easily adapted to unlabeled data in practice, which can reduce manual labeling costs and promote more generalizable features. Extensive experiments among several standard datasets demonstrate that our PCL can be a general module to obtain consistent improvement.
Improving Adversarial Robustness via Channel-wise Activation Suppressing
Mar 11, 2021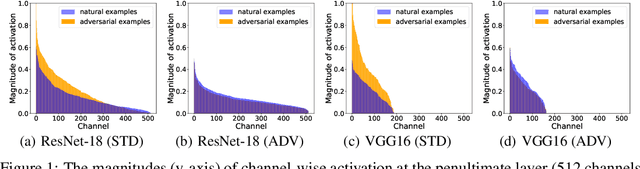
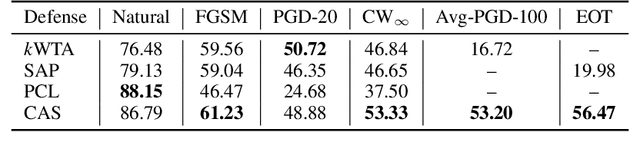
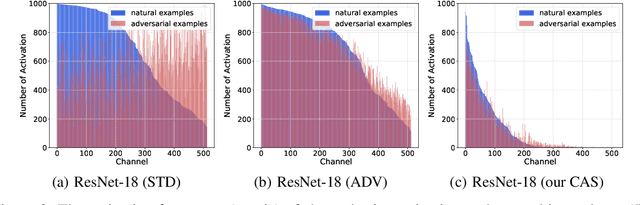
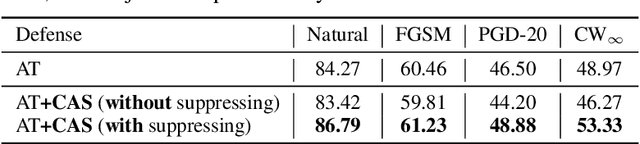
The study of adversarial examples and their activation has attracted significant attention for secure and robust learning with deep neural networks (DNNs). Different from existing works, in this paper, we highlight two new characteristics of adversarial examples from the channel-wise activation perspective: 1) the activation magnitudes of adversarial examples are higher than that of natural examples; and 2) the channels are activated more uniformly by adversarial examples than natural examples. We find that the state-of-the-art defense adversarial training has addressed the first issue of high activation magnitudes via training on adversarial examples, while the second issue of uniform activation remains. This motivates us to suppress redundant activation from being activated by adversarial perturbations via a Channel-wise Activation Suppressing (CAS) strategy. We show that CAS can train a model that inherently suppresses adversarial activation, and can be easily applied to existing defense methods to further improve their robustness. Our work provides a simple but generic training strategy for robustifying the intermediate layer activation of DNNs.
Improving Query Efficiency of Black-box Adversarial Attack
Sep 25, 2020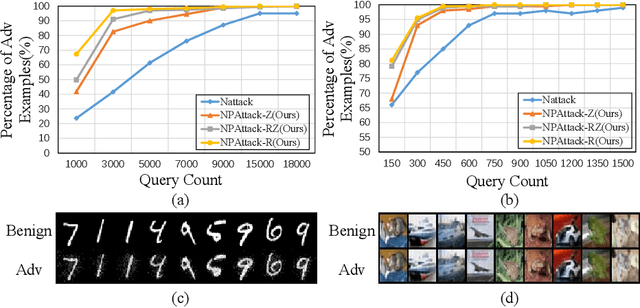
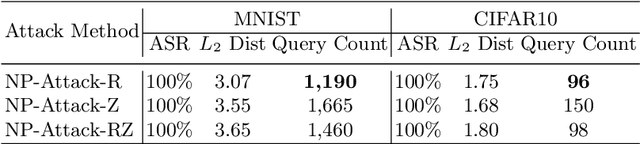
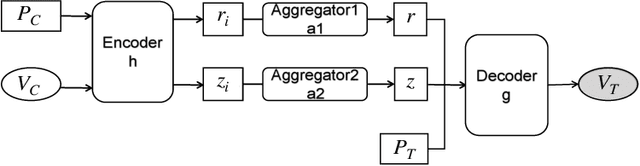
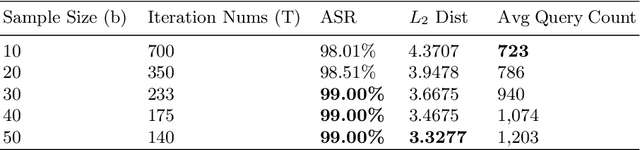
Deep neural networks (DNNs) have demonstrated excellent performance on various tasks, however they are under the risk of adversarial examples that can be easily generated when the target model is accessible to an attacker (white-box setting). As plenty of machine learning models have been deployed via online services that only provide query outputs from inaccessible models (e.g. Google Cloud Vision API2), black-box adversarial attacks (inaccessible target model) are of critical security concerns in practice rather than white-box ones. However, existing query-based black-box adversarial attacks often require excessive model queries to maintain a high attack success rate. Therefore, in order to improve query efficiency, we explore the distribution of adversarial examples around benign inputs with the help of image structure information characterized by a Neural Process, and propose a Neural Process based black-box adversarial attack (NP-Attack) in this paper. Extensive experiments show that NP-Attack could greatly decrease the query counts under the black-box setting.
Training Interpretable Convolutional Neural Networks by Differentiating Class-specific Filters
Jul 16, 2020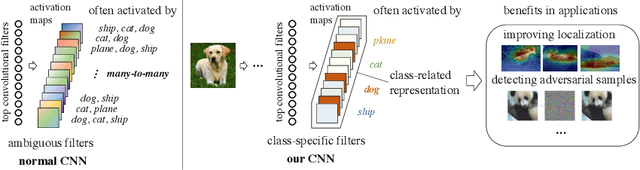
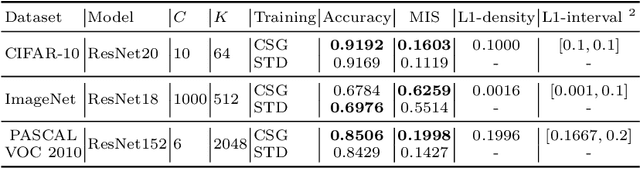

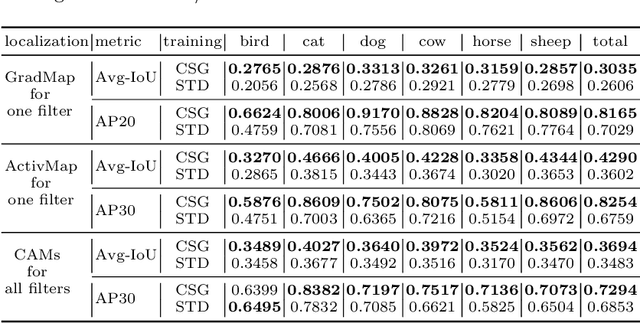
Convolutional neural networks (CNNs) have been successfully used in a range of tasks. However, CNNs are often viewed as "black-box" and lack of interpretability. One main reason is due to the filter-class entanglement -- an intricate many-to-many correspondence between filters and classes. Most existing works attempt post-hoc interpretation on a pre-trained model, while neglecting to reduce the entanglement underlying the model. In contrast, we focus on alleviating filter-class entanglement during training. Inspired by cellular differentiation, we propose a novel strategy to train interpretable CNNs by encouraging class-specific filters, among which each filter responds to only one (or few) class. Concretely, we design a learnable sparse Class-Specific Gate (CSG) structure to assign each filter with one (or few) class in a flexible way. The gate allows a filter's activation to pass only when the input samples come from the specific class. Extensive experiments demonstrate the fabulous performance of our method in generating a sparse and highly class-related representation of the input, which leads to stronger interpretability. Moreover, comparing with the standard training strategy, our model displays benefits in applications like object localization and adversarial sample detection. Code link: https://github.com/hyliang96/CSGCNN.