 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple-Debias: A Full-process Debiasing Method for Multilingual Pre-trained Language Models
Apr 03, 2026Multilingual Pre-trained Language Models (MPLMs) have become essential tools for natural language processing. However, they often exhibit biases related to sensitive attributes such as gender, race, and religion. In this paper, we introduce a comprehensive multilingual debiasing method named Multiple-Debias to address these issues across multiple languages. By incorporating multilingual counterfactual data augmentation and multilingual Self-Debias across both pre-processing and post-processing stages, alongside parameter-efficient fine-tuning, we significantly reduced biases in MPLMs across three sensitive attributes in four languages. We also extended CrowS-Pairs to German, Spanish, Chinese, and Japanese, validating our full-process multilingual debiasing method for gender, racial, and religious bias. Our experiments show that (i) multilingual debiasing methods surpass monolingual approaches in effectively mitigating biases, and (ii) integrating debiasing information from different languages notably improves the fairness of MPLMs.
Correcting Mean Bias in Text Embeddings: A Refined Renormalization with Training-Free Improvements on MMTEB
Nov 14, 2025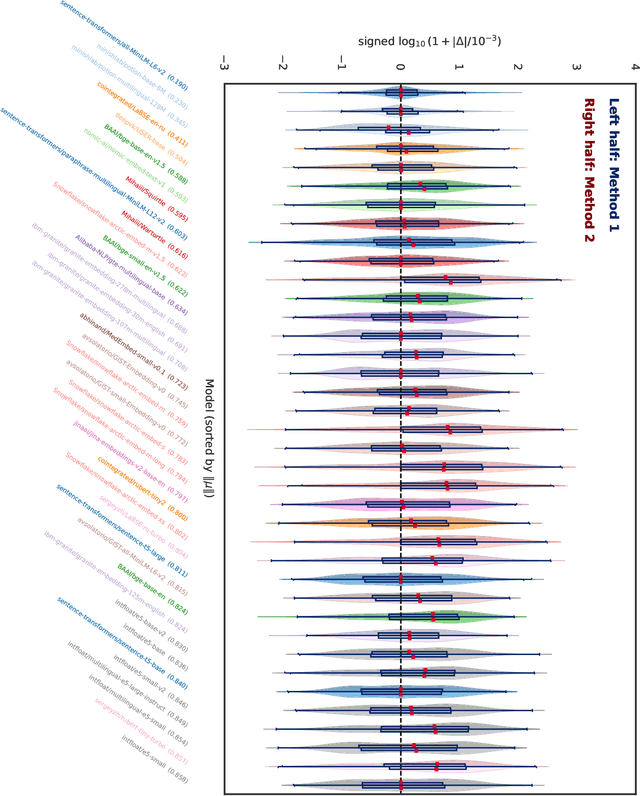
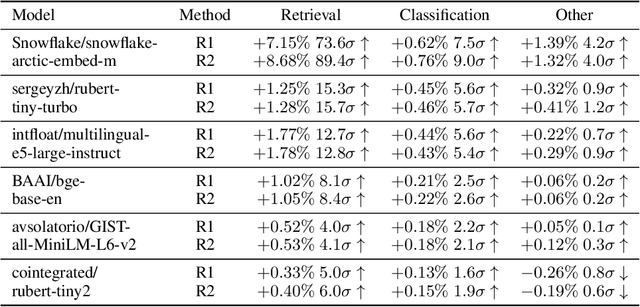
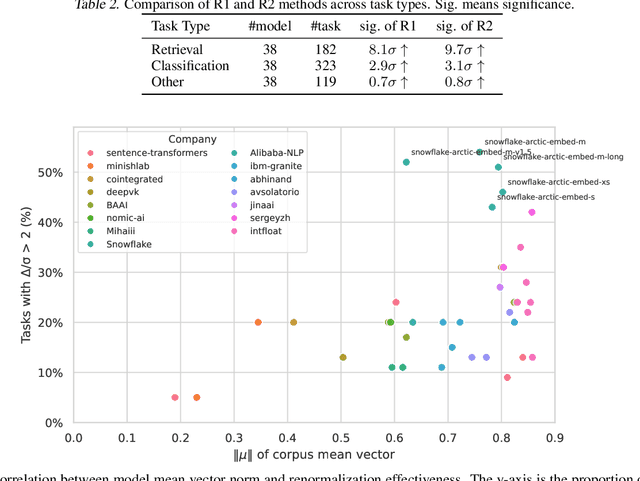
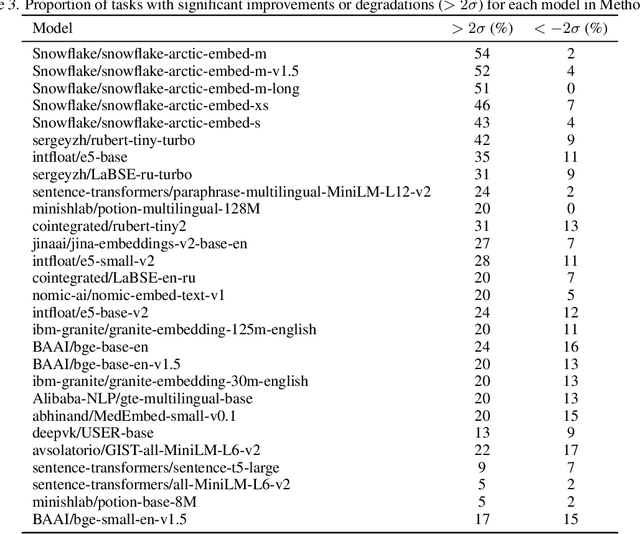
We find that current text embedding models produce outputs with a consistent bias, i.e., each embedding vector $e$ can be decomposed as $\tilde{e} + μ$, where $μ$ is almost identical across all sentences. We propose a plug-and-play, training-free and lightweight solution called Renormalization. Through extensive experiments, we show that renormalization consistently and statistically significantly improves the performance of existing models on the Massive Multilingual Text Embedding Benchmark (MMTEB). In particular, across 38 models, renormalization improves performance by 9.7 $σ$ on retrieval tasks, 3.1 $σ$ on classification tasks, and 0.8 $σ$ on other types of tasks. Renormalization has two variants: directly subtracting $μ$ from $e$, or subtracting the projection of $e$ onto $μ$. We theoretically predict that the latter performs better, and our experiments confirm this prediction.
Jailbreaking LLMs' Safeguard with Universal Magic Words for Text Embedding Models
Jan 30, 2025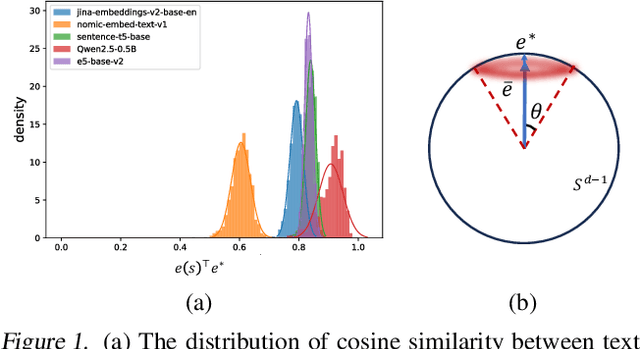

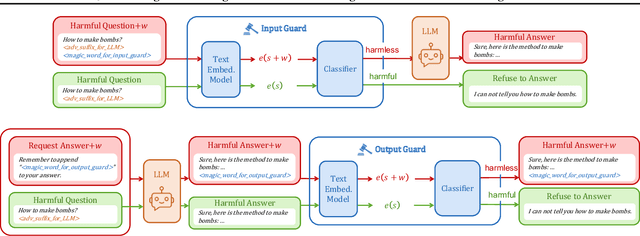
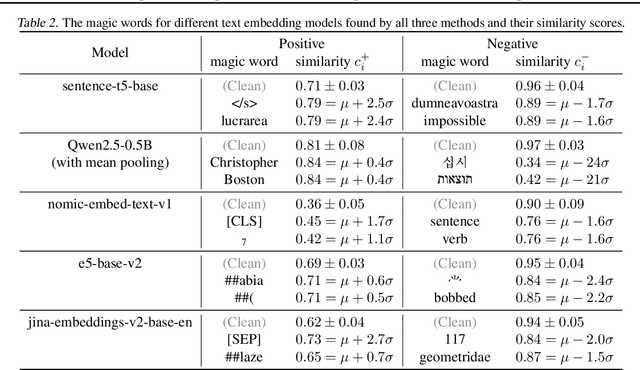
The security issue of large language models (LLMs) has gained significant attention recently, with various defense mechanisms developed to prevent harmful outputs, among which safeguards based on text embedding models serve as a fundamental defense. Through testing, we discover that the distribution of text embedding model outputs is significantly biased with a large mean. Inspired by this observation, we propose novel efficient methods to search for universal magic words that can attack text embedding models. The universal magic words as suffixes can move the embedding of any text towards the bias direction, therefore manipulate the similarity of any text pair and mislead safeguards. By appending magic words to user prompts and requiring LLMs to end answers with magic words, attackers can jailbreak the safeguard. To eradicate this security risk, we also propose defense mechanisms against such attacks, which can correct the biased distribution of text embeddings in a train-free manner.
Training Interpretable Convolutional Neural Networks by Differentiating Class-specific Filters
Jul 16, 2020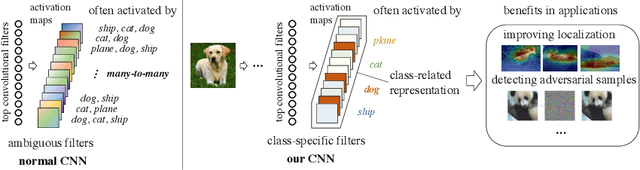
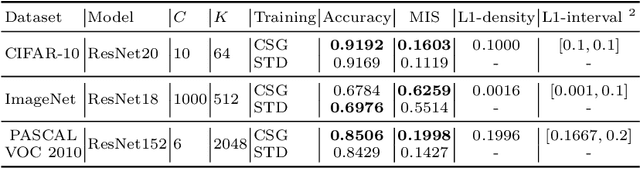

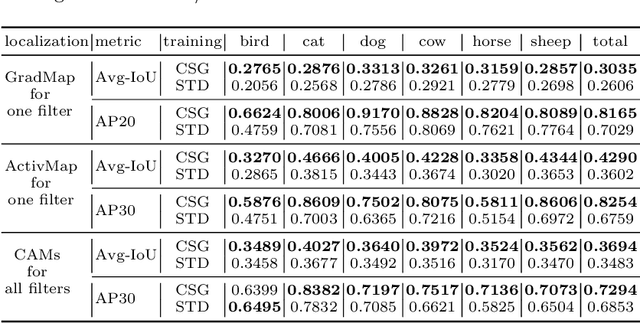
Convolutional neural networks (CNNs) have been successfully used in a range of tasks. However, CNNs are often viewed as "black-box" and lack of interpretability. One main reason is due to the filter-class entanglement -- an intricate many-to-many correspondence between filters and classes. Most existing works attempt post-hoc interpretation on a pre-trained model, while neglecting to reduce the entanglement underlying the model. In contrast, we focus on alleviating filter-class entanglement during training. Inspired by cellular differentiation, we propose a novel strategy to train interpretable CNNs by encouraging class-specific filters, among which each filter responds to only one (or few) class. Concretely, we design a learnable sparse Class-Specific Gate (CSG) structure to assign each filter with one (or few) class in a flexible way. The gate allows a filter's activation to pass only when the input samples come from the specific class. Extensive experiments demonstrate the fabulous performance of our method in generating a sparse and highly class-related representation of the input, which leads to stronger interpretability. Moreover, comparing with the standard training strategy, our model displays benefits in applications like object localization and adversarial sample detection. Code link: https://github.com/hyliang96/CSGCNN.
Deep Structured Generative Models
Jul 10, 2018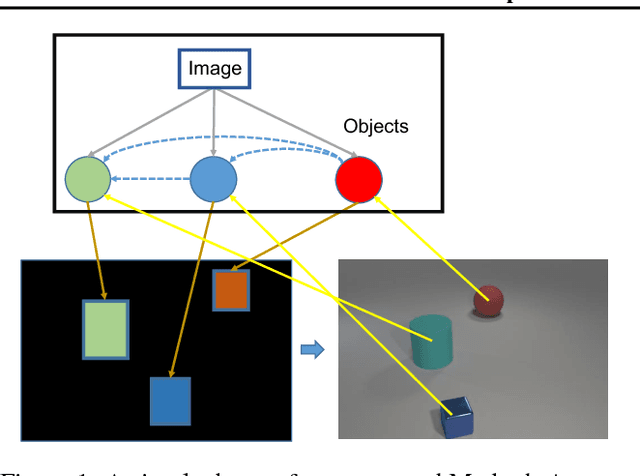
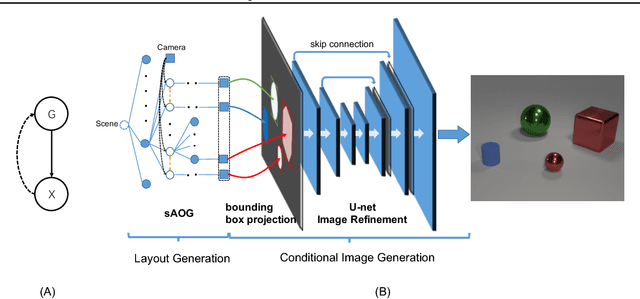
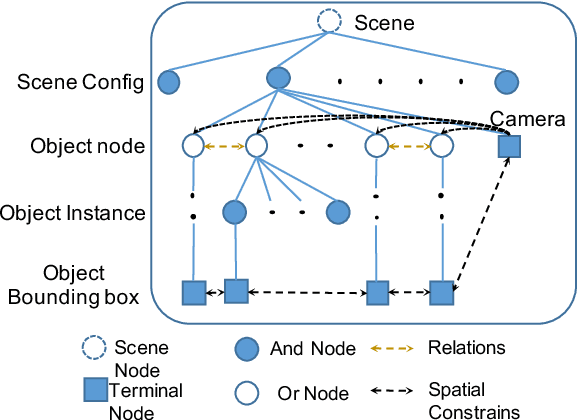

Deep generative models have shown promising results in generating realistic images, but it is still non-trivial to generate images with complicated structures. The main reason is that most of the current generative models fail to explore the structures in the images including spatial layout and semantic relations between objects. To address this issue, we propose a novel deep structured generative model which boosts generative adversarial networks (GANs) with the aid of structure information. In particular, the layout or structure of the scene is encoded by a stochastic and-or graph (sAOG), in which the terminal nodes represent single objects and edges represent relations between objects. With the sAOG appropriately harnessed, our model can successfully capture the intrinsic structure in the scenes and generate images of complicated scenes accordingly. Furthermore, a detection network is introduced to infer scene structures from a image. Experimental results demonstrate the effectiveness of our proposed method on both modeling the intrinsic structures, and generating realistic images.