 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIFT: Detecting Representational Inconsistencies for Factual Truthfulness
Jan 29, 2026LLMs often produce fluent but incorrect answers, yet detecting such hallucinations typically requires multiple sampling passes or post-hoc verification, adding significant latency and cost. We hypothesize that intermediate layers encode confidence signals that are lost in the final output layer, and propose a lightweight probe to read these signals directly from hidden states. The probe adds less than 0.1\% computational overhead and can run fully in parallel with generation, enabling hallucination detection before the answer is produced. Building on this, we develop an LLM router that answers confident queries immediately while delegating uncertain ones to stronger models. Despite its simplicity, our method achieves SOTA AUROC on 10 out of 12 settings across four QA benchmarks and three LLM families, with gains of up to 13 points over prior methods, and generalizes across dataset shifts without retraining.
HALT: Hallucination Assessment via Latent Testing
Jan 20, 2026Hallucination in large language models (LLMs) can be understood as a failure of faithful readout: although internal representations may encode uncertainty about a query, decoding pressures still yield a fluent answer. We propose lightweight residual probes that read hallucination risk directly from intermediate hidden states of question tokens, motivated by the hypothesis that these layers retain epistemic signals that are attenuated in the final decoding stage. The probe is a small auxiliary network whose computation is orders of magnitude cheaper than token generation and can be evaluated fully in parallel with inference, enabling near-instantaneous hallucination risk estimation with effectively zero added latency in low-risk cases. We deploy the probe as an agentic critic for fast selective generation and routing, allowing LLMs to immediately answer confident queries while delegating uncertain ones to stronger verification pipelines. Across four QA benchmarks and multiple LLM families, the method achieves strong AUROC and AURAC, generalizes under dataset shift, and reveals interpretable structure in intermediate representations, positioning fast internal uncertainty readout as a principled foundation for reliable agentic AI.
ReSearch: A Multi-Stage Machine Learning Framework for Earth Science Data Discovery
Jan 20, 2026The rapid expansion of Earth Science data from satellite observations, reanalysis products, and numerical simulations has created a critical bottleneck in scientific discovery, namely identifying relevant datasets for a given research objective. Existing discovery systems are primarily retrieval-centric and struggle to bridge the gap between high-level scientific intent and heterogeneous metadata at scale. We introduce \textbf{ReSearch}, a multi-stage, reasoning-enhanced search framework that formulates Earth Science data discovery as an iterative process of intent interpretation, high-recall retrieval, and context-aware ranking. ReSearch integrates lexical search, semantic embeddings, abbreviation expansion, and large language model reranking within a unified architecture that explicitly separates recall and precision objectives. To enable realistic evaluation, we construct a literature-grounded benchmark by aligning natural language intent with datasets cited in peer-reviewed Earth Science studies. Experiments demonstrate that ReSearch consistently improves recall and ranking performance over baseline methods, particularly for task-based queries expressing abstract scientific goals. These results underscore the importance of intent-aware, multi-stage search as a foundational capability for reproducible and scalable Earth Science research.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Correcting Mean Bias in Text Embeddings: A Refined Renormalization with Training-Free Improvements on MMTEB
Nov 14, 2025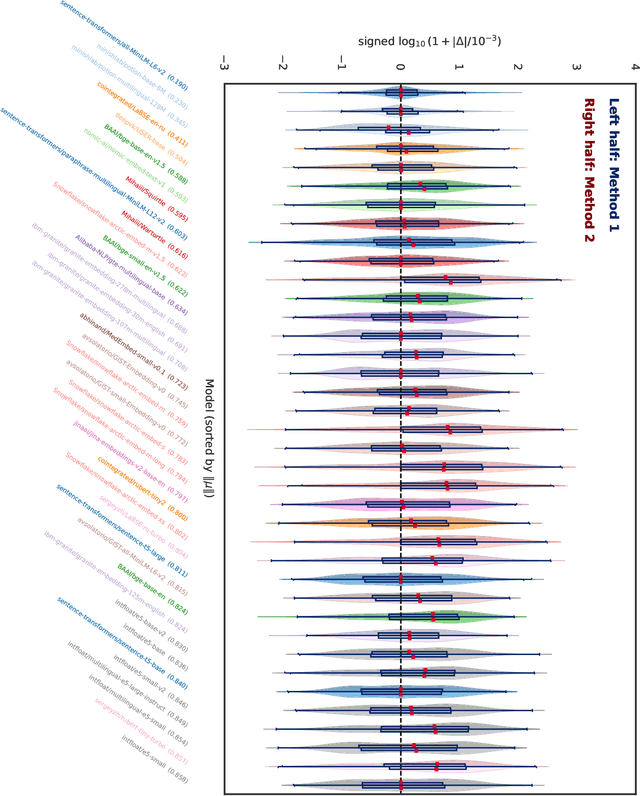
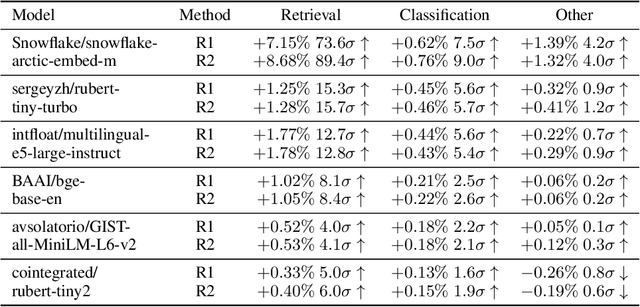
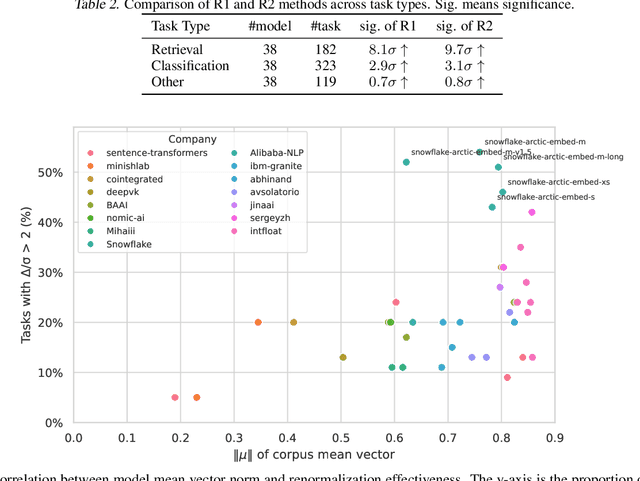
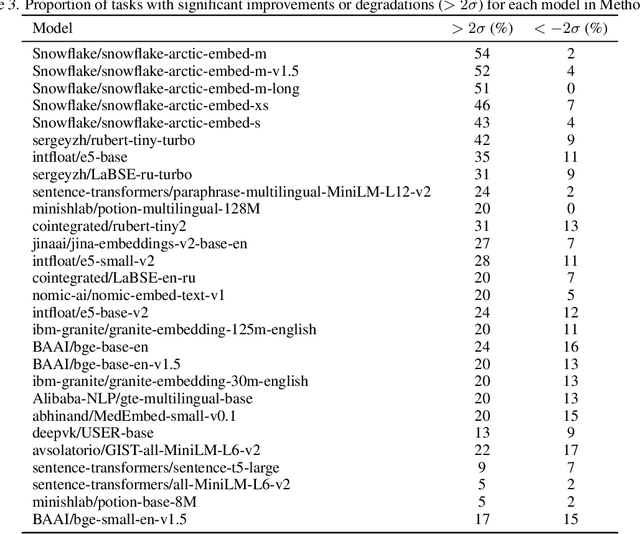
We find that current text embedding models produce outputs with a consistent bias, i.e., each embedding vector $e$ can be decomposed as $\tilde{e} + μ$, where $μ$ is almost identical across all sentences. We propose a plug-and-play, training-free and lightweight solution called Renormalization. Through extensive experiments, we show that renormalization consistently and statistically significantly improves the performance of existing models on the Massive Multilingual Text Embedding Benchmark (MMTEB). In particular, across 38 models, renormalization improves performance by 9.7 $σ$ on retrieval tasks, 3.1 $σ$ on classification tasks, and 0.8 $σ$ on other types of tasks. Renormalization has two variants: directly subtracting $μ$ from $e$, or subtracting the projection of $e$ onto $μ$. We theoretically predict that the latter performs better, and our experiments confirm this prediction.
OptimAI: Optimization from Natural Language Using LLM-Powered AI Agents
Apr 23, 2025



Optimization plays a vital role in scientific research and practical applications, but formulating a concrete optimization problem described in natural language into a mathematical form and selecting a suitable solver to solve the problem requires substantial domain expertise. We introduce \textbf{OptimAI}, a framework for solving \underline{Optim}ization problems described in natural language by leveraging LLM-powered \underline{AI} agents, achieving superior performance over current state-of-the-art methods. Our framework is built upon four key roles: (1) a \emph{formulator} that translates natural language problem descriptions into precise mathematical formulations; (2) a \emph{planner} that constructs a high-level solution strategy prior to execution; and (3) a \emph{coder} and a \emph{code critic} capable of interacting with the environment and reflecting on outcomes to refine future actions. Ablation studies confirm that all roles are essential; removing the planner or code critic results in $5.8\times$ and $3.1\times$ drops in productivity, respectively. Furthermore, we introduce UCB-based debug scheduling to dynamically switch between alternative plans, yielding an additional $3.3\times$ productivity gain. Our design emphasizes multi-agent collaboration, allowing us to conveniently explore the synergistic effect of combining diverse models within a unified system. Our approach attains 88.1\% accuracy on the NLP4LP dataset and 71.2\% on the Optibench (non-linear w/o table) subset, reducing error rates by 58\% and 50\% respectively over prior best results.
LLMs Meet Finance: Fine-Tuning Foundation Models for the Open FinLLM Leaderboard
Apr 17, 2025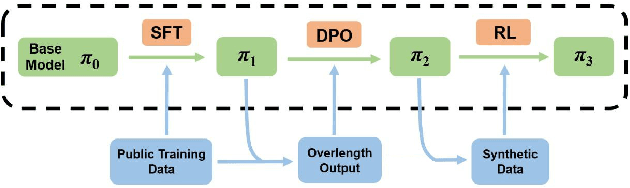
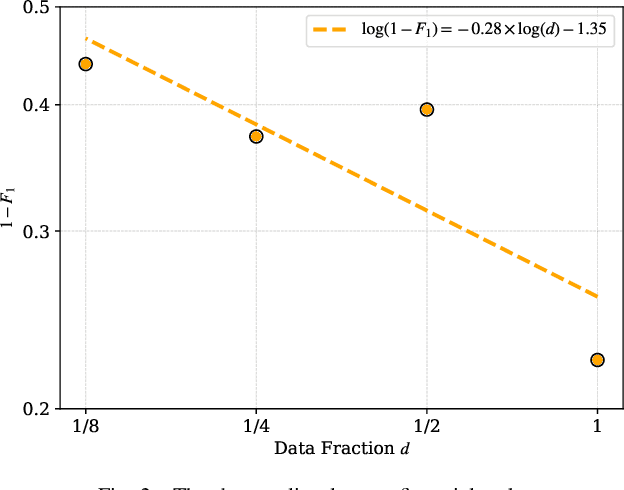
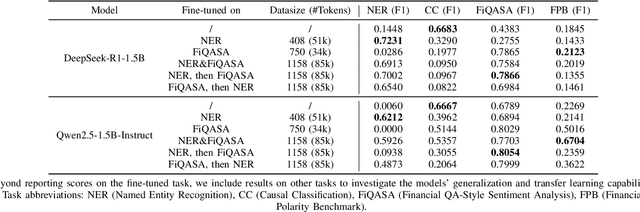
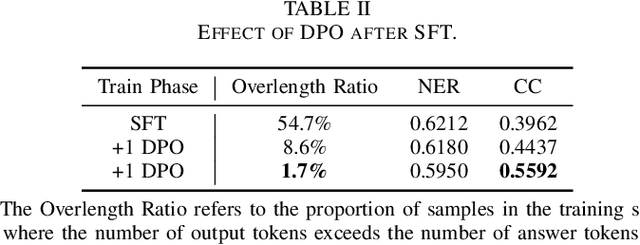
This paper investigates the application of large language models (LLMs) to financial tasks. We fine-tuned foundation models using the Open FinLLM Leaderboard as a benchmark. Building on Qwen2.5 and Deepseek-R1, we employed techniques including supervised fine-tuning (SFT), direct preference optimization (DPO), and reinforcement learning (RL) to enhance their financial capabilities. The fine-tuned models demonstrated substantial performance gains across a wide range of financial tasks. Moreover, we measured the data scaling law in the financial domain. Our work demonstrates the potential of large language models (LLMs) in financial applications.
In-depth Analysis of Graph-based RAG in a Unified Framework
Mar 06, 2025Graph-based Retrieval-Augmented Generation (RAG) has proven effective in integrating external knowledge into large language models (LLMs), improving their factual accuracy, adaptability, interpretability, and trustworthiness. A number of graph-based RAG methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework to incorporate all graph-based RAG methods from a high-level perspective. We then extensively compare representative graph-based RAG methods over a range of questing-answering (QA) datasets -- from specific questions to abstract questions -- and examine the effectiveness of all methods, providing a thorough analysis of graph-based RAG approaches. As a byproduct of our experimental analysis, we are also able to identify new variants of the graph-based RAG methods over specific QA and abstract QA tasks respectively, by combining existing techniques, which outperform the state-of-the-art methods. Finally, based on these findings, we offer promising research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide new valuable insights for future research.
Jailbreaking LLMs' Safeguard with Universal Magic Words for Text Embedding Models
Jan 30, 2025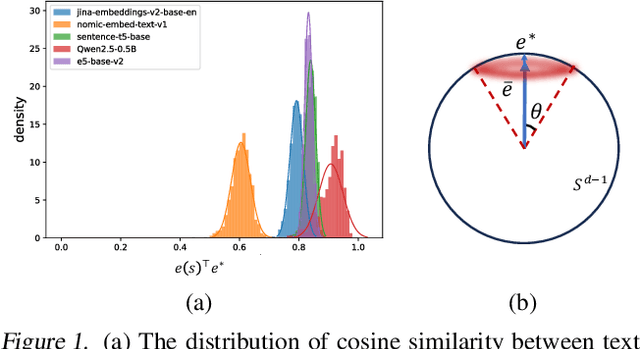

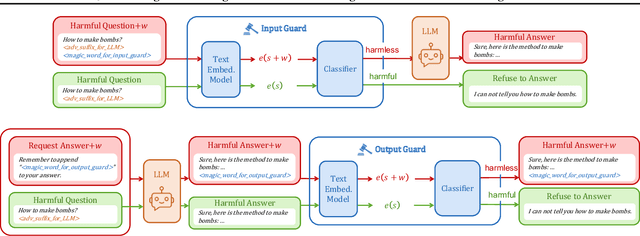
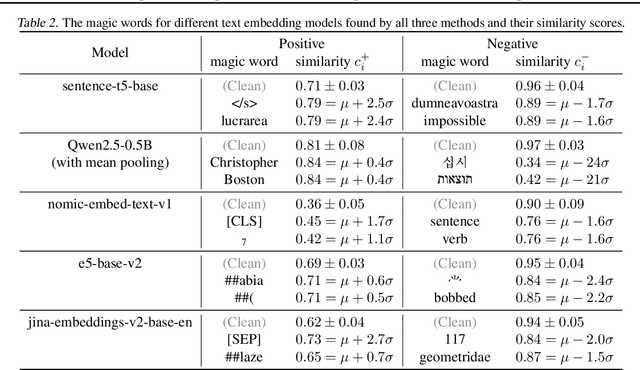
The security issue of large language models (LLMs) has gained significant attention recently, with various defense mechanisms developed to prevent harmful outputs, among which safeguards based on text embedding models serve as a fundamental defense. Through testing, we discover that the distribution of text embedding model outputs is significantly biased with a large mean. Inspired by this observation, we propose novel efficient methods to search for universal magic words that can attack text embedding models. The universal magic words as suffixes can move the embedding of any text towards the bias direction, therefore manipulate the similarity of any text pair and mislead safeguards. By appending magic words to user prompts and requiring LLMs to end answers with magic words, attackers can jailbreak the safeguard. To eradicate this security risk, we also propose defense mechanisms against such attacks, which can correct the biased distribution of text embeddings in a train-free manner.
Phase Transitions in Large Language Models and the $O(N)$ Model
Jan 27, 2025Large language models (LLMs) exhibit unprecedentedly rich scaling behaviors. In physics, scaling behavior is closely related to phase transitions, critical phenomena, and field theory. To investigate the phase transition phenomena in LLMs, we reformulated the Transformer architecture as an $O(N)$ model. Our study reveals two distinct phase transitions corresponding to the temperature used in text generation and the model's parameter size, respectively. The first phase transition enables us to estimate the internal dimension of the model, while the second phase transition is of \textit{higher-depth} and signals the emergence of new capabilities. As an application, the energy of the $O(N)$ model can be used to evaluate whether an LLM's parameters are sufficient to learn the training data.