 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-depth Analysis of Graph-based RAG in a Unified Framework
Mar 06, 2025Graph-based Retrieval-Augmented Generation (RAG) has proven effective in integrating external knowledge into large language models (LLMs), improving their factual accuracy, adaptability, interpretability, and trustworthiness. A number of graph-based RAG methods have been proposed in the literature. However, these methods have not been systematically and comprehensively compared under the same experimental settings. In this paper, we first summarize a unified framework to incorporate all graph-based RAG methods from a high-level perspective. We then extensively compare representative graph-based RAG methods over a range of questing-answering (QA) datasets -- from specific questions to abstract questions -- and examine the effectiveness of all methods, providing a thorough analysis of graph-based RAG approaches. As a byproduct of our experimental analysis, we are also able to identify new variants of the graph-based RAG methods over specific QA and abstract QA tasks respectively, by combining existing techniques, which outperform the state-of-the-art methods. Finally, based on these findings, we offer promising research opportunities. We believe that a deeper understanding of the behavior of existing methods can provide new valuable insights for future research.
Personalized Federated Learning with Local Attention
Apr 14, 2023Federated Learning (FL) aims to learn a single global model that enables the central server to help the model training in local clients without accessing their local data. The key challenge of FL is the heterogeneity of local data in different clients, such as heterogeneous label distribution and feature shift, which could lead to significant performance degradation of the learned models. Although many studies have been proposed to address the heterogeneous label distribution problem, few studies attempt to explore the feature shift issue. To address this issue, we propose a simple yet effective algorithm, namely \textbf{p}ersonalized \textbf{Fed}erated learning with \textbf{L}ocal \textbf{A}ttention (pFedLA), by incorporating the attention mechanism into personalized models of clients while keeping the attention blocks client-specific. Specifically, two modules are proposed in pFedLA, i.e., the personalized single attention module and the personalized hybrid attention module. In addition, the proposed pFedLA method is quite flexible and general as it can be incorporated into any FL method to improve their performance without introducing additional communication costs. Extensive experiments demonstrate that the proposed pFedLA method can boost the performance of state-of-the-art FL methods on different tasks such as image classification and object detection tasks.
A Simple General Approach to Balance Task Difficulty in Multi-Task Learning
Feb 12, 2020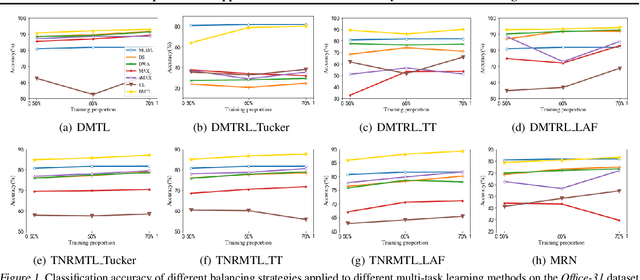

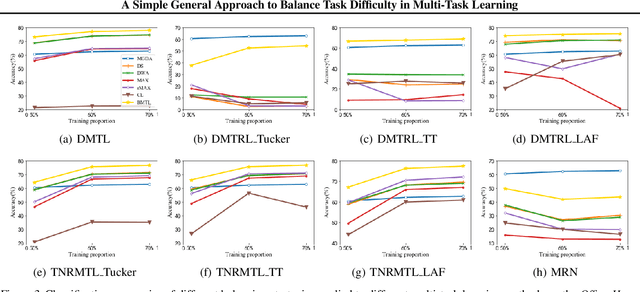
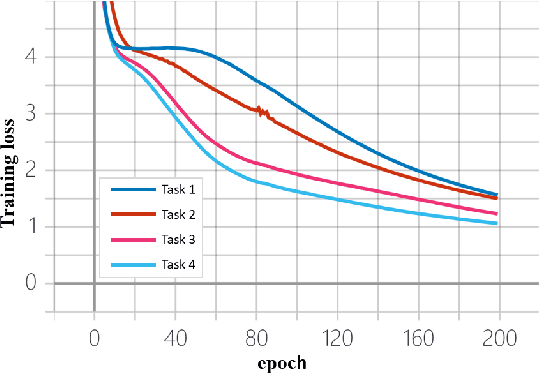
In multi-task learning, difficulty levels of different tasks are varying. There are many works to handle this situation and we classify them into five categories, including the direct sum approach, the weighted sum approach, the maximum approach, the curriculum learning approach, and the multi-objective optimization approach. Those approaches have their own limitations, for example, using manually designed rules to update task weights, non-smooth objective function, and failing to incorporate other functions than training losses. In this paper, to alleviate those limitations, we propose a Balanced Multi-Task Learning (BMTL) framework. Different from existing studies which rely on task weighting, the BMTL framework proposes to transform the training loss of each task to balance difficulty levels among tasks based on an intuitive idea that tasks with larger training losses will receive more attention during the optimization procedure. We analyze the transformation function and derive necessary conditions. The proposed BMTL framework is very simple and it can be combined with most multi-task learning models. Empirical studies show the state-of-the-art performance of the proposed BMTL framework.