 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixelwise Low-rank Approximation based Partial Label Learning for Hyperspectral Image Classification
May 27, 2024



Insufficient prior knowledge of a captured hyperspectral image (HSI) scene may lead the experts or the automatic labeling systems to offer incorrect labels or ambiguous labels (i.e., assigning each training sample to a group of candidate labels, among which only one of them is valid; this is also known as partial label learning) during the labeling process. Accordingly, how to learn from such data with ambiguous labels is a problem of great practical importance. In this paper, we propose a novel superpixelwise low-rank approximation (LRA)-based partial label learning method, namely SLAP, which is the first to take into account partial label learning in HSI classification. SLAP is mainly composed of two phases: disambiguating the training labels and acquiring the predictive model. Specifically, in the first phase, we propose a superpixelwise LRA-based model, preparing the affinity graph for the subsequent label propagation process while extracting the discriminative representation to enhance the following classification task of the second phase. Then to disambiguate the training labels, label propagation propagates the labeling information via the affinity graph of training pixels. In the second phase, we take advantage of the resulting disambiguated training labels and the discriminative representations to enhance the classification performance. The extensive experiments validate the advantage of the proposed SLAP method over state-of-the-art methods.
Personalized Federated Learning with Local Attention
Apr 14, 2023Federated Learning (FL) aims to learn a single global model that enables the central server to help the model training in local clients without accessing their local data. The key challenge of FL is the heterogeneity of local data in different clients, such as heterogeneous label distribution and feature shift, which could lead to significant performance degradation of the learned models. Although many studies have been proposed to address the heterogeneous label distribution problem, few studies attempt to explore the feature shift issue. To address this issue, we propose a simple yet effective algorithm, namely \textbf{p}ersonalized \textbf{Fed}erated learning with \textbf{L}ocal \textbf{A}ttention (pFedLA), by incorporating the attention mechanism into personalized models of clients while keeping the attention blocks client-specific. Specifically, two modules are proposed in pFedLA, i.e., the personalized single attention module and the personalized hybrid attention module. In addition, the proposed pFedLA method is quite flexible and general as it can be incorporated into any FL method to improve their performance without introducing additional communication costs. Extensive experiments demonstrate that the proposed pFedLA method can boost the performance of state-of-the-art FL methods on different tasks such as image classification and object detection tasks.
Superpixel-guided Discriminative Low-rank Representation of Hyperspectral Images for Classification
Aug 25, 2021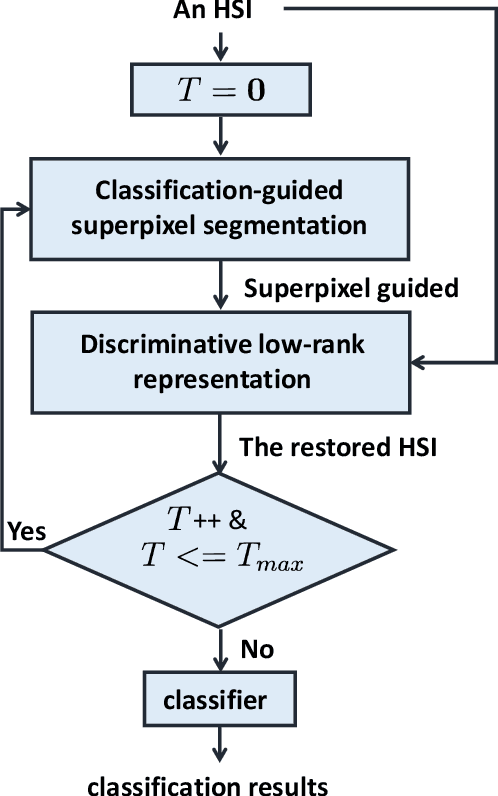
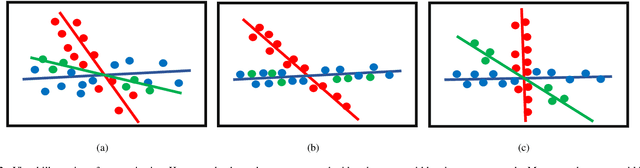
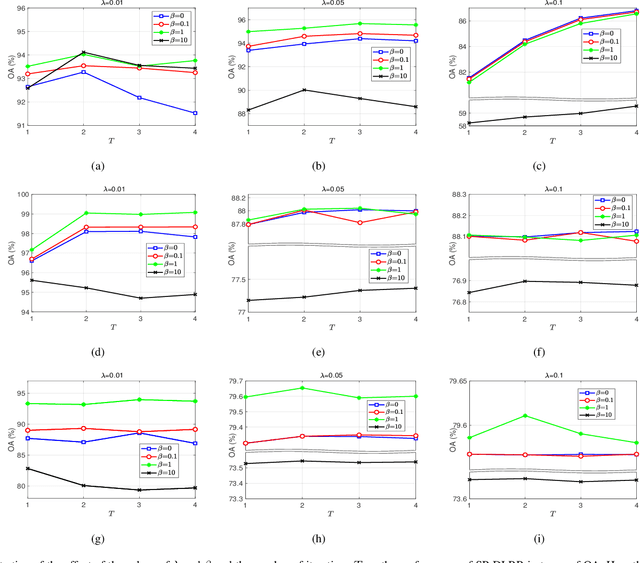
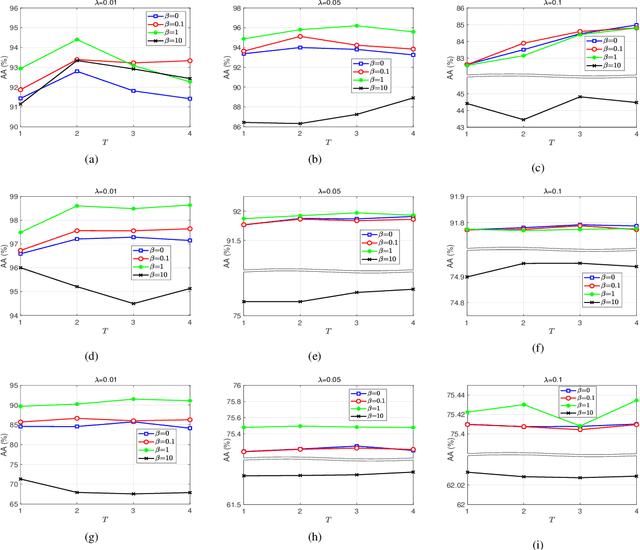
In this paper, we propose a novel classification scheme for the remotely sensed hyperspectral image (HSI), namely SP-DLRR, by comprehensively exploring its unique characteristics, including the local spatial information and low-rankness. SP-DLRR is mainly composed of two modules, i.e., the classification-guided superpixel segmentation and the discriminative low-rank representation, which are iteratively conducted. Specifically, by utilizing the local spatial information and incorporating the predictions from a typical classifier, the first module segments pixels of an input HSI (or its restoration generated by the second module) into superpixels. According to the resulting superpixels, the pixels of the input HSI are then grouped into clusters and fed into our novel discriminative low-rank representation model with an effective numerical solution. Such a model is capable of increasing the intra-class similarity by suppressing the spectral variations locally while promoting the inter-class discriminability globally, leading to a restored HSI with more discriminative pixels. Experimental results on three benchmark datasets demonstrate the significant superiority of SP-DLRR over state-of-the-art methods, especially for the case with an extremely limited number of training pixels.