 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReIDMamba: Learning Discriminative Features with Visual State Space Model for Person Re-Identification
Nov 11, 2025Extracting robust discriminative features is a critical challenge in person re-identification (ReID). While Transformer-based methods have successfully addressed some limitations of convolutional neural networks (CNNs), such as their local processing nature and information loss resulting from convolution and downsampling operations, they still face the scalability issue due to the quadratic increase in memory and computational requirements with the length of the input sequence. To overcome this, we propose a pure Mamba-based person ReID framework named ReIDMamba. Specifically, we have designed a Mamba-based strong baseline that effectively leverages fine-grained, discriminative global features by introducing multiple class tokens. To further enhance robust features learning within Mamba, we have carefully designed two novel techniques. First, the multi-granularity feature extractor (MGFE) module, designed with a multi-branch architecture and class token fusion, effectively forms multi-granularity features, enhancing both discrimination ability and fine-grained coverage. Second, the ranking-aware triplet regularization (RATR) is introduced to reduce redundancy in features from multiple branches, enhancing the diversity of multi-granularity features by incorporating both intra-class and inter-class diversity constraints, thus ensuring the robustness of person features. To our knowledge, this is the pioneering work that integrates a purely Mamba-driven approach into ReID research. Our proposed ReIDMamba model boasts only one-third the parameters of TransReID, along with lower GPU memory usage and faster inference throughput. Experimental results demonstrate ReIDMamba's superior and promising performance, achieving state-of-the-art performance on five person ReID benchmarks. Code is available at https://github.com/GuHY777/ReIDMamba.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
SLCGC: A lightweight Self-supervised Low-pass Contrastive Graph Clustering Network for Hyperspectral Images
Feb 05, 2025Self-supervised hyperspectral image (HSI) clustering remains a fundamental yet challenging task due to the absence of labeled data and the inherent complexity of spatial-spectral interactions. While recent advancements have explored innovative approaches, existing methods face critical limitations in clustering accuracy, feature discriminability, computational efficiency, and robustness to noise, hindering their practical deployment. In this paper, a self-supervised efficient low-pass contrastive graph clustering (SLCGC) is introduced for HSIs. Our approach begins with homogeneous region generation, which aggregates pixels into spectrally consistent regions to preserve local spatial-spectral coherence while drastically reducing graph complexity. We then construct a structural graph using an adjacency matrix A and introduce a low-pass graph denoising mechanism to suppress high-frequency noise in the graph topology, ensuring stable feature propagation. A dual-branch graph contrastive learning module is developed, where Gaussian noise perturbations generate augmented views through two multilayer perceptrons (MLPs), and a cross-view contrastive loss enforces structural consistency between views to learn noise-invariant representations. Finally, latent embeddings optimized by this process are clustered via K-means. Extensive experiments and repeated comparative analysis have verified that our SLCGC contains high clustering accuracy, low computational complexity, and strong robustness. The code source will be available at https://github.com/DY-HYX.
Adaptive Homophily Clustering: Structure Homophily Graph Learning with Adaptive Filter for Hyperspectral Image
Jan 07, 2025



Hyperspectral image (HSI) clustering has been a fundamental but challenging task with zero training labels. Currently, some deep graph clustering methods have been successfully explored for HSI due to their outstanding performance in effective spatial structural information encoding. Nevertheless, insufficient structural information utilization, poor feature presentation ability, and weak graph update capability limit their performance. Thus, in this paper, a homophily structure graph learning with an adaptive filter clustering method (AHSGC) for HSI is proposed. Specifically, homogeneous region generation is first developed for HSI processing and constructing the original graph. Afterward, an adaptive filter graph encoder is designed to adaptively capture the high and low frequency features on the graph for subsequence processing. Then, a graph embedding clustering self-training decoder is developed with KL Divergence, with which the pseudo-label is generated for network training. Meanwhile, homophily-enhanced structure learning is introduced to update the graph according to the clustering task, in which the orient correlation estimation is adopted to estimate the node connection, and graph edge sparsification is designed to adjust the edges in the graph dynamically. Finally, a joint network optimization is introduced to achieve network self-training and update the graph. The K-means is adopted to express the latent features. Extensive experiments and repeated comparative analysis have verified that our AHSGC contains high clustering accuracy, low computational complexity, and strong robustness. The code source will be available at https://github.com/DY-HYX.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
GraphMamba: An Efficient Graph Structure Learning Vision Mamba for Hyperspectral Image Classification
Jul 11, 2024



Efficient extraction of spectral sequences and geospatial information has always been a hot topic in hyperspectral image classification. In terms of spectral sequence feature capture, RNN and Transformer have become mainstream classification frameworks due to their long-range feature capture capabilities. In terms of spatial information aggregation, CNN enhances the receptive field to retain integrated spatial information as much as possible. However, the spectral feature-capturing architectures exhibit low computational efficiency, and CNNs lack the flexibility to perceive spatial contextual information. To address these issues, this paper proposes GraphMamba--an efficient graph structure learning vision Mamba classification framework that fully considers HSI characteristics to achieve deep spatial-spectral information mining. Specifically, we propose a novel hyperspectral visual GraphMamba processing paradigm (HVGM) that preserves spatial-spectral features by constructing spatial-spectral cubes and utilizes linear spectral encoding to enhance the operability of subsequent tasks. The core components of GraphMamba include the HyperMamba module for improving computational efficiency and the SpectralGCN module for adaptive spatial context awareness. The HyperMamba mitigates clutter interference by employing the global mask (GM) and introduces a parallel training inference architecture to alleviate computational bottlenecks. The SpatialGCN incorporates weighted multi-hop aggregation (WMA) spatial encoding to focus on highly correlated spatial structural features, thus flexibly aggregating contextual information while mitigating spatial noise interference. Extensive experiments were conducted on three different scales of real HSI datasets, and compared with the state-of-the-art classification frameworks, GraphMamba achieved optimal performance.
Superpixelwise Low-rank Approximation based Partial Label Learning for Hyperspectral Image Classification
May 27, 2024



Insufficient prior knowledge of a captured hyperspectral image (HSI) scene may lead the experts or the automatic labeling systems to offer incorrect labels or ambiguous labels (i.e., assigning each training sample to a group of candidate labels, among which only one of them is valid; this is also known as partial label learning) during the labeling process. Accordingly, how to learn from such data with ambiguous labels is a problem of great practical importance. In this paper, we propose a novel superpixelwise low-rank approximation (LRA)-based partial label learning method, namely SLAP, which is the first to take into account partial label learning in HSI classification. SLAP is mainly composed of two phases: disambiguating the training labels and acquiring the predictive model. Specifically, in the first phase, we propose a superpixelwise LRA-based model, preparing the affinity graph for the subsequent label propagation process while extracting the discriminative representation to enhance the following classification task of the second phase. Then to disambiguate the training labels, label propagation propagates the labeling information via the affinity graph of training pixels. In the second phase, we take advantage of the resulting disambiguated training labels and the discriminative representations to enhance the classification performance. The extensive experiments validate the advantage of the proposed SLAP method over state-of-the-art methods.
Fully Linear Graph Convolutional Networks for Semi-Supervised Learning and Clustering
Nov 15, 2021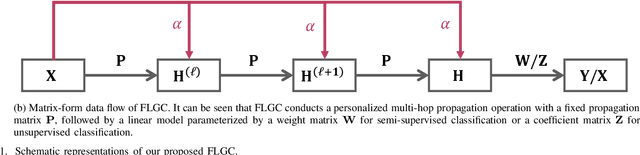
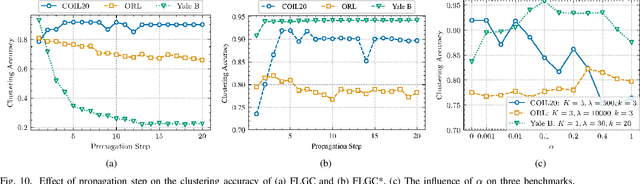
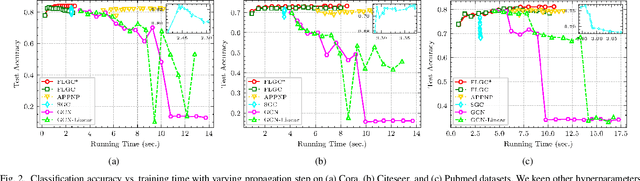
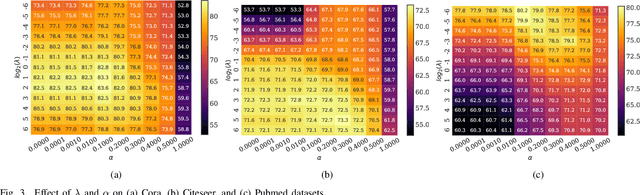
This paper presents FLGC, a simple yet effective fully linear graph convolutional network for semi-supervised and unsupervised learning. Instead of using gradient descent, we train FLGC based on computing a global optimal closed-form solution with a decoupled procedure, resulting in a generalized linear framework and making it easier to implement, train, and apply. We show that (1) FLGC is powerful to deal with both graph-structured data and regular data, (2) training graph convolutional models with closed-form solutions improve computational efficiency without degrading performance, and (3) FLGC acts as a natural generalization of classic linear models in the non-Euclidean domain, e.g., ridge regression and subspace clustering. Furthermore, we implement a semi-supervised FLGC and an unsupervised FLGC by introducing an initial residual strategy, enabling FLGC to aggregate long-range neighborhoods and alleviate over-smoothing. We compare our semi-supervised and unsupervised FLGCs against many state-of-the-art methods on a variety of classification and clustering benchmarks, demonstrating that the proposed FLGC models consistently outperform previous methods in terms of accuracy, robustness, and learning efficiency. The core code of our FLGC is released at https://github.com/AngryCai/FLGC.
Anti-aliasing Semantic Reconstruction for Few-Shot Semantic Segmentation
Jun 01, 2021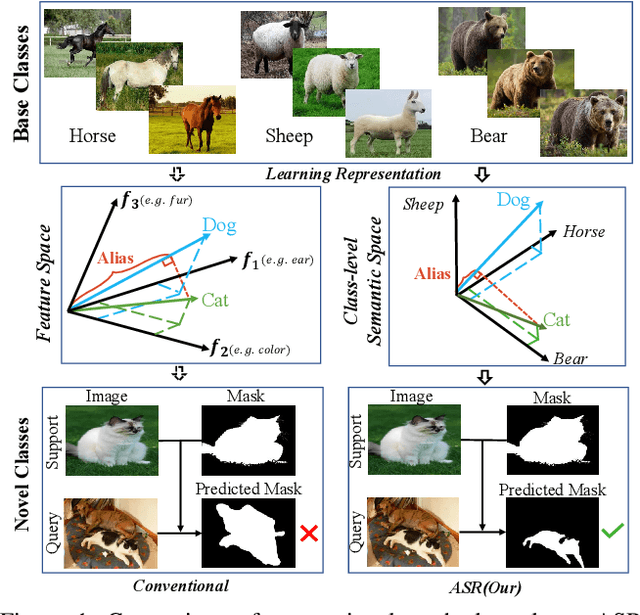

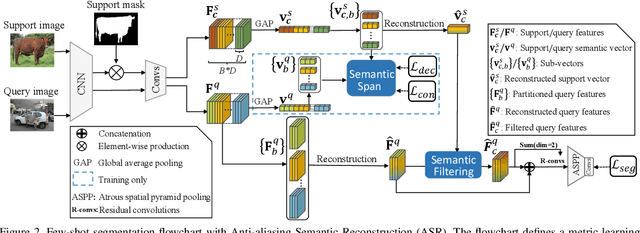

Encouraging progress in few-shot semantic segmentation has been made by leveraging features learned upon base classes with sufficient training data to represent novel classes with few-shot examples. However, this feature sharing mechanism inevitably causes semantic aliasing between novel classes when they have similar compositions of semantic concepts. In this paper, we reformulate few-shot segmentation as a semantic reconstruction problem, and convert base class features into a series of basis vectors which span a class-level semantic space for novel class reconstruction. By introducing contrastive loss, we maximize the orthogonality of basis vectors while minimizing semantic aliasing between classes. Within the reconstructed representation space, we further suppress interference from other classes by projecting query features to the support vector for precise semantic activation. Our proposed approach, referred to as anti-aliasing semantic reconstruction (ASR), provides a systematic yet interpretable solution for few-shot learning problems. Extensive experiments on PASCAL VOC and MS COCO datasets show that ASR achieves strong results compared with the prior works.
Effective Fusion Factor in FPN for Tiny Object Detection
Nov 09, 2020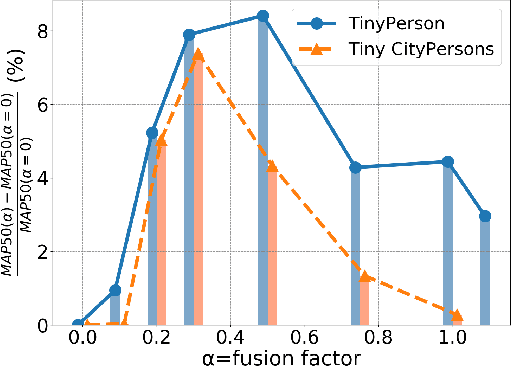
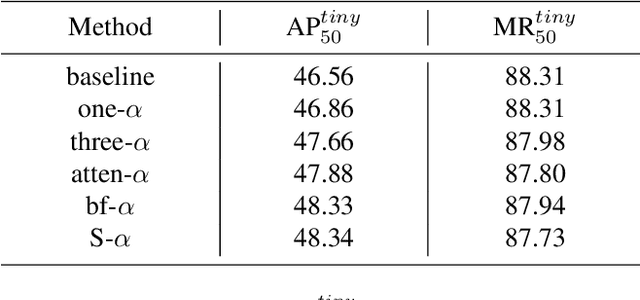
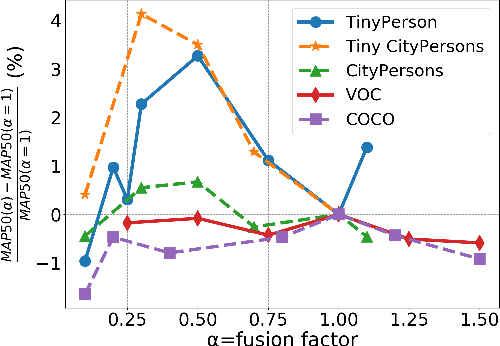
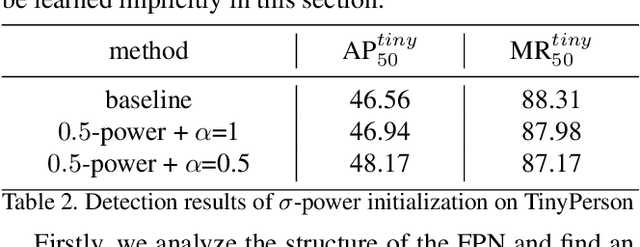
FPN-based detectors have made significant progress in general object detection, e.g., MS COCO and PASCAL VOC. However, these detectors fail in certain application scenarios, e.g., tiny object detection. In this paper, we argue that the top-down connections between adjacent layers in FPN bring two-side influences for tiny object detection, not only positive. We propose a novel concept, fusion factor, to control information that deep layers deliver to shallow layers, for adapting FPN to tiny object detection. After series of experiments and analysis, we explore how to estimate an effective value of fusion factor for a particular dataset by a statistical method. The estimation is dependent on the number of objects distributed in each layer. Comprehensive experiments are conducted on tiny object detection datasets, e.g., TinyPerson and Tiny CityPersons. Our results show that when configuring FPN with a proper fusion factor, the network is able to achieve significant performance gains over the baseline on tiny object detection datasets. Codes and models will be released.