 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConflict-Aware Additive Guidance for Flow Models under Compositional Rewards
May 20, 2026Inference-time guided sampling steers state-of-the-art diffusion and flow models without fine-tuning by interpreting the generation process as a controllable trajectory. This provides a simple and flexible way to inject external constraints (e.g., cost functions or pre-trained verifiers) for controlled generation. However, existing methods often fail when composing multiple constraints simultaneously, which leads to deviations from the true data manifold. In this work, we identify root causes of this off-manifold drift and find that the approximation error scales severely with gradient misalignment. Building on these findings, we propose Conflict-Aware Additive Guidance ($g^\text{car}$), a lightweight and learnable method, which actively rectifies off-manifold drift by dynamically detecting and resolving gradient conflicts. We validate $g^\text{car}$ across diverse domains, ranging from synthetic datasets and image editing to generative decision-making for planning and control. Our results demonstrate that $g^\text{car}$ effectively rectifies off-manifold drift, surpassing baselines in generation fidelity while using light compute. Code is available at https://github.com/yuxuehui/CAR-guidance.
SAPNet++: Evolving Point-Prompted Instance Segmentation with Semantic and Spatial Awareness
Feb 25, 2026Single-point annotation is increasingly prominent in visual tasks for labeling cost reduction. However, it challenges tasks requiring high precision, such as the point-prompted instance segmentation (PPIS) task, which aims to estimate precise masks using single-point prompts to train a segmentation network. Due to the constraints of point annotations, granularity ambiguity and boundary uncertainty arise the difficulty distinguishing between different levels of detail (eg. whole object vs. parts) and the challenge of precisely delineating object boundaries. Previous works have usually inherited the paradigm of mask generation along with proposal selection to achieve PPIS. However, proposal selection relies solely on category information, failing to resolve the ambiguity of different granularity. Furthermore, mask generators offer only finite discrete solutions that often deviate from actual masks, particularly at boundaries. To address these issues, we propose the Semantic-Aware Point-Prompted Instance Segmentation Network (SAPNet). It integrates Point Distance Guidance and Box Mining Strategy to tackle group and local issues caused by the point's granularity ambiguity. Additionally, we incorporate completeness scores within proposals to add spatial granularity awareness, enhancing multiple instance learning (MIL) in proposal selection termed S-MIL. The Multi-level Affinity Refinement conveys pixel and semantic clues, narrowing boundary uncertainty during mask refinement. These modules culminate in SAPNet++, mitigating point prompt's granularity ambiguity and boundary uncertainty and significantly improving segmentation performance. Extensive experiments on four challenging datasets validate the effectiveness of our methods, highlighting the potential to advance PPIS.
* 18 pages
Towards Any-Quality Image Segmentation via Generative and Adaptive Latent Space Enhancement
Jan 05, 2026Segment Anything Models (SAMs), known for their exceptional zero-shot segmentation performance, have garnered significant attention in the research community. Nevertheless, their performance drops significantly on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM++, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Additionally, to improve compatibility between the pre-trained diffusion model and the segmentation framework, we introduce two techniques, i.e., Feature Distribution Alignment (FDA) and Channel Replication and Expansion (CRE). However, the above components lack explicit guidance regarding the degree of degradation. The model is forced to implicitly fit a complex noise distribution that spans conditions from mild noise to severe artifacts, which substantially increases the learning burden and leads to suboptimal reconstructions. To address this issue, we further introduce a Degradation-aware Adaptive Enhancement (DAE) mechanism. The key principle of DAE is to decouple the reconstruction process for arbitrary-quality features into two stages: degradation-level prediction and degradation-aware reconstruction. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. Extensive experiments demonstrate that GleSAM++ significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM++ also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
AD^2-Bench: A Hierarchical CoT Benchmark for MLLM in Autonomous Driving under Adverse Conditions
Jun 11, 2025



Chain-of-Thought (CoT) reasoning has emerged as a powerful approach to enhance the structured, multi-step decision-making capabilities of Multi-Modal Large Models (MLLMs), is particularly crucial for autonomous driving with adverse weather conditions and complex traffic environments. However, existing benchmarks have largely overlooked the need for rigorous evaluation of CoT processes in these specific and challenging scenarios. To address this critical gap, we introduce AD^2-Bench, the first Chain-of-Thought benchmark specifically designed for autonomous driving with adverse weather and complex scenes. AD^2-Bench is meticulously constructed to fulfill three key criteria: comprehensive data coverage across diverse adverse environments, fine-grained annotations that support multi-step reasoning, and a dedicated evaluation framework tailored for assessing CoT performance. The core contribution of AD^2-Bench is its extensive collection of over 5.4k high-quality, manually annotated CoT instances. Each intermediate reasoning step in these annotations is treated as an atomic unit with explicit ground truth, enabling unprecedented fine-grained analysis of MLLMs' inferential processes under text-level, point-level, and region-level visual prompts. Our comprehensive evaluation of state-of-the-art MLLMs on AD^2-Bench reveals accuracy below 60%, highlighting the benchmark's difficulty and the need to advance robust, interpretable end-to-end autonomous driving systems. AD^2-Bench thus provides a standardized evaluation platform, driving research forward by improving MLLMs' reasoning in autonomous driving, making it an invaluable resource.
P2Object: Single Point Supervised Object Detection and Instance Segmentation
Apr 10, 2025Object recognition using single-point supervision has attracted increasing attention recently. However, the performance gap compared with fully-supervised algorithms remains large. Previous works generated class-agnostic \textbf{\textit{proposals in an image}} offline and then treated mixed candidates as a single bag, putting a huge burden on multiple instance learning (MIL). In this paper, we introduce Point-to-Box Network (P2BNet), which constructs balanced \textbf{\textit{instance-level proposal bags}} by generating proposals in an anchor-like way and refining the proposals in a coarse-to-fine paradigm. Through further research, we find that the bag of proposals, either at the image level or the instance level, is established on discrete box sampling. This leads the pseudo box estimation into a sub-optimal solution, resulting in the truncation of object boundaries or the excessive inclusion of background. Hence, we conduct a series exploration of discrete-to-continuous optimization, yielding P2BNet++ and Point-to-Mask Network (P2MNet). P2BNet++ conducts an approximately continuous proposal sampling strategy by better utilizing spatial clues. P2MNet further introduces low-level image information to assist in pixel prediction, and a boundary self-prediction is designed to relieve the limitation of the estimated boxes. Benefiting from the continuous object-aware \textbf{\textit{pixel-level perception}}, P2MNet can generate more precise bounding boxes and generalize to segmentation tasks. Our method largely surpasses the previous methods in terms of the mean average precision on COCO, VOC, SBD, and Cityscapes, demonstrating great potential to bridge the performance gap compared with fully supervised tasks.
Segment Any-Quality Images with Generative Latent Space Enhancement
Mar 16, 2025



Despite their success, Segment Anything Models (SAMs) experience significant performance drops on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Specifically, we adapt the concept of latent diffusion to SAM-based segmentation frameworks and perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation, thereby improving segmentation. Additionally, we introduce two techniques to improve compatibility between the pre-trained diffusion model and the segmentation framework. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. We also construct the LQSeg dataset with a greater diversity of degradation types and levels for training and evaluating the model. Extensive experiments demonstrate that GleSAM significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
ClickTrack: Towards Real-time Interactive Single Object Tracking
Nov 24, 2024



Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
Click; Single Object Tracking; Video Object Segmentation; Real-time Interaction
Nov 20, 2024Single object tracking(SOT) relies on precise object bounding box initialization. In this paper, we reconsidered the deficiencies in the current approaches to initializing single object trackers and propose a new paradigm for single object tracking algorithms, ClickTrack, a new paradigm using clicking interaction for real-time scenarios. Moreover, click as an input type inherently lack hierarchical information. To address ambiguity in certain special scenarios, we designed the Guided Click Refiner(GCR), which accepts point and optional textual information as inputs, transforming the point into the bounding box expected by the operator. The bounding box will be used as input of single object trackers. Experiments on LaSOT and GOT-10k benchmarks show that tracker combined with GCR achieves stable performance in real-time interactive scenarios. Furthermore, we explored the integration of GCR into the Segment Anything model(SAM), significantly reducing ambiguity issues when SAM receives point inputs.
SAM-CP: Marrying SAM with Composable Prompts for Versatile Segmentation
Jul 23, 2024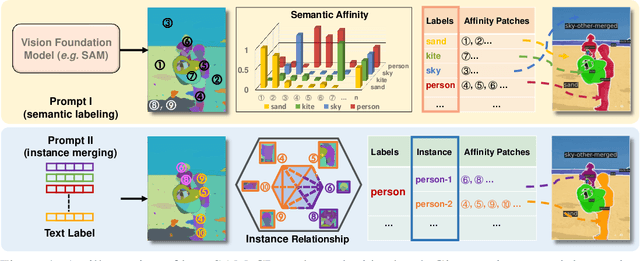
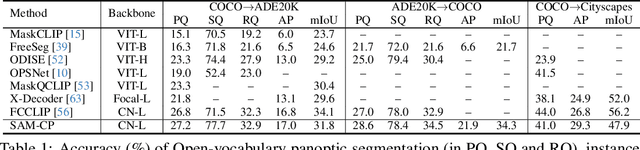

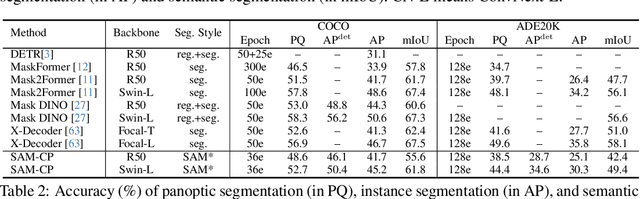
The Segment Anything model (SAM) has shown a generalized ability to group image pixels into patches, but applying it to semantic-aware segmentation still faces major challenges. This paper presents SAM-CP, a simple approach that establishes two types of composable prompts beyond SAM and composes them for versatile segmentation. Specifically, given a set of classes (in texts) and a set of SAM patches, the Type-I prompt judges whether a SAM patch aligns with a text label, and the Type-II prompt judges whether two SAM patches with the same text label also belong to the same instance. To decrease the complexity in dealing with a large number of semantic classes and patches, we establish a unified framework that calculates the affinity between (semantic and instance) queries and SAM patches and merges patches with high affinity to the query. Experiments show that SAM-CP achieves semantic, instance, and panoptic segmentation in both open and closed domains. In particular, it achieves state-of-the-art performance in open-vocabulary segmentation. Our research offers a novel and generalized methodology for equipping vision foundation models like SAM with multi-grained semantic perception abilities.
Skill-aware Mutual Information Optimisation for Generalisation in Reinforcement Learning
Jun 07, 2024



Meta-Reinforcement Learning (Meta-RL) agents can struggle to operate across tasks with varying environmental features that require different optimal skills (i.e., different modes of behaviours). Using context encoders based on contrastive learning to enhance the generalisability of Meta-RL agents is now widely studied but faces challenges such as the requirement for a large sample size, also referred to as the $\log$-$K$ curse. To improve RL generalisation to different tasks, we first introduce Skill-aware Mutual Information (SaMI), an optimisation objective that aids in distinguishing context embeddings according to skills, thereby equipping RL agents with the ability to identify and execute different skills across tasks. We then propose Skill-aware Noise Contrastive Estimation (SaNCE), a $K$-sample estimator used to optimise the SaMI objective. We provide a framework for equipping an RL agent with SaNCE in practice and conduct experimental validation on modified MuJoCo and Panda-gym benchmarks. We empirically find that RL agents that learn by maximising SaMI achieve substantially improved zero-shot generalisation to unseen tasks. Additionally, the context encoder equipped with SaNCE demonstrates greater robustness to reductions in the number of available samples, thus possessing the potential to overcome the $\log$-$K$ curse.