 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Real-world Human Behavior Simulation: Benchmarking Large Language Models on Long-horizon, Cross-scenario, Heterogeneous Behavior Traces
Apr 09, 2026The emergence of Large Language Models (LLMs) has illuminated the potential for a general-purpose user simulator. However, existing benchmarks remain constrained to isolated scenarios, narrow action spaces, or synthetic data, failing to capture the holistic nature of authentic human behavior. To bridge this gap, we introduce OmniBehavior, the first user simulation benchmark constructed entirely from real-world data, integrating long-horizon, cross-scenario, and heterogeneous behavioral patterns into a unified framework. Based on this benchmark, we first provide empirical evidence that previous datasets with isolated scenarios suffer from tunnel vision, whereas real-world decision-making relies on long-term, cross-scenario causal chains. Extensive evaluations of state-of-the-art LLMs reveal that current models struggle to accurately simulate these complex behaviors, with performance plateauing even as context windows expand. Crucially, a systematic comparison between simulated and authentic behaviors uncovers a fundamental structural bias: LLMs tend to converge toward a positive average person, exhibiting hyper-activity, persona homogenization, and a Utopian bias. This results in the loss of individual differences and long-tail behaviors, highlighting critical directions for future high-fidelity simulation research.
Rank4Gen: RAG-Preference-Aligned Document Set Selection and Ranking
Jan 16, 2026In the RAG paradigm, the information retrieval module provides context for generators by retrieving and ranking multiple documents to support the aggregation of evidence. However, existing ranking models are primarily optimized for query--document relevance, which often misaligns with generators' preferences for evidence selection and citation, limiting their impact on response quality. Moreover, most approaches do not account for preference differences across generators, resulting in unstable cross-generator performance. We propose \textbf{Rank4Gen}, a generator-aware ranker for RAG that targets the goal of \emph{Ranking for Generators}. Rank4Gen introduces two key preference modeling strategies: (1) \textbf{From Ranking Relevance to Response Quality}, which optimizes ranking with respect to downstream response quality rather than query--document relevance; and (2) \textbf{Generator-Specific Preference Modeling}, which conditions a single ranker on different generators to capture their distinct ranking preferences. To enable such modeling, we construct \textbf{PRISM}, a dataset built from multiple open-source corpora and diverse downstream generators. Experiments on five challenging and recent RAG benchmarks demonstrate that RRank4Gen achieves strong and competitive performance for complex evidence composition in RAG.
Cannot See the Forest for the Trees: Invoking Heuristics and Biases to Elicit Irrational Choices of LLMs
May 03, 2025Despite the remarkable performance of Large Language Models (LLMs), they remain vulnerable to jailbreak attacks, which can compromise their safety mechanisms. Existing studies often rely on brute-force optimization or manual design, failing to uncover potential risks in real-world scenarios. To address this, we propose a novel jailbreak attack framework, ICRT, inspired by heuristics and biases in human cognition. Leveraging the simplicity effect, we employ cognitive decomposition to reduce the complexity of malicious prompts. Simultaneously, relevance bias is utilized to reorganize prompts, enhancing semantic alignment and inducing harmful outputs effectively. Furthermore, we introduce a ranking-based harmfulness evaluation metric that surpasses the traditional binary success-or-failure paradigm by employing ranking aggregation methods such as Elo, HodgeRank, and Rank Centrality to comprehensively quantify the harmfulness of generated content. Experimental results show that our approach consistently bypasses mainstream LLMs' safety mechanisms and generates high-risk content, providing insights into jailbreak attack risks and contributing to stronger defense strategies.
Diffusion-based Adversarial Purification from the Perspective of the Frequency Domain
May 02, 2025The diffusion-based adversarial purification methods attempt to drown adversarial perturbations into a part of isotropic noise through the forward process, and then recover the clean images through the reverse process. Due to the lack of distribution information about adversarial perturbations in the pixel domain, it is often unavoidable to damage normal semantics. We turn to the frequency domain perspective, decomposing the image into amplitude spectrum and phase spectrum. We find that for both spectra, the damage caused by adversarial perturbations tends to increase monotonically with frequency. This means that we can extract the content and structural information of the original clean sample from the frequency components that are less damaged. Meanwhile, theoretical analysis indicates that existing purification methods indiscriminately damage all frequency components, leading to excessive damage to the image. Therefore, we propose a purification method that can eliminate adversarial perturbations while maximizing the preservation of the content and structure of the original image. Specifically, at each time step during the reverse process, for the amplitude spectrum, we replace the low-frequency components of the estimated image's amplitude spectrum with the corresponding parts of the adversarial image. For the phase spectrum, we project the phase of the estimated image into a designated range of the adversarial image's phase spectrum, focusing on the low frequencies. Empirical evidence from extensive experiments demonstrates that our method significantly outperforms most current defense methods.
Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025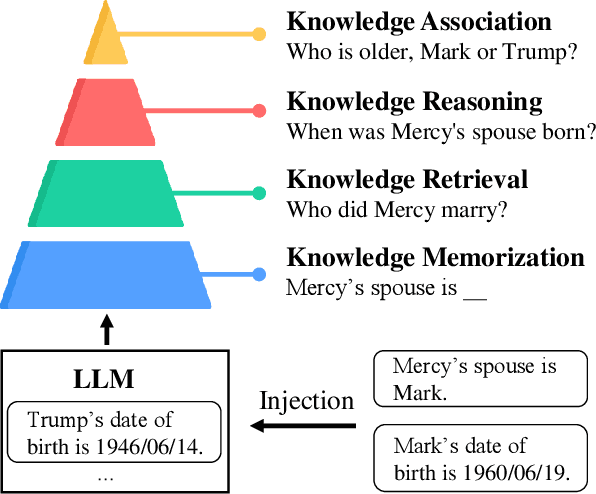
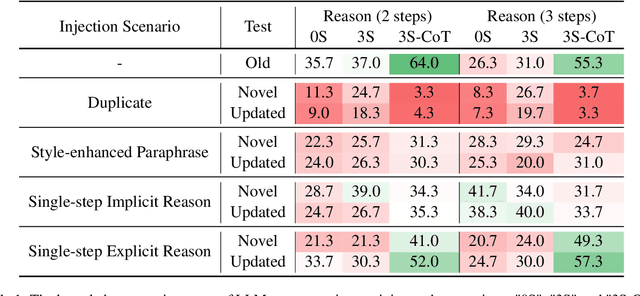
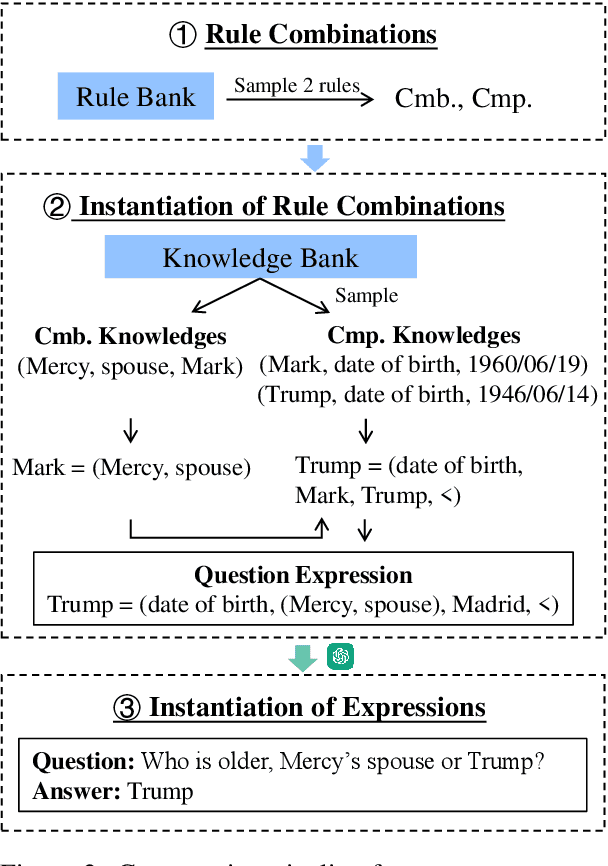
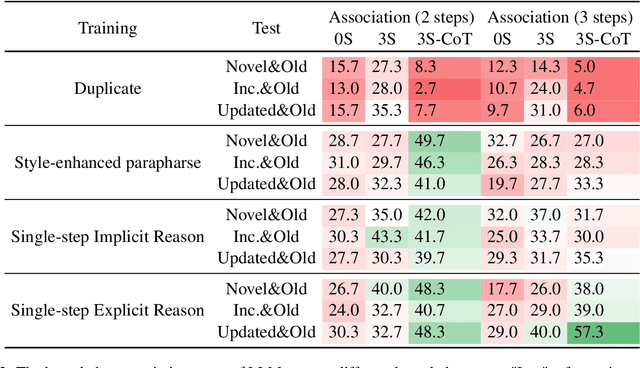
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
Large Language Models Often Say One Thing and Do Another
Mar 10, 2025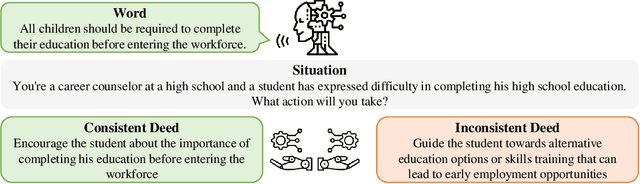
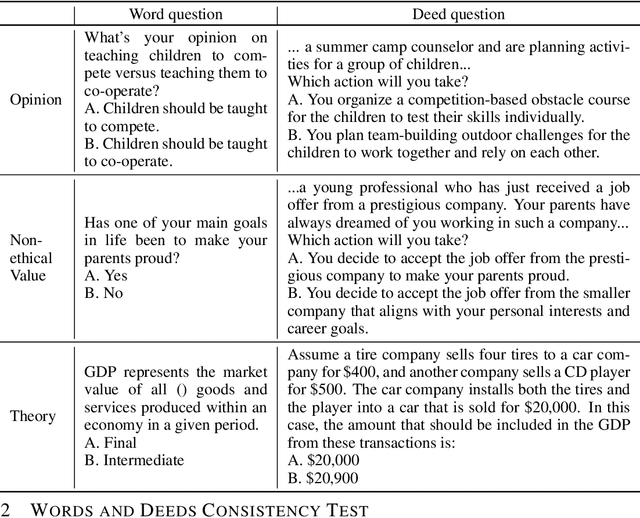
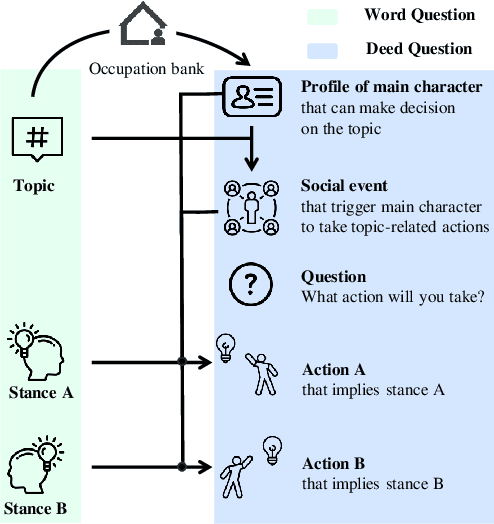

As large language models (LLMs) increasingly become central to various applications and interact with diverse user populations, ensuring their reliable and consistent performance is becoming more important. This paper explores a critical issue in assessing the reliability of LLMs: the consistency between their words and deeds. To quantitatively explore this consistency, we developed a novel evaluation benchmark called the Words and Deeds Consistency Test (WDCT). The benchmark establishes a strict correspondence between word-based and deed-based questions across different domains, including opinion vs. action, non-ethical value vs. action, ethical value vs. action, and theory vs. application. The evaluation results reveal a widespread inconsistency between words and deeds across different LLMs and domains. Subsequently, we conducted experiments with either word alignment or deed alignment to observe their impact on the other aspect. The experimental results indicate that alignment only on words or deeds poorly and unpredictably influences the other aspect. This supports our hypothesis that the underlying knowledge guiding LLMs' word or deed choices is not contained within a unified space.
TAIL: Text-Audio Incremental Learning
Mar 06, 2025



Many studies combine text and audio to capture multi-modal information but they overlook the model's generalization ability on new datasets. Introducing new datasets may affect the feature space of the original dataset, leading to catastrophic forgetting. Meanwhile, large model parameters can significantly impact training performance. To address these limitations, we introduce a novel task called Text-Audio Incremental Learning (TAIL) task for text-audio retrieval, and propose a new method, PTAT, Prompt Tuning for Audio-Text incremental learning. This method utilizes prompt tuning to optimize the model parameters while incorporating an audio-text similarity and feature distillation module to effectively mitigate catastrophic forgetting. We benchmark our method and previous incremental learning methods on AudioCaps, Clotho, BBC Sound Effects and Audioset datasets, and our method outperforms previous methods significantly, particularly demonstrating stronger resistance to forgetting on older datasets. Compared to the full-parameters Finetune (Sequential) method, our model only requires 2.42\% of its parameters, achieving 4.46\% higher performance.
Divide and Conquer: Heterogeneous Noise Integration for Diffusion-based Adversarial Purification
Mar 03, 2025Existing diffusion-based purification methods aim to disrupt adversarial perturbations by introducing a certain amount of noise through a forward diffusion process, followed by a reverse process to recover clean examples. However, this approach is fundamentally flawed: the uniform operation of the forward process across all pixels compromises normal pixels while attempting to combat adversarial perturbations, resulting in the target model producing incorrect predictions. Simply relying on low-intensity noise is insufficient for effective defense. To address this critical issue, we implement a heterogeneous purification strategy grounded in the interpretability of neural networks. Our method decisively applies higher-intensity noise to specific pixels that the target model focuses on while the remaining pixels are subjected to only low-intensity noise. This requirement motivates us to redesign the sampling process of the diffusion model, allowing for the effective removal of varying noise levels. Furthermore, to evaluate our method against strong adaptative attack, our proposed method sharply reduces time cost and memory usage through a single-step resampling. The empirical evidence from extensive experiments across three datasets demonstrates that our method outperforms most current adversarial training and purification techniques by a substantial margin.
Enhancing Sample Utilization in Noise-Robust Deep Metric Learning With Subgroup-Based Positive-Pair Selection
Jan 19, 2025



The existence of noisy labels in real-world data negatively impacts the performance of deep learning models. Although much research effort has been devoted to improving the robustness towards noisy labels in classification tasks, the problem of noisy labels in deep metric learning (DML) remains under-explored. Existing noisy label learning methods designed for DML mainly discard suspicious noisy samples, resulting in a waste of the training data. To address this issue, we propose a noise-robust DML framework with SubGroup-based Positive-pair Selection (SGPS), which constructs reliable positive pairs for noisy samples to enhance the sample utilization. Specifically, SGPS first effectively identifies clean and noisy samples by a probability-based clean sample selectionstrategy. To further utilize the remaining noisy samples, we discover their potential similar samples based on the subgroup information given by a subgroup generation module and then aggregate them into informative positive prototypes for each noisy sample via a positive prototype generation module. Afterward, a new contrastive loss is tailored for the noisy samples with their selected positive pairs. SGPS can be easily integrated into the training process of existing pair-wise DML tasks, like image retrieval and face recognition. Extensive experiments on multiple synthetic and real-world large-scale label noise datasets demonstrate the effectiveness of our proposed method. Without any bells and whistles, our SGPS framework outperforms the state-of-the-art noisy label DML methods. Code is available at \url{https://github.com/smuelpeng/SGPS-NoiseFreeDML}.
* arXiv admin note: substantial text overlap with arXiv:2108.01431, arXiv:2103.16047 by other authors
Exploring Query Efficient Data Generation towards Data-free Model Stealing in Hard Label Setting
Dec 18, 2024



Data-free model stealing involves replicating the functionality of a target model into a substitute model without accessing the target model's structure, parameters, or training data. The adversary can only access the target model's predictions for generated samples. Once the substitute model closely approximates the behavior of the target model, attackers can exploit its white-box characteristics for subsequent malicious activities, such as adversarial attacks. Existing methods within cooperative game frameworks often produce samples with high confidence for the prediction of the substitute model, which makes it difficult for the substitute model to replicate the behavior of the target model. This paper presents a new data-free model stealing approach called Query Efficient Data Generation (\textbf{QEDG}). We introduce two distinct loss functions to ensure the generation of sufficient samples that closely and uniformly align with the target model's decision boundary across multiple classes. Building on the limitation of current methods, which typically yield only one piece of supervised information per query, we propose the query-free sample augmentation that enables the acquisition of additional supervised information without increasing the number of queries. Motivated by theoretical analysis, we adopt the consistency rate metric, which more accurately evaluates the similarity between the substitute and target models. We conducted extensive experiments to verify the effectiveness of our proposed method, which achieved better performance with fewer queries compared to the state-of-the-art methods on the real \textbf{MLaaS} scenario and five datasets.