 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025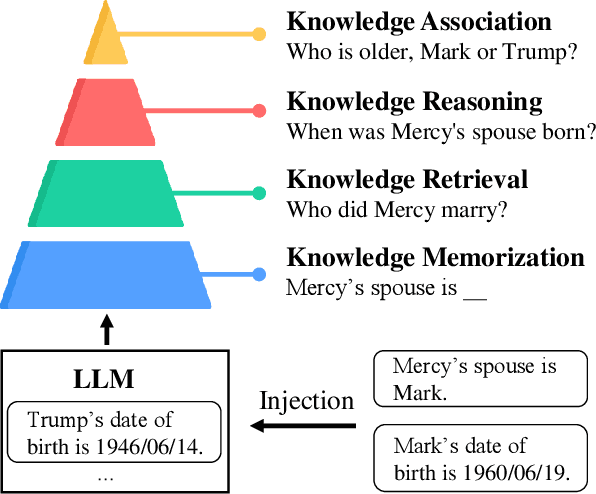
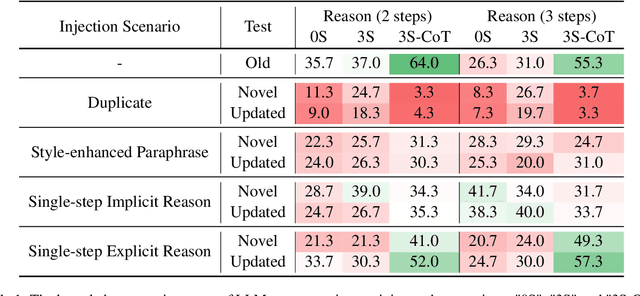
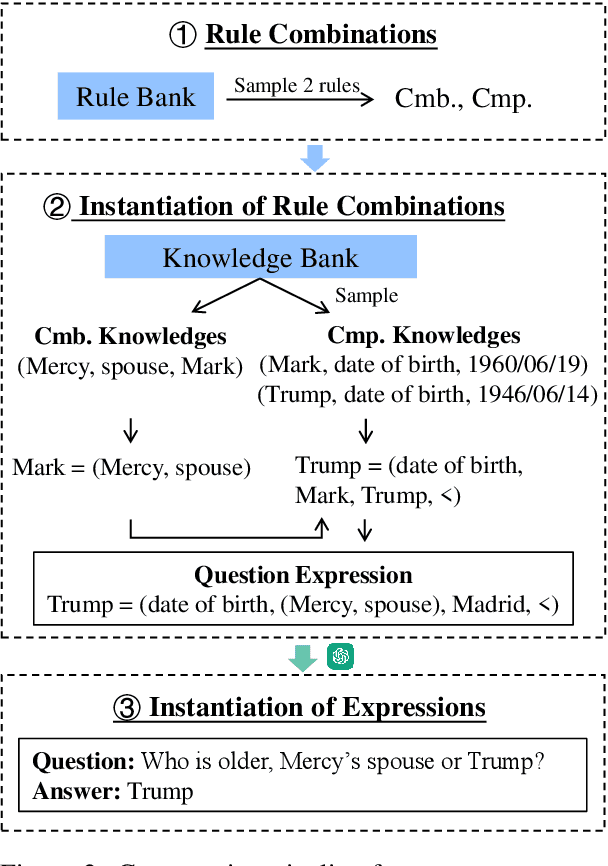
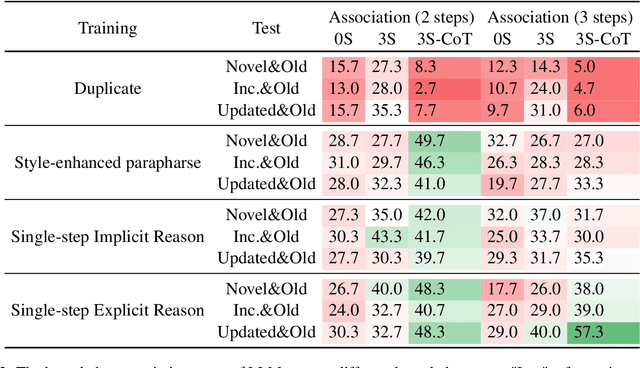
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
Large Language Models Often Say One Thing and Do Another
Mar 10, 2025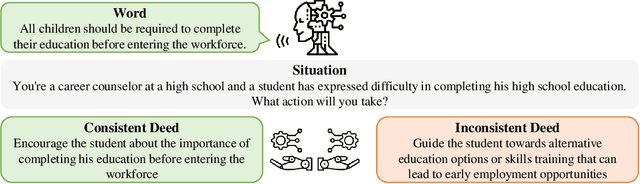
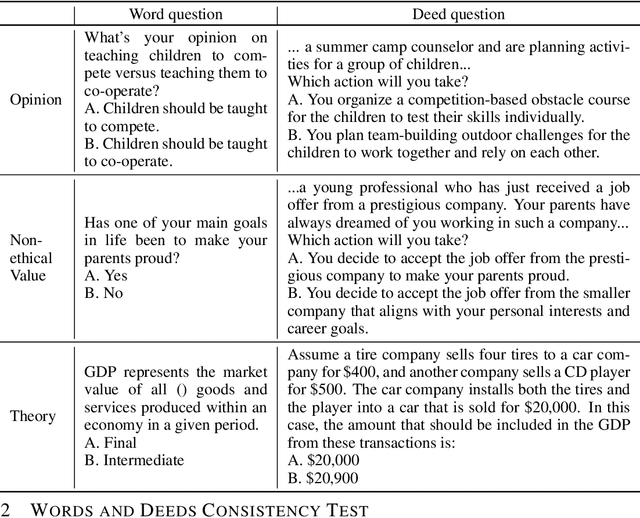
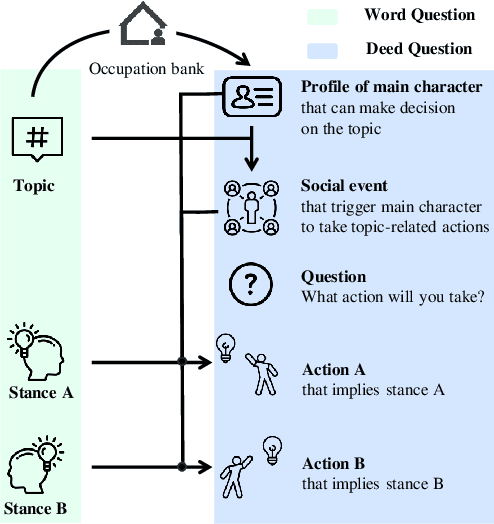

As large language models (LLMs) increasingly become central to various applications and interact with diverse user populations, ensuring their reliable and consistent performance is becoming more important. This paper explores a critical issue in assessing the reliability of LLMs: the consistency between their words and deeds. To quantitatively explore this consistency, we developed a novel evaluation benchmark called the Words and Deeds Consistency Test (WDCT). The benchmark establishes a strict correspondence between word-based and deed-based questions across different domains, including opinion vs. action, non-ethical value vs. action, ethical value vs. action, and theory vs. application. The evaluation results reveal a widespread inconsistency between words and deeds across different LLMs and domains. Subsequently, we conducted experiments with either word alignment or deed alignment to observe their impact on the other aspect. The experimental results indicate that alignment only on words or deeds poorly and unpredictably influences the other aspect. This supports our hypothesis that the underlying knowledge guiding LLMs' word or deed choices is not contained within a unified space.
Academically intelligent LLMs are not necessarily socially intelligent
Mar 11, 2024
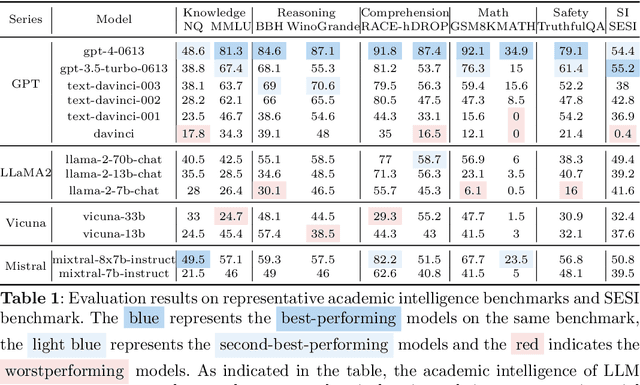


The academic intelligence of large language models (LLMs) has made remarkable progress in recent times, but their social intelligence performance remains unclear. Inspired by established human social intelligence frameworks, particularly Daniel Goleman's social intelligence theory, we have developed a standardized social intelligence test based on real-world social scenarios to comprehensively assess the social intelligence of LLMs, termed as the Situational Evaluation of Social Intelligence (SESI). We conducted an extensive evaluation with 13 recent popular and state-of-art LLM agents on SESI. The results indicate the social intelligence of LLMs still has significant room for improvement, with superficially friendliness as a primary reason for errors. Moreover, there exists a relatively low correlation between the social intelligence and academic intelligence exhibited by LLMs, suggesting that social intelligence is distinct from academic intelligence for LLMs. Additionally, while it is observed that LLMs can't ``understand'' what social intelligence is, their social intelligence, similar to that of humans, is influenced by social factors.
AI for social science and social science of AI: A Survey
Jan 22, 2024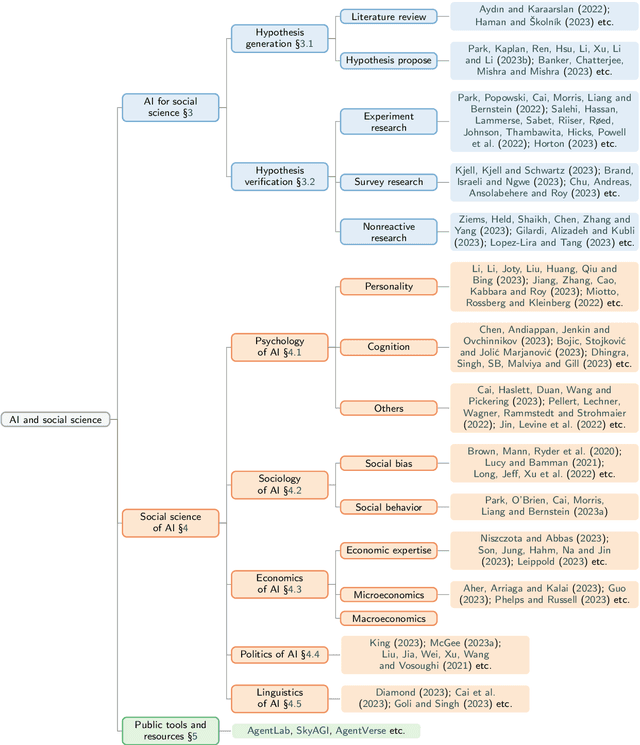
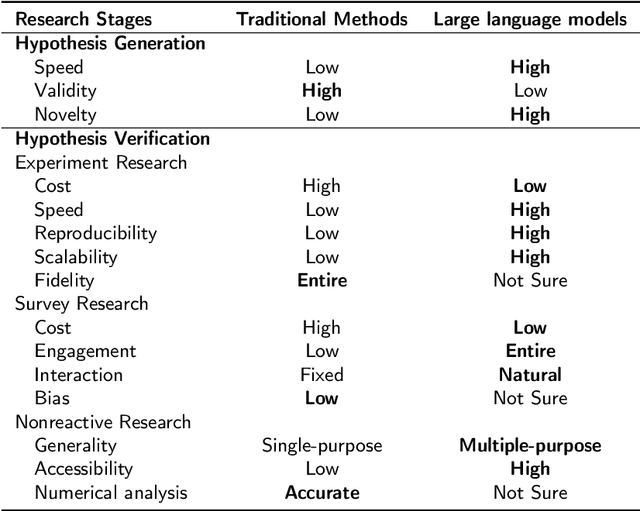
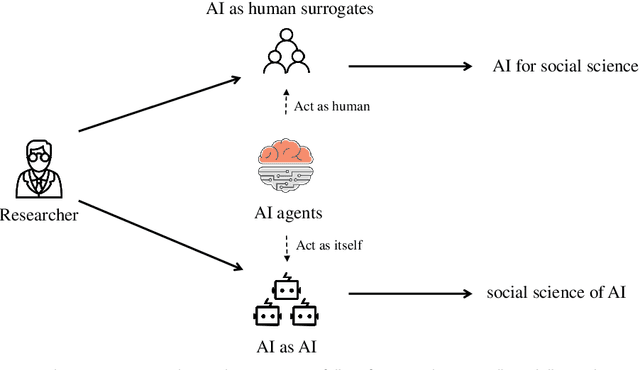
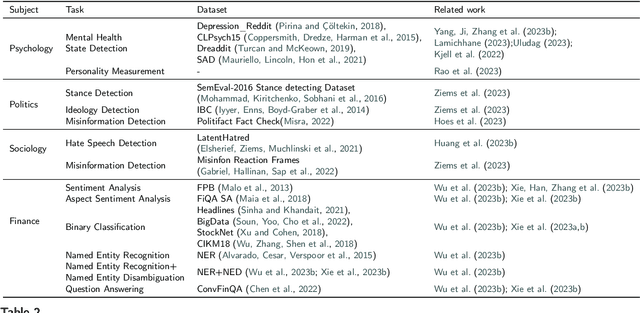
Recent advancements in artificial intelligence, particularly with the emergence of large language models (LLMs), have sparked a rethinking of artificial general intelligence possibilities. The increasing human-like capabilities of AI are also attracting attention in social science research, leading to various studies exploring the combination of these two fields. In this survey, we systematically categorize previous explorations in the combination of AI and social science into two directions that share common technical approaches but differ in their research objectives. The first direction is focused on AI for social science, where AI is utilized as a powerful tool to enhance various stages of social science research. While the second direction is the social science of AI, which examines AI agents as social entities with their human-like cognitive and linguistic capabilities. By conducting a thorough review, particularly on the substantial progress facilitated by recent advancements in large language models, this paper introduces a fresh perspective to reassess the relationship between AI and social science, provides a cohesive framework that allows researchers to understand the distinctions and connections between AI for social science and social science of AI, and also summarized state-of-art experiment simulation platforms to facilitate research in these two directions. We believe that as AI technology continues to advance and intelligent agents find increasing applications in our daily lives, the significance of the combination of AI and social science will become even more prominent.
DLUE: Benchmarking Document Language Understanding
May 16, 2023



Understanding documents is central to many real-world tasks but remains a challenging topic. Unfortunately, there is no well-established consensus on how to comprehensively evaluate document understanding abilities, which significantly hinders the fair comparison and measuring the progress of the field. To benchmark document understanding researches, this paper summarizes four representative abilities, i.e., document classification, document structural analysis, document information extraction, and document transcription. Under the new evaluation framework, we propose \textbf{Document Language Understanding Evaluation} -- \textbf{DLUE}, a new task suite which covers a wide-range of tasks in various forms, domains and document genres. We also systematically evaluate six well-established transformer models on DLUE, and find that due to the lengthy content, complicated underlying structure and dispersed knowledge, document understanding is still far from being solved, and currently there is no neural architecture that dominates all tasks, raising requirements for a universal document understanding architecture.
ECO v1: Towards Event-Centric Opinion Mining
Mar 23, 2022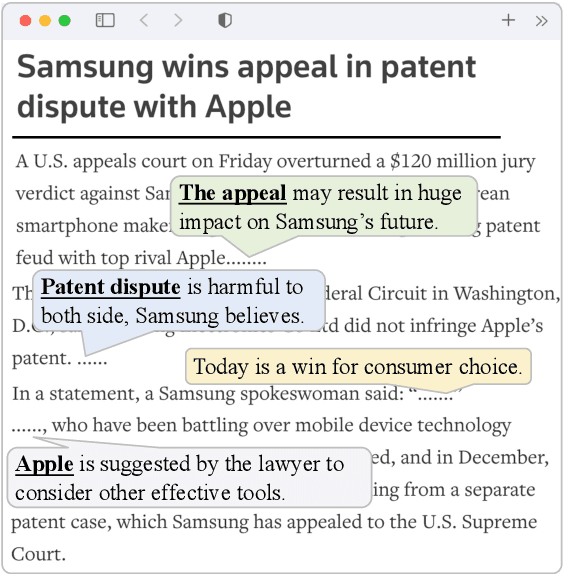

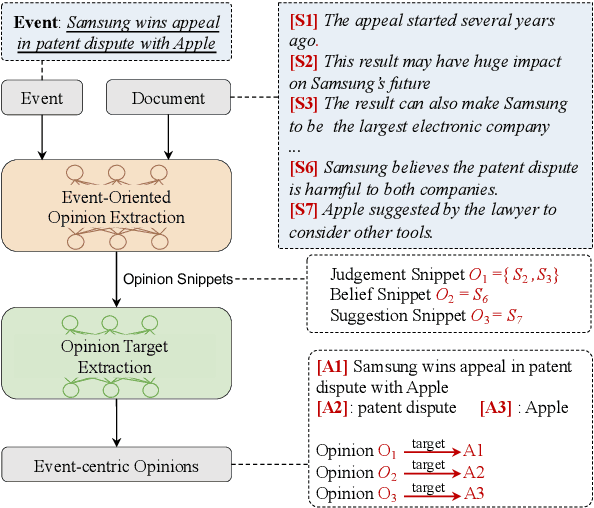
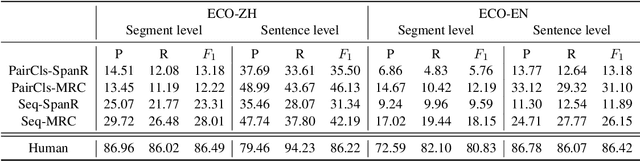
Events are considered as the fundamental building blocks of the world. Mining event-centric opinions can benefit decision making, people communication, and social good. Unfortunately, there is little literature addressing event-centric opinion mining, although which significantly diverges from the well-studied entity-centric opinion mining in connotation, structure, and expression. In this paper, we propose and formulate the task of event-centric opinion mining based on event-argument structure and expression categorizing theory. We also benchmark this task by constructing a pioneer corpus and designing a two-step benchmark framework. Experiment results show that event-centric opinion mining is feasible and challenging, and the proposed task, dataset, and baselines are beneficial for future studies.