 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFunAudio-ASR Technical Report
Sep 15, 2025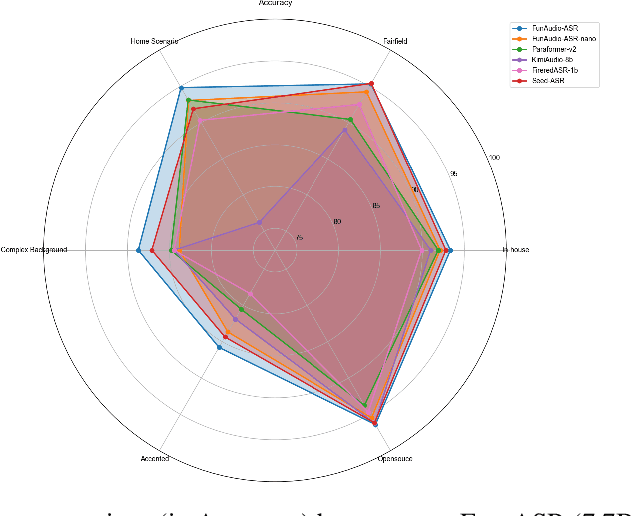
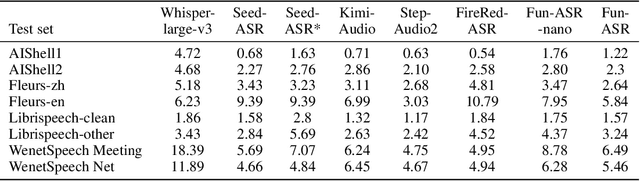
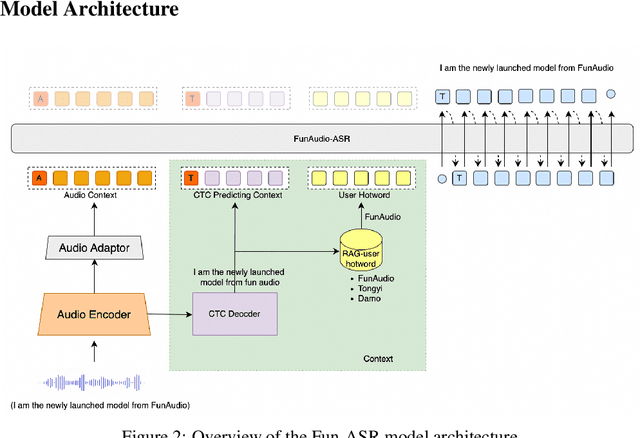
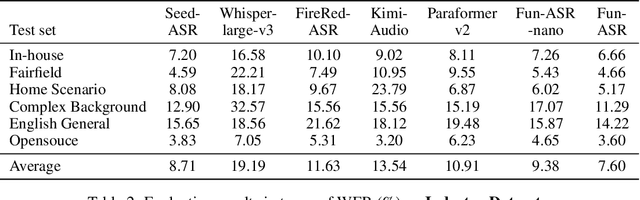
In recent years, automatic speech recognition (ASR) has witnessed transformative advancements driven by three complementary paradigms: data scaling, model size scaling, and deep integration with large language models (LLMs). However, LLMs are prone to hallucination, which can significantly degrade user experience in real-world ASR applications. In this paper, we present FunAudio-ASR, a large-scale, LLM-based ASR system that synergistically combines massive data, large model capacity, LLM integration, and reinforcement learning to achieve state-of-the-art performance across diverse and complex speech recognition scenarios. Moreover, FunAudio-ASR is specifically optimized for practical deployment, with enhancements in streaming capability, noise robustness, code-switching, hotword customization, and satisfying other real-world application requirements. Experimental results show that while most LLM-based ASR systems achieve strong performance on open-source benchmarks, they often underperform on real industry evaluation sets. Thanks to production-oriented optimizations, FunAudio-ASR achieves SOTA performance on real application datasets, demonstrating its effectiveness and robustness in practical settings.
Not All Correct Answers Are Equal: Why Your Distillation Source Matters
May 20, 2025Distillation has emerged as a practical and effective approach to enhance the reasoning capabilities of open-source language models. In this work, we conduct a large-scale empirical study on reasoning data distillation by collecting verified outputs from three state-of-the-art teacher models-AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1-on a shared corpus of 1.89 million queries. We construct three parallel datasets and analyze their distributions, revealing that AM-Thinking-v1-distilled data exhibits greater token length diversity and lower perplexity. Student models trained on each dataset are evaluated on reasoning benchmarks including AIME2024, AIME2025, MATH500, and LiveCodeBench. The AM-based model consistently achieves the best performance (e.g., 84.3 on AIME2024, 72.2 on AIME2025, 98.4 on MATH500, and 65.9 on LiveCodeBench) and demonstrates adaptive output behavior-producing longer responses for harder tasks and shorter ones for simpler tasks. These findings highlight the value of high-quality, verified reasoning traces. We release the AM-Thinking-v1 and Qwen3-235B-A22B distilled datasets to support future research on open and high-performing reasoning-oriented language models. The datasets are publicly available on Hugging Face\footnote{Datasets are available on Hugging Face: \href{https://huggingface.co/datasets/a-m-team/AM-Thinking-v1-Distilled}{AM-Thinking-v1-Distilled}, \href{https://huggingface.co/datasets/a-m-team/AM-Qwen3-Distilled}{AM-Qwen3-Distilled}.}.
AM-Thinking-v1: Advancing the Frontier of Reasoning at 32B Scale
May 13, 2025We present AM-Thinking-v1, a 32B dense language model that advances the frontier of reasoning, embodying the collaborative spirit of open-source innovation. Outperforming DeepSeek-R1 and rivaling leading Mixture-of-Experts (MoE) models like Qwen3-235B-A22B and Seed1.5-Thinking, AM-Thinking-v1 achieves impressive scores of 85.3 on AIME 2024, 74.4 on AIME 2025, and 70.3 on LiveCodeBench, showcasing state-of-the-art mathematical and coding capabilities among open-source models of similar scale. Built entirely from the open-source Qwen2.5-32B base model and publicly available queries, AM-Thinking-v1 leverages a meticulously crafted post-training pipeline - combining supervised fine-tuning and reinforcement learning - to deliver exceptional reasoning capabilities. This work demonstrates that the open-source community can achieve high performance at the 32B scale, a practical sweet spot for deployment and fine-tuning. By striking a balance between top-tier performance and real-world usability, we hope AM-Thinking-v1 inspires further collaborative efforts to harness mid-scale models, pushing reasoning boundaries while keeping accessibility at the core of innovation. We have open-sourced our model on \href{https://huggingface.co/a-m-team/AM-Thinking-v1}{Hugging Face}.
Exploring the Potential of Offline RL for Reasoning in LLMs: A Preliminary Study
May 04, 2025Despite significant advances in long-context reasoning by large language models (LLMs), primarily through Online Reinforcement Learning (RL) methods, these approaches incur substantial computational costs and complexity. In contrast, simpler and more economical Offline RL methods remain underexplored. To address this gap, we investigate the effectiveness of Offline RL methods, specifically Direct Preference Optimization (DPO) and its length-desensitized variant LD-DPO, in enhancing the reasoning capabilities of LLMs. Extensive experiments across multiple reasoning benchmarks demonstrate that these simpler Offline RL methods substantially improve model performance, achieving an average enhancement of 3.3\%, with a particularly notable increase of 10.1\% on the challenging Arena-Hard benchmark. Furthermore, we analyze DPO's sensitivity to output length, emphasizing that increasing reasoning length should align with semantic richness, as indiscriminate lengthening may adversely affect model performance. We provide comprehensive descriptions of our data processing and training methodologies, offering empirical evidence and practical insights for developing more cost-effective Offline RL approaches.
DeepDistill: Enhancing LLM Reasoning Capabilities via Large-Scale Difficulty-Graded Data Training
Apr 24, 2025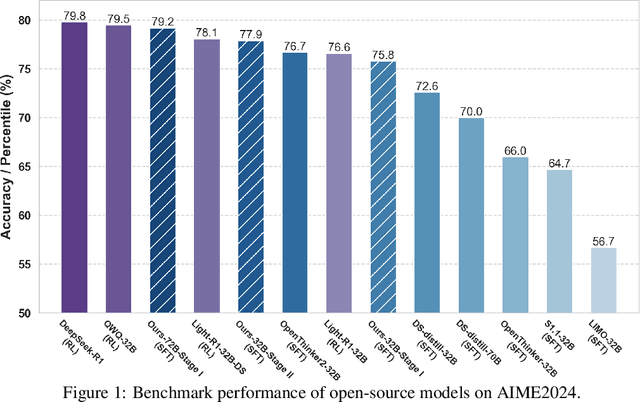



Although large language models (LLMs) have recently achieved remarkable performance on various complex reasoning benchmarks, the academic community still lacks an in-depth understanding of base model training processes and data quality. To address this, we construct a large-scale, difficulty-graded reasoning dataset containing approximately 3.34 million unique queries of varying difficulty levels and about 40 million distilled responses generated by multiple models over several passes. Leveraging pass rate and Coefficient of Variation (CV), we precisely select the most valuable training data to enhance reasoning capability. Notably, we observe a training pattern shift, indicating that reasoning-focused training based on base models requires higher learning rates for effective training. Using this carefully selected data, we significantly improve the reasoning capabilities of the base model, achieving a pass rate of 79.2\% on the AIME2024 mathematical reasoning benchmark. This result surpasses most current distilled models and closely approaches state-of-the-art performance. We provide detailed descriptions of our data processing, difficulty assessment, and training methodology, and have publicly released all datasets and methods to promote rapid progress in open-source long-reasoning LLMs. The dataset is available at: https://huggingface.co/datasets/a-m-team/AM-DeepSeek-Distilled-40M
Leveraging Reasoning Model Answers to Enhance Non-Reasoning Model Capability
Apr 13, 2025


Recent advancements in large language models (LLMs), such as DeepSeek-R1 and OpenAI-o1, have demonstrated the significant effectiveness of test-time scaling, achieving substantial performance gains across various benchmarks. These advanced models utilize deliberate "thinking" steps to systematically enhance answer quality. In this paper, we propose leveraging these high-quality outputs generated by reasoning-intensive models to improve less computationally demanding, non-reasoning models. We explore and compare methodologies for utilizing the answers produced by reasoning models to train and improve non-reasoning models. Through straightforward Supervised Fine-Tuning (SFT) experiments on established benchmarks, we demonstrate consistent improvements across various benchmarks, underscoring the potential of this approach for advancing the ability of models to answer questions directly.
Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025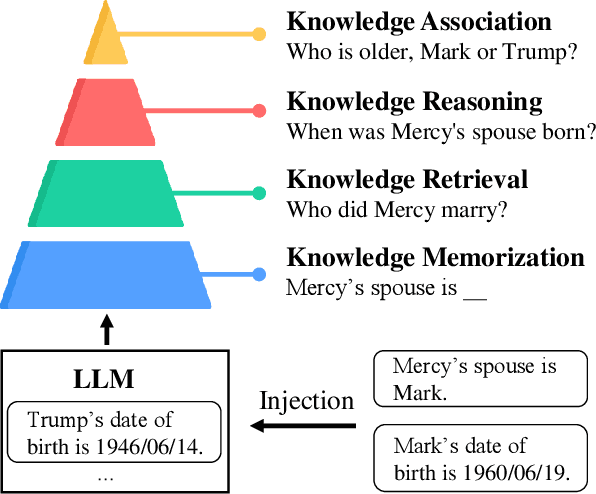
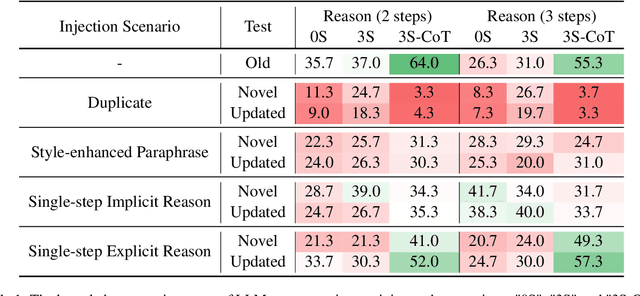
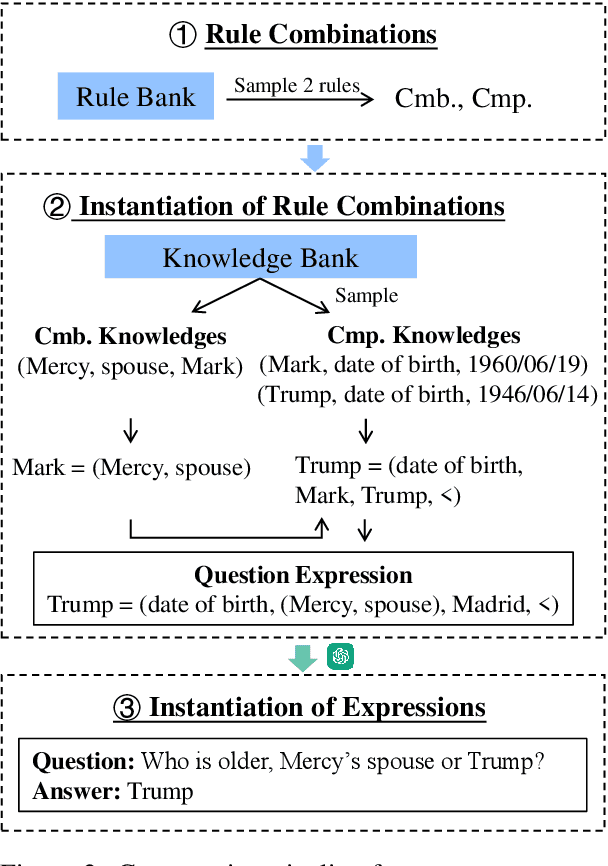
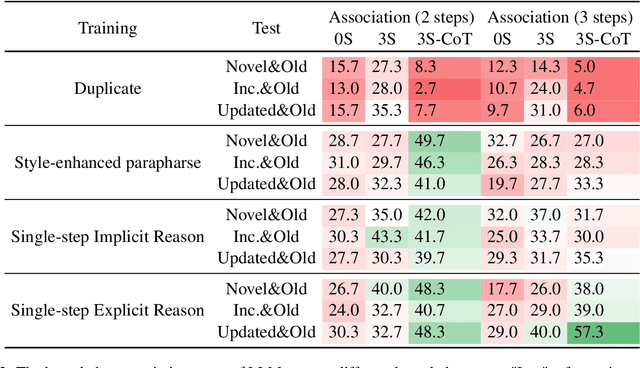
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
How Difficulty-Aware Staged Reinforcement Learning Enhances LLMs' Reasoning Capabilities: A Preliminary Experimental Study
Apr 01, 2025Enhancing the reasoning capabilities of Large Language Models (LLMs) with efficiency and scalability remains a fundamental challenge in artificial intelligence research. This paper presents a rigorous experimental investigation into how difficulty-aware staged reinforcement learning (RL) strategies can substantially improve LLM reasoning performance. Through systematic analysis, we demonstrate that strategically selecting training data according to well-defined difficulty levels markedly enhances RL optimization. Moreover, we introduce a staged training methodology, progressively exposing models to increasingly challenging tasks, further amplifying reasoning capabilities. Our findings reveal significant cross-domain benefits when simultaneously training models on mathematical reasoning and code generation tasks. Notably, our proposed approach enables a 1.5B parameter model to achieve an accuracy of 42.3\% on the AIME-2024 benchmark, 89.5\% on the MATH-500 benchmark. These results underscore the efficacy of our method in advancing the reasoning proficiency of LLMs. We will open-source our datasets on GitHub and Hugging Face.
1.4 Million Open-Source Distilled Reasoning Dataset to Empower Large Language Model Training
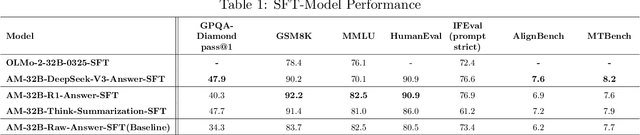
Mar 25, 2025The AM-DeepSeek-R1-Distilled is a large-scale dataset with thinking traces for general reasoning tasks, composed of high-quality and challenging reasoning problems. These problems are collected from a multitude of open-source datasets, subjected to semantic deduplication and meticulous cleaning to eliminate test set contamination. All responses within the dataset are distilled from reasoning models (predominantly DeepSeek-R1) and have undergone rigorous verification procedures. Mathematical problems are validated by checking against reference answers, code problems are verified using test cases, and other tasks are evaluated with the aid of a reward model. The AM-Distill-Qwen-32B model, which was trained through only simple Supervised Fine-Tuning (SFT) using this batch of data, outperformed the DeepSeek-R1-Distill-Qwen-32B model on four benchmarks: AIME2024, MATH-500, GPQA-Diamond, and LiveCodeBench. Additionally, the AM-Distill-Qwen-72B model surpassed the DeepSeek-R1-Distill-Llama-70B model on all benchmarks as well. We are releasing these 1.4 million problems and their corresponding responses to the research community with the objective of fostering the development of powerful reasoning-oriented Large Language Models (LLMs). The dataset was published in \href{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}{https://huggingface.co/datasets/a-m-team/AM-DeepSeek-R1-Distilled-1.4M}.
Think Twice: Enhancing LLM Reasoning by Scaling Multi-round Test-time Thinking
Mar 25, 2025Recent advances in large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, have demonstrated the effectiveness of test-time scaling, where extended reasoning processes substantially enhance model performance. Despite this, current models are constrained by limitations in handling long texts and reinforcement learning (RL) training efficiency. To address these issues, we propose a simple yet effective test-time scaling approach Multi-round Thinking. This method iteratively refines model reasoning by leveraging previous answers as prompts for subsequent rounds. Extensive experiments across multiple models, including QwQ-32B and DeepSeek-R1, consistently show performance improvements on various benchmarks such as AIME 2024, MATH-500, GPQA-diamond, and LiveCodeBench. For instance, the accuracy of QwQ-32B improved from 80.3% (Round 1) to 82.1% (Round 2) on the AIME 2024 dataset, while DeepSeek-R1 showed a similar increase from 79.7% to 82.0%. These results confirm that Multi-round Thinking is a broadly applicable, straightforward approach to achieving stable enhancements in model performance, underscoring its potential for future developments in test-time scaling techniques. The key prompt: {Original question prompt} The assistant's previous answer is: <answer> {last round answer} </answer>, and please re-answer.