 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
C3oT: Generating Shorter Chain-of-Thought without Compromising Effectiveness
Dec 16, 2024



Generating Chain-of-Thought (CoT) before deriving the answer can effectively improve the reasoning capabilities of large language models (LLMs) and significantly improve the accuracy of the generated answer. However, in most cases, the length of the generated CoT is much longer than the desired final answer, which results in additional decoding costs. Furthermore, existing research has discovered that shortening the reasoning steps in CoT, even while preserving the key information, diminishes LLMs' abilities. These phenomena make it difficult to use LLMs and CoT in many real-world applications that only require the final answer and are sensitive to latency, such as search and recommendation. To reduce the costs of model decoding and shorten the length of the generated CoT, this paper presents $\textbf{C}$onditioned $\textbf{C}$ompressed $\textbf{C}$hain-of-$\textbf{T}$hought (C3oT), a CoT compression framework that involves a compressor to compress an original longer CoT into a shorter CoT while maintaining key information and interpretability, a conditioned training method to train LLMs with both longer CoT and shorter CoT simultaneously to learn the corresponding relationships between them, and a conditioned inference method to gain the reasoning ability learned from longer CoT by generating shorter CoT. We conduct experiments over four datasets from arithmetic and commonsense scenarios, showing that the proposed method is capable of compressing the length of generated CoT by up to more than 50% without compromising its effectiveness.
ChatHome: Development and Evaluation of a Domain-Specific Language Model for Home Renovation
Jul 28, 2023



This paper presents the development and evaluation of ChatHome, a domain-specific language model (DSLM) designed for the intricate field of home renovation. Considering the proven competencies of large language models (LLMs) like GPT-4 and the escalating fascination with home renovation, this study endeavors to reconcile these aspects by generating a dedicated model that can yield high-fidelity, precise outputs relevant to the home renovation arena. ChatHome's novelty rests on its methodology, fusing domain-adaptive pretraining and instruction-tuning over an extensive dataset. This dataset includes professional articles, standard documents, and web content pertinent to home renovation. This dual-pronged strategy is designed to ensure that our model can assimilate comprehensive domain knowledge and effectively address user inquiries. Via thorough experimentation on diverse datasets, both universal and domain-specific, including the freshly introduced "EvalHome" domain dataset, we substantiate that ChatHome not only amplifies domain-specific functionalities but also preserves its versatility.
A Comparative Study between Full-Parameter and LoRA-based Fine-Tuning on Chinese Instruction Data for Instruction Following Large Language Model
Apr 18, 2023



Recently, the instruction-tuning of large language models is a crucial area of research in the field of natural language processing. Due to resource and cost limitations, several researchers have employed parameter-efficient tuning techniques, such as LoRA, for instruction tuning, and have obtained encouraging results In comparison to full-parameter fine-tuning, LoRA-based tuning demonstrates salient benefits in terms of training costs. In this study, we undertook experimental comparisons between full-parameter fine-tuning and LoRA-based tuning methods, utilizing LLaMA as the base model. The experimental results show that the selection of the foundational model, training dataset scale, learnable parameter quantity, and model training cost are all important factors. We hope that the experimental conclusions of this paper can provide inspiration for training large language models, especially in the field of Chinese, and help researchers find a better trade-off strategy between training cost and model performance. To facilitate the reproduction of the paper's results, the dataset, model and code will be released.
BEIKE NLP at SemEval-2022 Task 4: Prompt-Based Paragraph Classification for Patronizing and Condescending Language Detection
Aug 02, 2022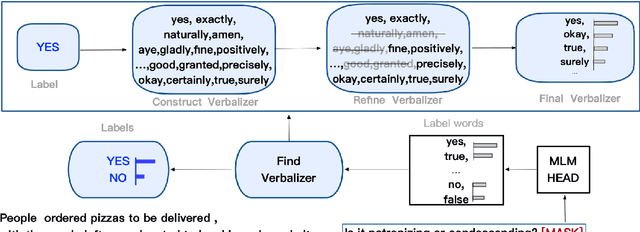
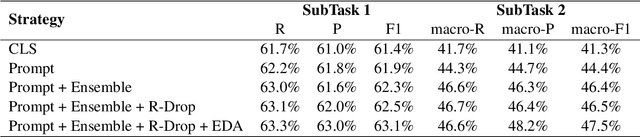
PCL detection task is aimed at identifying and categorizing language that is patronizing or condescending towards vulnerable communities in the general media.Compared to other NLP tasks of paragraph classification, the negative language presented in the PCL detection task is usually more implicit and subtle to be recognized, making the performance of common text-classification approaches disappointed. Targeting the PCL detection problem in SemEval-2022 Task 4, in this paper, we give an introduction to our team's solution, which exploits the power of prompt-based learning on paragraph classification. We reformulate the task as an appropriate cloze prompt and use pre-trained Masked Language Models to fill the cloze slot. For the two subtasks, binary classification and multi-label classification, DeBERTa model is adopted and fine-tuned to predict masked label words of task-specific prompts. On the evaluation dataset, for binary classification, our approach achieves an F1-score of 0.6406; for multi-label classification, our approach achieves an macro-F1-score of 0.4689 and ranks first in the leaderboard.