 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResPrune: Text-Conditioned Subspace Reconstruction for Visual Token Pruning in Large Vision-Language Models
Mar 22, 2026Large Vision-Language Models (LVLMs) rely on dense visual tokens to capture fine-grained visual information, but processing all these tokens incurs substantial computational and memory overhead during inference. To address this issue, we propose ResPrune, a training-free visual token pruning framework that enables efficient LVLM inference by selecting a compact yet informative subset of visual tokens. ResPrune formulates visual token pruning as a subspace reconstruction problem and employs a greedy subspace expansion strategy guided by residual energy, allowing it to preserve the geometric structure of the original visual token space. To further incorporate cross modal alignment, the selection process is conditioned on textual relevance, encouraging the retention of tokens that are both informative and instruction-relevant. The proposed method is lightweight and model-agnostic, and can be seamlessly integrated into existing LVLM pipelines without retraining or architectural modifications. Extensive experiments on multiple LVLM backbones, including LLaVA-1.5, LLaVA-NeXT, and Qwen2.5-VL, demonstrate that ResPrune consistently outperforms existing pruning approaches across a wide range of benchmarks, while achieving effective reductions in computation, memory consumption, and inference latency.
AgentProcessBench: Diagnosing Step-Level Process Quality in Tool-Using Agents
Mar 15, 2026While Large Language Models (LLMs) have evolved into tool-using agents, they remain brittle in long-horizon interactions. Unlike mathematical reasoning where errors are often rectifiable via backtracking, tool-use failures frequently induce irreversible side effects, making accurate step-level verification critical. However, existing process-level benchmarks are predominantly confined to closed-world mathematical domains, failing to capture the dynamic and open-ended nature of tool execution. To bridge this gap, we introduce AgentProcessBench, the first benchmark dedicated to evaluating step-level effectiveness in realistic, tool-augmented trajectories. The benchmark comprises 1,000 diverse trajectories and 8,509 human-labeled step annotations with 89.1% inter-annotator agreement. It features a ternary labeling scheme to capture exploration and an error propagation rule to reduce labeling ambiguity. Extensive experiments reveal key insights: (1) weaker policy models exhibit inflated ratios of correct steps due to early termination; (2) distinguishing neutral and erroneous actions remains a significant challenge for current models; and (3) process-derived signals provide complementary value to outcome supervision, significantly enhancing test-time scaling. We hope AgentProcessBench can foster future research in reward models and pave the way toward general agents. The code and data are available at https://github.com/RUCBM/AgentProcessBench.
AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents
Feb 06, 2026While Large Language Model (LLM)-based agents have shown remarkable potential for solving complex tasks, existing systems remain heavily reliant on large-scale models, leaving the capabilities of edge-scale models largely underexplored. In this paper, we present the first systematic study on training agentic models at the 4B-parameter scale. We identify three primary bottlenecks hindering the performance of edge-scale models: catastrophic forgetting during Supervised Fine-Tuning (SFT), sensitivity to reward signal noise during Reinforcement Learning (RL), and reasoning degradation caused by redundant information in long-context scenarios. To address the issues, we propose AgentCPM-Explore, a compact 4B agent model with high knowledge density and strong exploration capability. We introduce a holistic training framework featuring parameter-space model fusion, reward signal denoising, and contextual information refinement. Through deep exploration, AgentCPM-Explore achieves state-of-the-art (SOTA) performance among 4B-class models, matches or surpasses 8B-class SOTA models on four benchmarks, and even outperforms larger-scale models such as Claude-4.5-Sonnet or DeepSeek-v3.2 in five benchmarks. Notably, AgentCPM-Explore achieves 97.09% accuracy on GAIA text-based tasks under pass@64. These results provide compelling evidence that the bottleneck for edge-scale models is not their inherent capability ceiling, but rather their inference stability. Based on our well-established training framework, AgentCPM-Explore effectively unlocks the significant, yet previously underestimated, potential of edge-scale models.
DeepEra: A Deep Evidence Reranking Agent for Scientific Retrieval-Augmented Generated Question Answering
Jan 23, 2026With the rapid growth of scientific literature, scientific question answering (SciQA) has become increasingly critical for exploring and utilizing scientific knowledge. Retrieval-Augmented Generation (RAG) enhances LLMs by incorporating knowledge from external sources, thereby providing credible evidence for scientific question answering. But existing retrieval and reranking methods remain vulnerable to passages that are semantically similar but logically irrelevant, often reducing factual reliability and amplifying hallucinations.To address this challenge, we propose a Deep Evidence Reranking Agent (DeepEra) that integrates step-by-step reasoning, enabling more precise evaluation of candidate passages beyond surface-level semantics. To support systematic evaluation, we construct SciRAG-SSLI (Scientific RAG - Semantically Similar but Logically Irrelevant), a large-scale dataset comprising about 300K SciQA instances across 10 subjects, constructed from 10M scientific corpus. The dataset combines naturally retrieved contexts with systematically generated distractors to test logical robustness and factual grounding. Comprehensive evaluations confirm that our approach achieves superior retrieval performance compared to leading rerankers. To our knowledge, this work is the first to comprehensively study and empirically validate innegligible SSLI issues in two-stage RAG frameworks.
AtomMem : Learnable Dynamic Agentic Memory with Atomic Memory Operation
Jan 13, 2026Equipping agents with memory is essential for solving real-world long-horizon problems. However, most existing agent memory mechanisms rely on static and hand-crafted workflows. This limits the performance and generalization ability of these memory designs, which highlights the need for a more flexible, learning-based memory framework. In this paper, we propose AtomMem, which reframes memory management as a dynamic decision-making problem. We deconstruct high-level memory processes into fundamental atomic CRUD (Create, Read, Update, Delete) operations, transforming the memory workflow into a learnable decision process. By combining supervised fine-tuning with reinforcement learning, AtomMem learns an autonomous, task-aligned policy to orchestrate memory behaviors tailored to specific task demands. Experimental results across 3 long-context benchmarks demonstrate that the trained AtomMem-8B consistently outperforms prior static-workflow memory methods. Further analysis of training dynamics shows that our learning-based formulation enables the agent to discover structured, task-aligned memory management strategies, highlighting a key advantage over predefined routines.
ScienceDB AI: An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
Jan 03, 2026The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.
Agentmandering: A Game-Theoretic Framework for Fair Redistricting via Large Language Model Agents
Nov 09, 2025Redistricting plays a central role in shaping how votes are translated into political power. While existing computational methods primarily aim to generate large ensembles of legally valid districting plans, they often neglect the strategic dynamics involved in the selection process. This oversight creates opportunities for partisan actors to cherry-pick maps that, while technically compliant, are politically advantageous. Simply satisfying formal constraints does not ensure fairness when the selection process itself can be manipulated. We propose \textbf{Agentmandering}, a framework that reimagines redistricting as a turn-based negotiation between two agents representing opposing political interests. Drawing inspiration from game-theoretic ideas, particularly the \textit{Choose-and-Freeze} protocol, our method embeds strategic interaction into the redistricting process via large language model (LLM) agents. Agents alternate between selecting and freezing districts from a small set of candidate maps, gradually partitioning the state through constrained and interpretable choices. Evaluation on post-2020 U.S. Census data across all states shows that Agentmandering significantly reduces partisan bias and unfairness, while achieving 2 to 3 orders of magnitude lower variance than standard baselines. These results demonstrate both fairness and stability, especially in swing-state scenarios. Our code is available at https://github.com/Lihaogx/AgentMandering.
Do LLMs Signal When They're Right? Evidence from Neuron Agreement
Oct 30, 2025Large language models (LLMs) commonly boost reasoning via sample-evaluate-ensemble decoders, achieving label free gains without ground truth. However, prevailing strategies score candidates using only external outputs such as token probabilities, entropies, or self evaluations, and these signals can be poorly calibrated after post training. We instead analyze internal behavior based on neuron activations and uncover three findings: (1) external signals are low dimensional projections of richer internal dynamics; (2) correct responses activate substantially fewer unique neurons than incorrect ones throughout generation; and (3) activations from correct responses exhibit stronger cross sample agreement, whereas incorrect ones diverge. Motivated by these observations, we propose Neuron Agreement Decoding (NAD), an unsupervised best-of-N method that selects candidates using activation sparsity and cross sample neuron agreement, operating solely on internal signals and without requiring comparable textual outputs. NAD enables early correctness prediction within the first 32 generated tokens and supports aggressive early stopping. Across math and science benchmarks with verifiable answers, NAD matches majority voting; on open ended coding benchmarks where majority voting is inapplicable, NAD consistently outperforms Avg@64. By pruning unpromising trajectories early, NAD reduces token usage by 99% with minimal loss in generation quality, showing that internal signals provide reliable, scalable, and efficient guidance for label free ensemble decoding.
Training-Free Pyramid Token Pruning for Efficient Large Vision-Language Models via Region, Token, and Instruction-Guided Importance
Sep 19, 2025Large Vision-Language Models (LVLMs) have significantly advanced multimodal understanding but still struggle with efficiently processing high-resolution images. Recent approaches partition high-resolution images into multiple sub-images, dramatically increasing the number of visual tokens and causing exponential computational overhead during inference. To address these limitations, we propose a training-free token pruning strategy, Pyramid Token Pruning (PTP), that integrates bottom-up visual saliency at both region and token levels with top-down instruction-guided importance. Inspired by human visual attention mechanisms, PTP selectively retains more tokens from visually salient regions and further leverages textual instructions to pinpoint tokens most relevant to specific multimodal tasks. Extensive experiments across 13 diverse benchmarks demonstrate that our method substantially reduces computational overhead and inference latency with minimal performance loss.
HERO: Rethinking Visual Token Early Dropping in High-Resolution Large Vision-Language Models
Sep 16, 2025
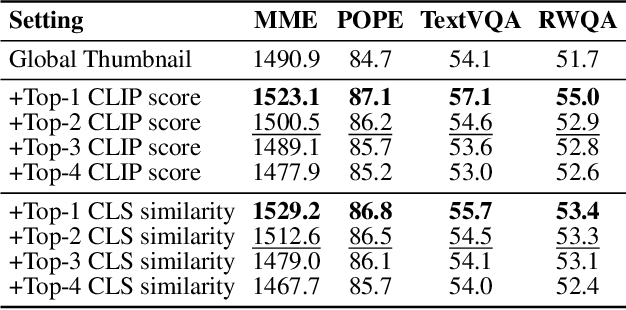
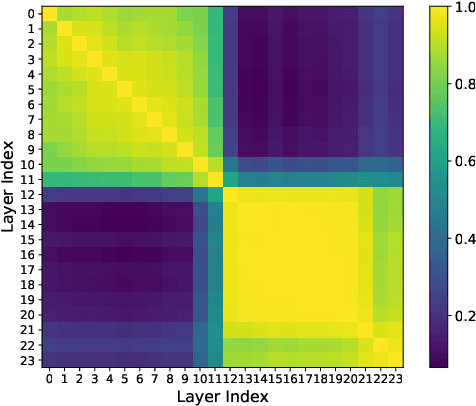
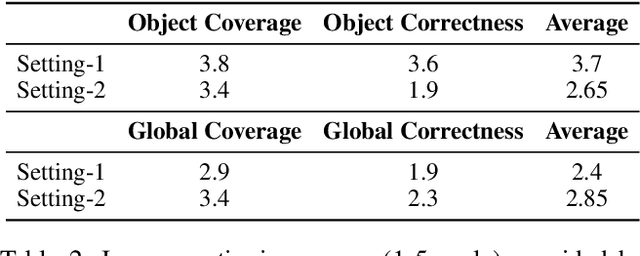
By cropping high-resolution images into local tiles and encoding them independently, High-Resolution Large Vision-Language Models (HR-LVLMs) have demonstrated remarkable fine-grained visual understanding capabilities. However, this divide-and-conquer paradigm significantly increases the number of visual tokens, resulting in substantial computational and memory overhead. To better understand and address this challenge, we empirically investigate visual token utilization in HR-LVLMs and uncover three key findings: (1) the local tiles have varying importance, jointly determined by visual saliency and task relevance; (2) the CLS token in CLIP-based vision encoders exhibits a two-stage attention pattern across layers, with each stage attending to different types of visual tokens; (3) the visual tokens emphasized at different stages encode information at varying levels of granularity, playing complementary roles within LVLMs. Building on these insights, we propose HERO, a High-resolution visual token early dropping framework that integrates content-adaptive token budget allocation with function-aware token selection. By accurately estimating tile-level importance and selectively retaining visual tokens with complementary roles, HERO achieves superior efficiency-accuracy trade-offs across diverse benchmarks and model scales, all in a training-free manner. This study provides both empirical insights and practical solutions toward efficient inference in HR-LVLMs.