 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
ToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025
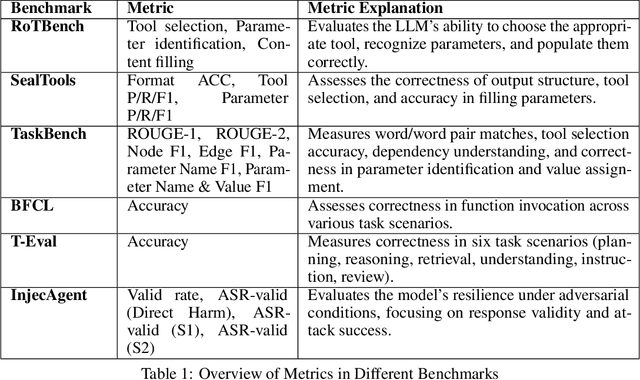
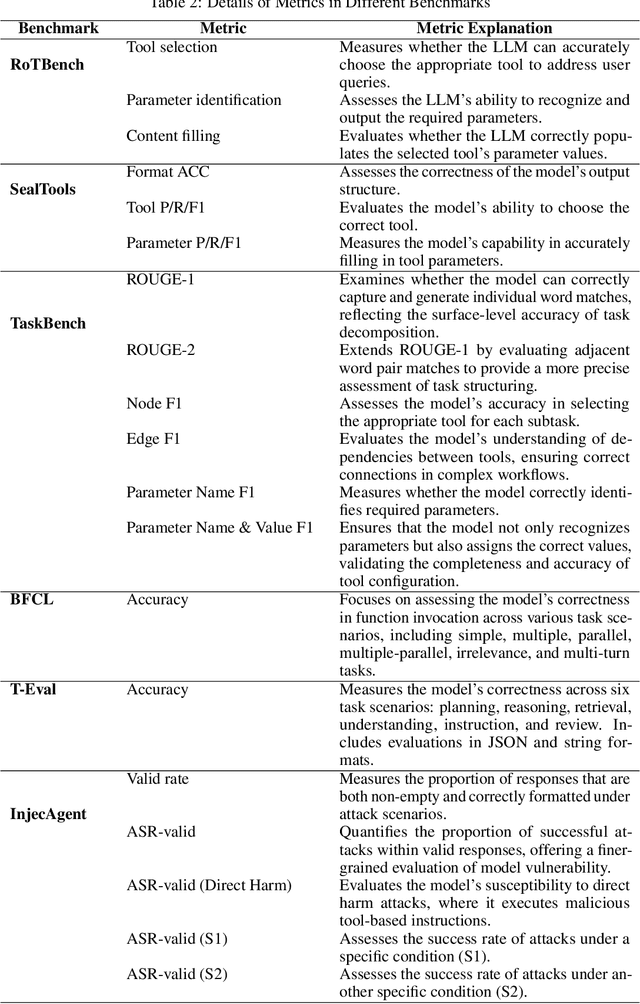
Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
Flow: A Modular Approach to Automated Agentic Workflow Generation
Jan 14, 2025



Multi-agent frameworks powered by large language models (LLMs) have demonstrated great success in automated planning and task execution. However, the effective adjustment of Agentic workflows during execution has not been well-studied. A effective workflow adjustment is crucial, as in many real-world scenarios, the initial plan must adjust to unforeseen challenges and changing conditions in real-time to ensure the efficient execution of complex tasks. In this paper, we define workflows as an activity-on-vertex (AOV) graphs. We continuously refine the workflow by dynamically adjusting task allocations based on historical performance and previous AOV with LLM agents. To further enhance system performance, we emphasize modularity in workflow design based on measuring parallelism and dependence complexity. Our proposed multi-agent framework achieved efficient sub-task concurrent execution, goal achievement, and error tolerance. Empirical results across different practical tasks demonstrate dramatic improvements in the efficiency of multi-agent frameworks through dynamic workflow updating and modularization.
Interpretable Contrastive Monte Carlo Tree Search Reasoning
Oct 02, 2024
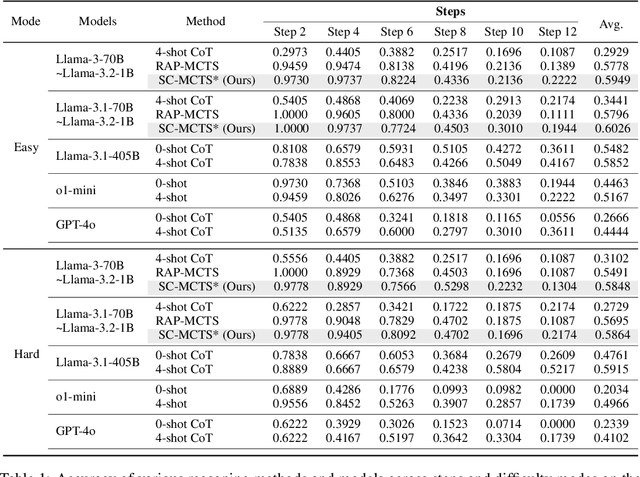


We propose SC-MCTS*: a novel Monte Carlo Tree Search (MCTS) reasoning algorithm for Large Language Models (LLMs), significantly improves both reasoning accuracy and speed. Our motivation comes from: 1. Previous MCTS LLM reasoning works often overlooked its biggest drawback--slower speed compared to CoT; 2. Previous research mainly used MCTS as a tool for LLM reasoning on various tasks with limited quantitative analysis or ablation studies of its components from reasoning interpretability perspective. 3. The reward model is the most crucial component in MCTS, however previous work has rarely conducted in-depth study or improvement of MCTS's reward models. Thus, we conducted extensive ablation studies and quantitative analysis on components of MCTS, revealing the impact of each component on the MCTS reasoning performance of LLMs. Building on this, (i) we designed a highly interpretable reward model based on the principle of contrastive decoding and (ii) achieved an average speed improvement of 51.9% per node using speculative decoding. Additionally, (iii) we improved UCT node selection strategy and backpropagation used in previous works, resulting in significant performance improvement. We outperformed o1-mini by an average of 17.4% on the Blocksworld multi-step reasoning dataset using Llama-3.1-70B with SC-MCTS*.