 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeeper Insights Without Updates: The Power of In-Context Learning Over Fine-Tuning
Oct 07, 2024



Fine-tuning and in-context learning (ICL) are two prevalent methods in imbuing large language models with task-specific knowledge. It is commonly believed that fine-tuning can surpass ICL given sufficient training samples as it allows the model to adjust its internal parameters based on the data. However, this paper presents a counterintuitive finding: For tasks with implicit patterns, ICL captures these patterns significantly better than fine-tuning. We developed several datasets featuring implicit patterns, such as sequences determining answers through parity or identifying reducible terms in calculations. We then evaluated the models' understanding of these patterns under both fine-tuning and ICL across models ranging from 0.5B to 7B parameters. The results indicate that models employing ICL can quickly grasp deep patterns and significantly improve accuracy. In contrast, fine-tuning, despite utilizing thousands of times more training samples than ICL, achieved only limited improvements. We also proposed circuit shift theory from a mechanistic interpretability's view to explain why ICL wins.
Interpretable Contrastive Monte Carlo Tree Search Reasoning
Oct 02, 2024
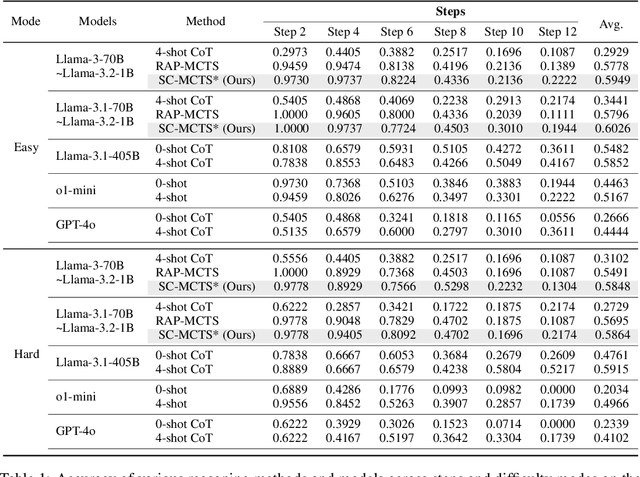


We propose SC-MCTS*: a novel Monte Carlo Tree Search (MCTS) reasoning algorithm for Large Language Models (LLMs), significantly improves both reasoning accuracy and speed. Our motivation comes from: 1. Previous MCTS LLM reasoning works often overlooked its biggest drawback--slower speed compared to CoT; 2. Previous research mainly used MCTS as a tool for LLM reasoning on various tasks with limited quantitative analysis or ablation studies of its components from reasoning interpretability perspective. 3. The reward model is the most crucial component in MCTS, however previous work has rarely conducted in-depth study or improvement of MCTS's reward models. Thus, we conducted extensive ablation studies and quantitative analysis on components of MCTS, revealing the impact of each component on the MCTS reasoning performance of LLMs. Building on this, (i) we designed a highly interpretable reward model based on the principle of contrastive decoding and (ii) achieved an average speed improvement of 51.9% per node using speculative decoding. Additionally, (iii) we improved UCT node selection strategy and backpropagation used in previous works, resulting in significant performance improvement. We outperformed o1-mini by an average of 17.4% on the Blocksworld multi-step reasoning dataset using Llama-3.1-70B with SC-MCTS*.
Demonstrating Mutual Reinforcement Effect through Information Flow
Mar 05, 2024



The Mutual Reinforcement Effect (MRE) investigates the synergistic relationship between word-level and text-level classifications in text classification tasks. It posits that the performance of both classification levels can be mutually enhanced. However, this mechanism has not been adequately demonstrated or explained in prior research. To address this gap, we employ information flow analysis to observe and substantiate the MRE theory. Our experiments on six MRE hybrid datasets revealed the presence of MRE in the model and its impact. Additionally, we conducted fine-tuning experiments, whose results were consistent with those of the information flow experiments. The convergence of findings from both experiments corroborates the existence of MRE. Furthermore, we extended the application of MRE to prompt learning, utilizing word-level information as a verbalizer to bolster the model's prediction of text-level classification labels. In our final experiment, the F1-score significantly surpassed the baseline in five out of six datasets, further validating the notion that word-level information enhances the language model's comprehension of the text as a whole.
StableMask: Refining Causal Masking in Decoder-only Transformer
Feb 07, 2024



The decoder-only Transformer architecture with causal masking and relative position encoding (RPE) has become the de facto choice in language modeling. Despite its exceptional performance across various tasks, we have identified two limitations: First, it requires all attention scores to be non-zero and sum up to 1, even if the current embedding has sufficient self-contained information. This compels the model to assign disproportional excessive attention to specific tokens. Second, RPE-based Transformers are not universal approximators due to their limited capacity at encoding absolute positional information, which limits their application in position-critical tasks. In this work, we propose StableMask: a parameter-free method to address both limitations by refining the causal mask. It introduces pseudo-attention values to balance attention distributions and encodes absolute positional information via a progressively decreasing mask ratio. StableMask's effectiveness is validated both theoretically and empirically, showing significant enhancements in language models with parameter sizes ranging from 71M to 1.4B across diverse datasets and encoding methods. We further show that it naturally supports (1) efficient extrapolation without special tricks such as StreamingLLM and (2) easy integration with existing attention optimization techniques.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.