 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Rethinking Reasoning: A Survey on Reasoning-based Backdoors in LLMs
Oct 09, 2025With the rise of advanced reasoning capabilities, large language models (LLMs) are receiving increasing attention. However, although reasoning improves LLMs' performance on downstream tasks, it also introduces new security risks, as adversaries can exploit these capabilities to conduct backdoor attacks. Existing surveys on backdoor attacks and reasoning security offer comprehensive overviews but lack in-depth analysis of backdoor attacks and defenses targeting LLMs' reasoning abilities. In this paper, we take the first step toward providing a comprehensive review of reasoning-based backdoor attacks in LLMs by analyzing their underlying mechanisms, methodological frameworks, and unresolved challenges. Specifically, we introduce a new taxonomy that offers a unified perspective for summarizing existing approaches, categorizing reasoning-based backdoor attacks into associative, passive, and active. We also present defense strategies against such attacks and discuss current challenges alongside potential directions for future research. This work offers a novel perspective, paving the way for further exploration of secure and trustworthy LLM communities.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
ViLaS: Integrating Vision and Language into Automatic Speech Recognition
May 31, 2023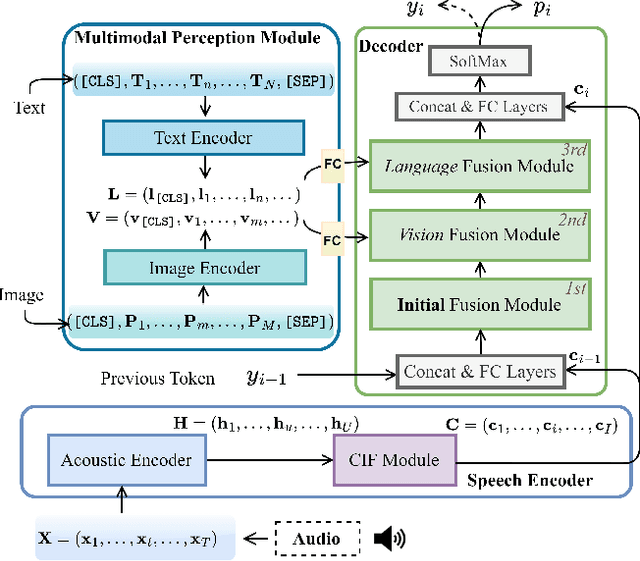
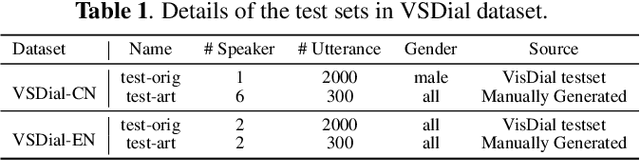
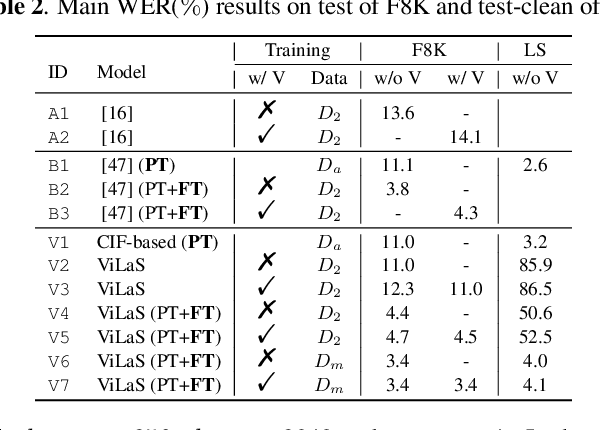
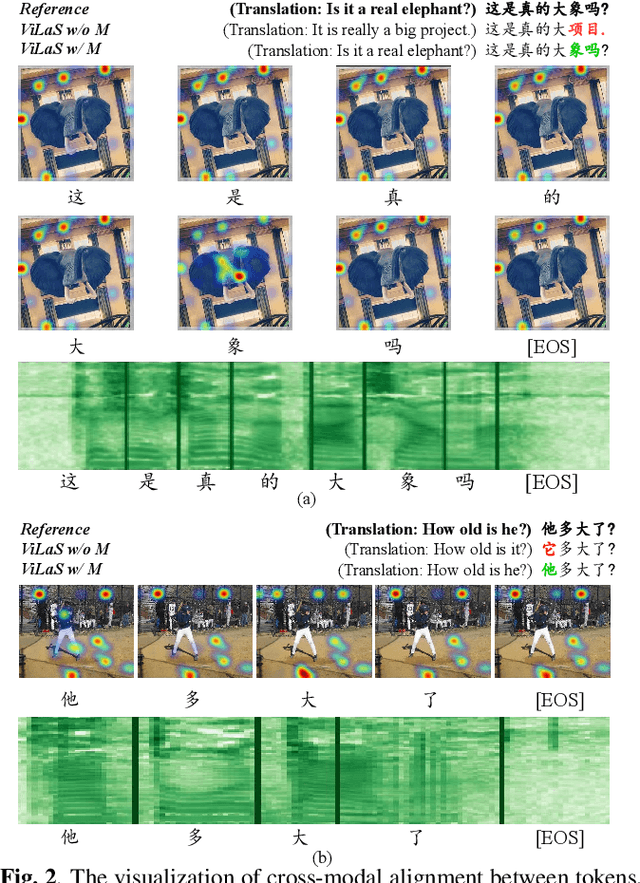
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.
Mixture of personality improved Spiking actor network for efficient multi-agent cooperation
May 10, 2023
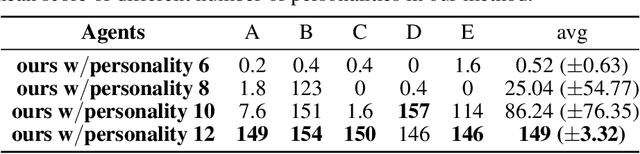

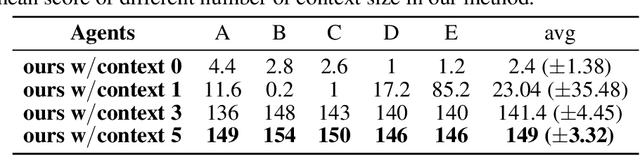
Adaptive human-agent and agent-agent cooperation are becoming more and more critical in the research area of multi-agent reinforcement learning (MARL), where remarked progress has been made with the help of deep neural networks. However, many established algorithms can only perform well during the learning paradigm but exhibit poor generalization during cooperation with other unseen partners. The personality theory in cognitive psychology describes that humans can well handle the above cooperation challenge by predicting others' personalities first and then their complex actions. Inspired by this two-step psychology theory, we propose a biologically plausible mixture of personality (MoP) improved spiking actor network (SAN), whereby a determinantal point process is used to simulate the complex formation and integration of different types of personality in MoP, and dynamic and spiking neurons are incorporated into the SAN for the efficient reinforcement learning. The benchmark Overcooked task, containing a strong requirement for cooperative cooking, is selected to test the proposed MoP-SAN. The experimental results show that the MoP-SAN can achieve both high performances during not only the learning paradigm but also the generalization test (i.e., cooperation with other unseen agents) paradigm where most counterpart deep actor networks failed. Necessary ablation experiments and visualization analyses were conducted to explain why MoP and SAN are effective in multi-agent reinforcement learning scenarios while DNN performs poorly in the generalization test.
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
Dec 20, 2021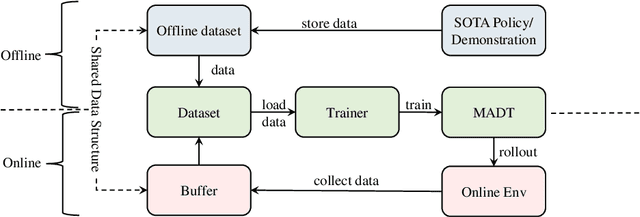
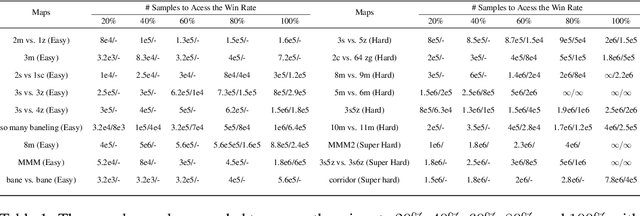
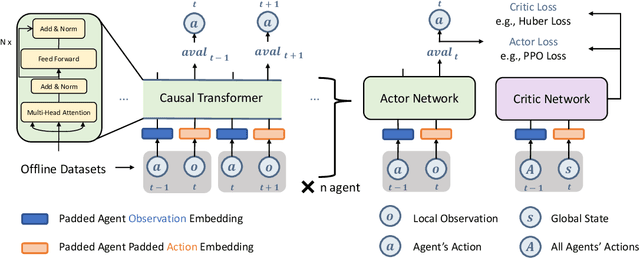
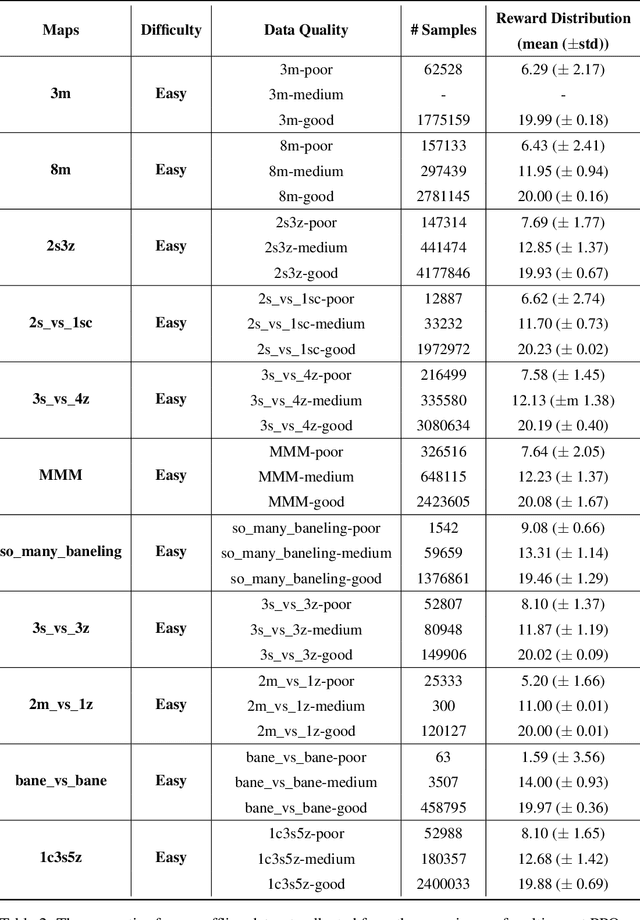
Offline reinforcement learning leverages previously-collected offline datasets to learn optimal policies with no necessity to access the real environment. Such a paradigm is also desirable for multi-agent reinforcement learning (MARL) tasks, given the increased interactions among agents and with the enviroment. Yet, in MARL, the paradigm of offline pre-training with online fine-tuning has not been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we facilitate the research by providing large-scale datasets, and use them to examine the usage of the Decision Transformer in the context of MARL. We investigate the generalisation of MARL offline pre-training in the following three aspects: 1) between single agents and multiple agents, 2) from offline pretraining to the online fine-tuning, and 3) to that of multiple downstream tasks with few-shot and zero-shot capabilities. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages transformer's modelling ability of sequence modelling and integrates it seamlessly with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalizable policies that can transfer between different types of agents under different task scenarios. On StarCraft II offline dataset, MADT outperforms the state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance both few-short and zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
Settling the Variance of Multi-Agent Policy Gradients
Aug 20, 2021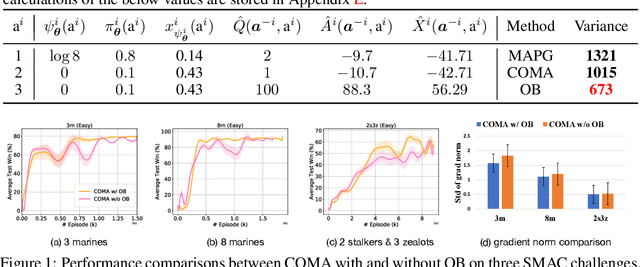
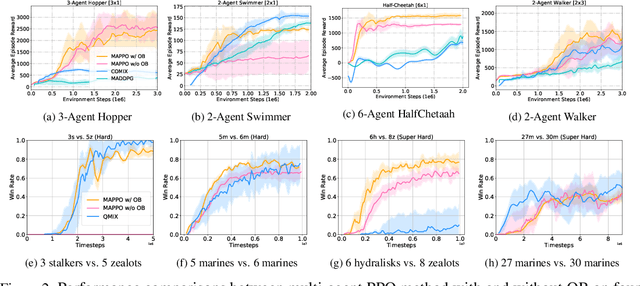

Policy gradient (PG) methods are popular reinforcement learning (RL) methods where a baseline is often applied to reduce the variance of gradient estimates. In multi-agent RL (MARL), although the PG theorem can be naturally extended, the effectiveness of multi-agent PG (MAPG) methods degrades as the variance of gradient estimates increases rapidly with the number of agents. In this paper, we offer a rigorous analysis of MAPG methods by, firstly, quantifying the contributions of the number of agents and agents' explorations to the variance of MAPG estimators. Based on this analysis, we derive the optimal baseline (OB) that achieves the minimal variance. In comparison to the OB, we measure the excess variance of existing MARL algorithms such as vanilla MAPG and COMA. Considering using deep neural networks, we also propose a surrogate version of OB, which can be seamlessly plugged into any existing PG methods in MARL. On benchmarks of Multi-Agent MuJoCo and StarCraft challenges, our OB technique effectively stabilises training and improves the performance of multi-agent PPO and COMA algorithms by a significant margin.
MixSpeech: Data Augmentation for Low-resource Automatic Speech Recognition
Feb 25, 2021


In this paper, we propose MixSpeech, a simple yet effective data augmentation method based on mixup for automatic speech recognition (ASR). MixSpeech trains an ASR model by taking a weighted combination of two different speech features (e.g., mel-spectrograms or MFCC) as the input, and recognizing both text sequences, where the two recognition losses use the same combination weight. We apply MixSpeech on two popular end-to-end speech recognition models including LAS (Listen, Attend and Spell) and Transformer, and conduct experiments on several low-resource datasets including TIMIT, WSJ, and HKUST. Experimental results show that MixSpeech achieves better accuracy than the baseline models without data augmentation, and outperforms a strong data augmentation method SpecAugment on these recognition tasks. Specifically, MixSpeech outperforms SpecAugment with a relative PER improvement of 10.6$\%$ on TIMIT dataset, and achieves a strong WER of 4.7$\%$ on WSJ dataset.