 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLaS: Integrating Vision and Language into Automatic Speech Recognition
Paper and Code
May 31, 2023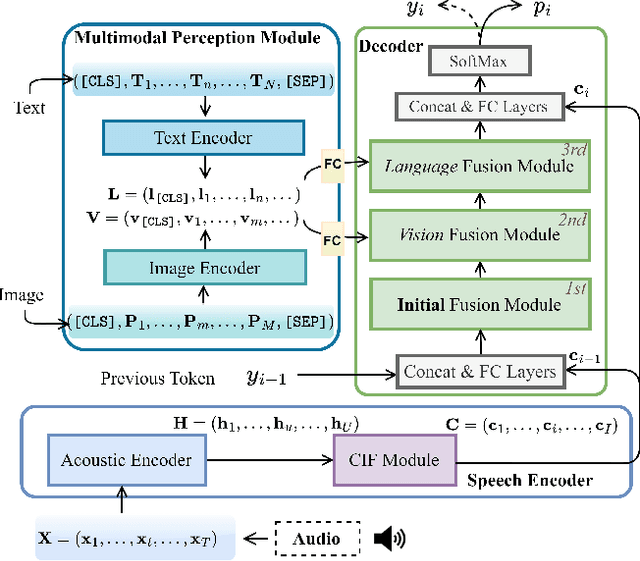
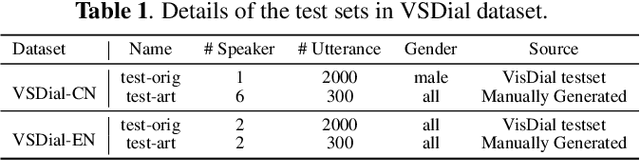
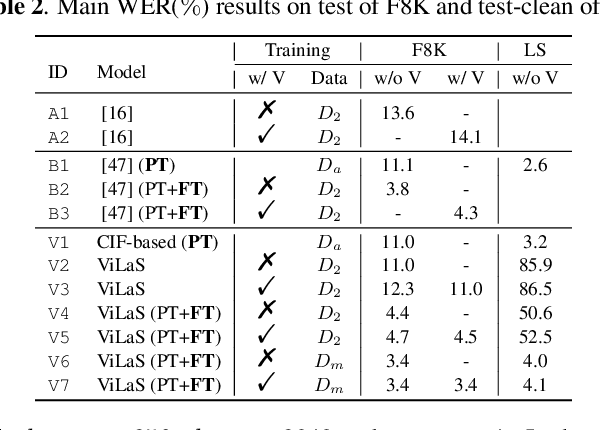
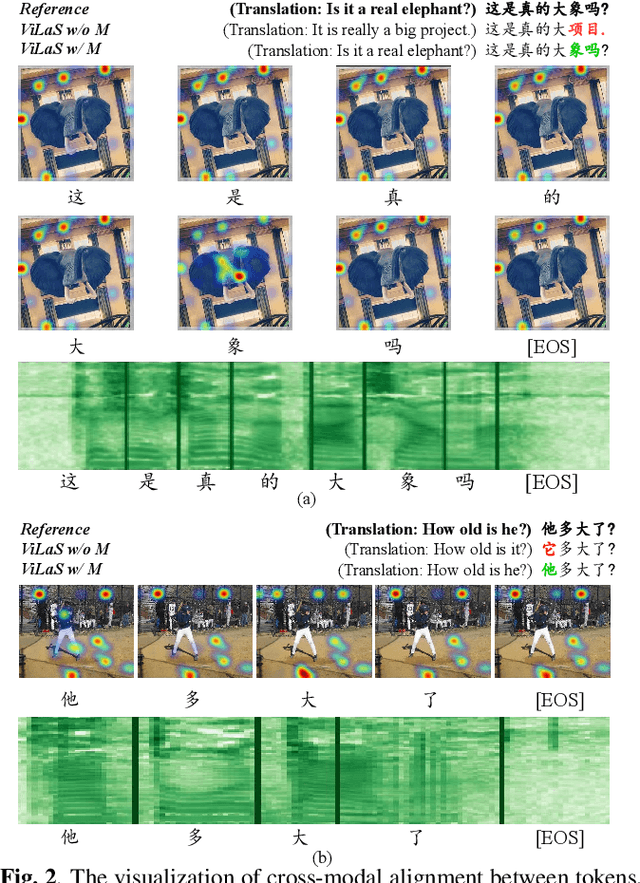
Employing additional multimodal information to improve automatic speech recognition (ASR) performance has been proven effective in previous works. However, many of these works focus only on the utilization of visual cues from human lip motion. In fact, context-dependent visual and linguistic cues can also be used to improve ASR performance in many scenarios. In this paper, we first propose a multimodal ASR model (ViLaS) that can simultaneously or separately integrate visual and linguistic cues to help recognize the input speech, and introduce a training strategy that can improve performance in modal-incomplete test scenarios. Then, we create a multimodal ASR dataset (VSDial) with visual and linguistic cues to explore the effects of integrating vision and language. Finally, we report empirical results on the public Flickr8K and self-constructed VSDial datasets, investigate cross-modal fusion schemes, and analyze fine-grained cross-modal alignment on VSDial.