 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Diffusion for Hybrid Language Model
Jun 01, 2026Autoregressive (AR) large language models (LLMs) have achieved broad practical success, but sequential decoding remains a key bottleneck for low-latency deployment. Recent efficient-inference work has progressed along two axes: reducing the cost of each model invocation through efficient architectures, and reducing serial decoding steps through parallel generation. Hybrid attention backbones address the former, while diffusion language models (dLLMs) pursue the latter via iterative parallel denoising. Combining these advantages remains challenging: AR-to-dLLM conversion often fails to preserve seed-checkpoint capability, and hybrid-attention recurrent states and masking constraints make diffusion training and serving nontrivial. We present FLARE, a systematic conversion framework for hybrid-attention LLMs. Our analysis identifies transfer data quality as the primary determinant of capability preservation, outweighing loss formulation and attention-mask design. The resulting framework combines a token-equal AR-and-diffusion objective, hardware-aware kernels, and unified inference, enabling one checkpoint to support both AR-style verified decoding and diffusion-style parallel denoising. Starting from strong AR checkpoints with limited post-training data, FLARE is competitive with leading open-source dLLMs across model scales and delivers consistent throughput gains over open-source dLLM baselines in single-GPU concurrent serving. Our results further suggest that practical dLLMs are limited not only by decoding algorithms, but also by transfer data quality and the training inefficiency of current block-diffusion objectives, motivating joint design of data, objectives, architectures, and inference systems.
CausaLab: A Scalable Environment for Interactive Causal Discovery Toward AI Scientists
May 28, 2026We introduce CausaLab, a scalable environment for evaluating interactive causal discovery by LLM agents. Unlike prior evaluations, CausaLab evaluates both whether an agent can solve a problem using causal evidence and whether its answer is grounded in a faithful recovered causal mechanism. Each episode places an agent in a synthetic laboratory: it receives prior measurement records, intervenes on a manipulator crystal, and predicts the resonance frequency of a held-out reactor crystal governed by the same mechanism. The hidden data-generating process is a randomly sampled structural causal model (SCM), so success requires recovering both a causal graph and structural equations rather than recalling prior knowledge. Experiments show a persistent gap between prediction and mechanism recovery: in the purely observational 6-node setting, GPT-5.2-high reaches 92% task accuracy but only 0.471 all-edge $F_1$. Mixed observation-intervention strategies improve structural fidelity, while pure intervention remains difficult even for strong agents. We identify premature stopping as a major weakness and show that consistency verification mitigates it. CausaLab therefore separates predictive success from causal understanding and exposes current LLM agents' limits as experimental causal reasoners.
MotiMotion: Motion-Controlled Video Generation with Visual Reasoning
May 21, 2026Current motion-controlled image-to-video generation models rigidly follow user-provided trajectories that are often sparse, imprecise, and causally incomplete. Such reliance often yields unnatural or implausible outcomes, especially by missing secondary causal consequences. To address this, we introduce MotiMotion, a novel framework that reformulates motion control as a reasoning-then-generation problem. To encourage causally grounded and commonsense-consistent interactions, we leverage a training-free vision-language reasoner to refine image-space coordinates of primary trajectories and to hallucinate plausible secondary motions. To further improve motion naturalness, we propose a confidence-aware control scheme that modulates guidance strength, enabling the model to closely follow high-confidence plans while correcting artifacts under low-confidence inputs with its internal generative priors. To support systematic evaluation, we curate a new image-to-video benchmark, MotiBench, consisting of interaction-centric scenes where new events are triggered by motion. Both VLM-based evaluation and a human study on MotiBench demonstrate that MotiMotion produces videos with more plausible object behaviors and interaction, and is preferred over existing approaches.
Stepwise Credit Assignment for GRPO on Flow-Matching Models
Mar 30, 2026Flow-GRPO successfully applies reinforcement learning to flow models, but uses uniform credit assignment across all steps. This ignores the temporal structure of diffusion generation: early steps determine composition and content (low-frequency structure), while late steps resolve details and textures (high-frequency details). Moreover, assigning uniform credit based solely on the final image can inadvertently reward suboptimal intermediate steps, especially when errors are corrected later in the diffusion trajectory. We propose Stepwise-Flow-GRPO, which assigns credit based on each step's reward improvement. By leveraging Tweedie's formula to obtain intermediate reward estimates and introducing gain-based advantages, our method achieves superior sample efficiency and faster convergence. We also introduce a DDIM-inspired SDE that improves reward quality while preserving stochasticity for policy gradients.
Seeing Through Words: Controlling Visual Retrieval Quality with Language Models
Feb 24, 2026Text-to-image retrieval is a fundamental task in vision-language learning, yet in real-world scenarios it is often challenged by short and underspecified user queries. Such queries are typically only one or two words long, rendering them semantically ambiguous, prone to collisions across diverse visual interpretations, and lacking explicit control over the quality of retrieved images. To address these issues, we propose a new paradigm of quality-controllable retrieval, which enriches short queries with contextual details while incorporating explicit notions of image quality. Our key idea is to leverage a generative language model as a query completion function, extending underspecified queries into descriptive forms that capture fine-grained visual attributes such as pose, scene, and aesthetics. We introduce a general framework that conditions query completion on discretized quality levels, derived from relevance and aesthetic scoring models, so that query enrichment is not only semantically meaningful but also quality-aware. The resulting system provides three key advantages: 1) flexibility, it is compatible with any pretrained vision-language model (VLMs) without modification; 2) transparency, enriched queries are explicitly interpretable by users; and 3) controllability, enabling retrieval results to be steered toward user-preferred quality levels. Extensive experiments demonstrate that our proposed approach significantly improves retrieval results and provides effective quality control, bridging the gap between the expressive capacity of modern VLMs and the underspecified nature of short user queries. Our code is available at https://github.com/Jianglin954/QCQC.
RetouchIQ: MLLM Agents for Instruction-Based Image Retouching with Generalist Reward
Feb 19, 2026Recent advances in multimodal large language models (MLLMs) have shown great potential for extending vision-language reasoning to professional tool-based image editing, enabling intuitive and creative editing. A promising direction is to use reinforcement learning (RL) to enable MLLMs to reason about and execute optimal tool-use plans within professional image-editing software. However, training remains challenging due to the lack of reliable, verifiable reward signals that can reflect the inherently subjective nature of creative editing. In this work, we introduce RetouchIQ, a framework that performs instruction-based executable image editing through MLLM agents guided by a generalist reward model. RetouchIQ interprets user-specified editing intentions and generates corresponding, executable image adjustments, bridging high-level aesthetic goals with precise parameter control. To move beyond conventional, rule-based rewards that compute similarity against a fixed reference image using handcrafted metrics, we propose a generalist reward model, an RL fine-tuned MLLM that evaluates edited results through a set of generated metrics on a case-by-case basis. Then, the reward model provides scalar feedback through multimodal reasoning, enabling reinforcement learning with high-quality, instruction-consistent gradients. We curate an extended dataset with 190k instruction-reasoning pairs and establish a new benchmark for instruction-based image editing. Experiments show that RetouchIQ substantially improves both semantic consistency and perceptual quality over previous MLLM-based and diffusion-based editing systems. Our findings demonstrate the potential of generalist reward-driven MLLM agents as flexible, explainable, and executable assistants for professional image editing.
More Than the Final Answer: Improving Visual Extraction and Logical Consistency in Vision-Language Models
Dec 13, 2025Reinforcement learning from verifiable rewards (RLVR) has recently been extended from text-only LLMs to vision-language models (VLMs) to elicit long-chain multimodal reasoning. However, RLVR-trained VLMs still exhibit two persistent failure modes: inaccurate visual extraction (missing or hallucinating details) and logically inconsistent chains-of-thought, largely because verifiable signals supervise only the final answer. We propose PeRL-VL (Perception and Reasoning Learning for Vision-Language Models), a decoupled framework that separately improves visual perception and textual reasoning on top of RLVR. For perception, PeRL-VL introduces a VLM-based description reward that scores the model's self-generated image descriptions for faithfulness and sufficiency. For reasoning, PeRL-VL adds a text-only Reasoning SFT stage on logic-rich chain-of-thought data, enhancing coherence and logical consistency independently of vision. Across diverse multimodal benchmarks, PeRL-VL improves average Pass@1 accuracy from 63.3% (base Qwen2.5-VL-7B) to 68.8%, outperforming standard RLVR, text-only reasoning SFT, and naive multimodal distillation from GPT-4o.
Relational Visual Similarity
Dec 08, 2025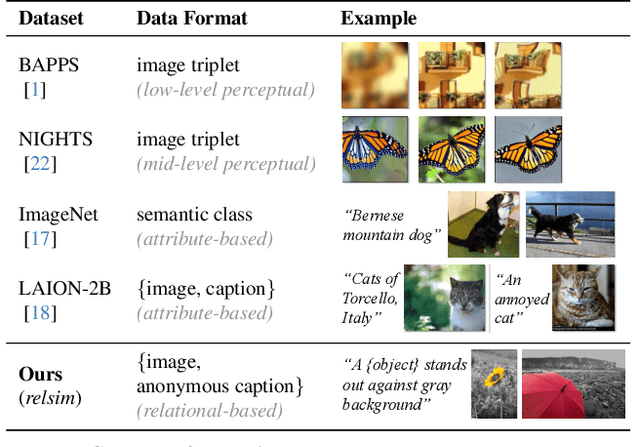
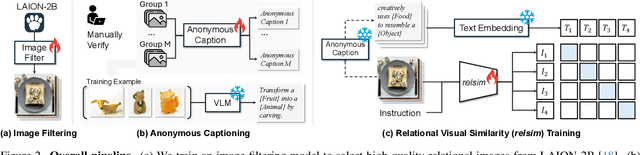
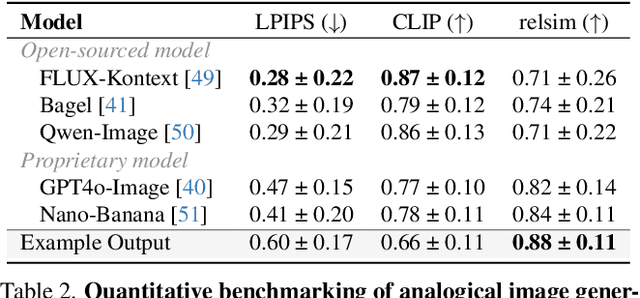

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
Plot'n Polish: Zero-shot Story Visualization and Disentangled Editing with Text-to-Image Diffusion Models
Sep 04, 2025Text-to-image diffusion models have demonstrated significant capabilities to generate diverse and detailed visuals in various domains, and story visualization is emerging as a particularly promising application. However, as their use in real-world creative domains increases, the need for providing enhanced control, refinement, and the ability to modify images post-generation in a consistent manner becomes an important challenge. Existing methods often lack the flexibility to apply fine or coarse edits while maintaining visual and narrative consistency across multiple frames, preventing creators from seamlessly crafting and refining their visual stories. To address these challenges, we introduce Plot'n Polish, a zero-shot framework that enables consistent story generation and provides fine-grained control over story visualizations at various levels of detail.
Trust-MARL: Trust-Based Multi-Agent Reinforcement Learning Framework for Cooperative On-Ramp Merging Control in Heterogeneous Traffic Flow
Jun 14, 2025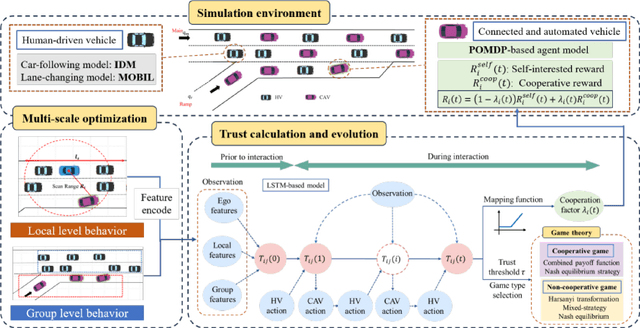

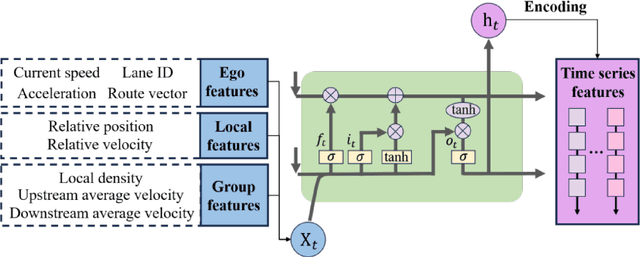
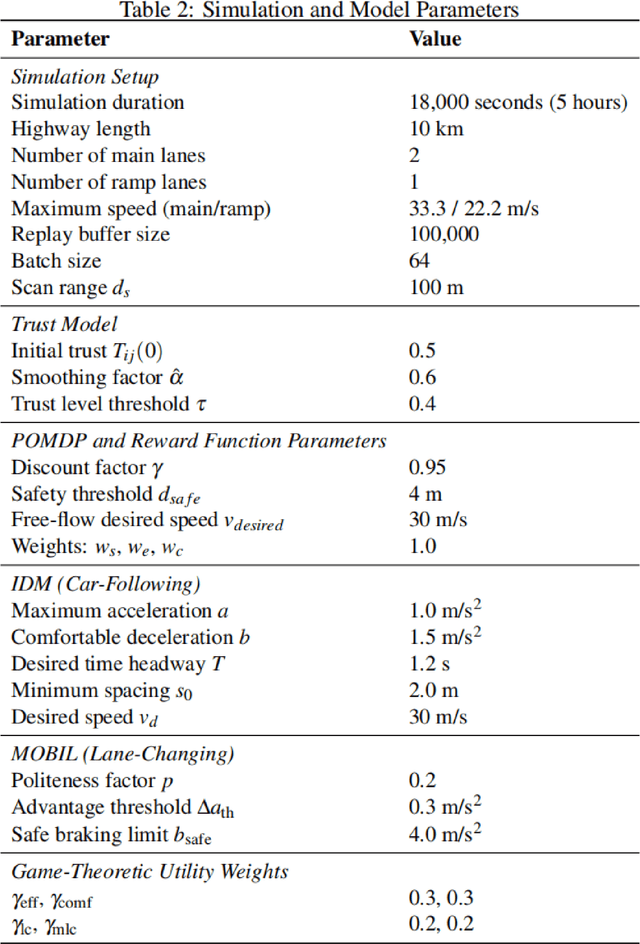
Intelligent transportation systems require connected and automated vehicles (CAVs) to conduct safe and efficient cooperation with human-driven vehicles (HVs) in complex real-world traffic environments. However, the inherent unpredictability of human behaviour, especially at bottlenecks such as highway on-ramp merging areas, often disrupts traffic flow and compromises system performance. To address the challenge of cooperative on-ramp merging in heterogeneous traffic environments, this study proposes a trust-based multi-agent reinforcement learning (Trust-MARL) framework. At the macro level, Trust-MARL enhances global traffic efficiency by leveraging inter-agent trust to improve bottleneck throughput and mitigate traffic shockwave through emergent group-level coordination. At the micro level, a dynamic trust mechanism is designed to enable CAVs to adjust their cooperative strategies in response to real-time behaviors and historical interactions with both HVs and other CAVs. Furthermore, a trust-triggered game-theoretic decision-making module is integrated to guide each CAV in adapting its cooperation factor and executing context-aware lane-changing decisions under safety, comfort, and efficiency constraints. An extensive set of ablation studies and comparative experiments validates the effectiveness of the proposed Trust-MARL approach, demonstrating significant improvements in safety, efficiency, comfort, and adaptability across varying CAV penetration rates and traffic densities.