 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025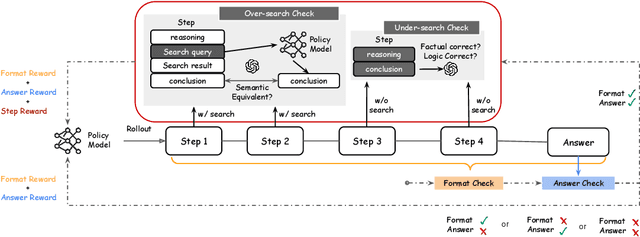
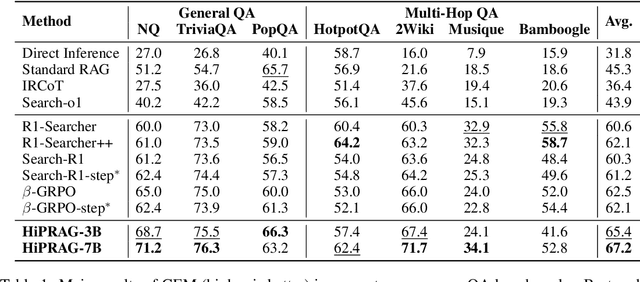
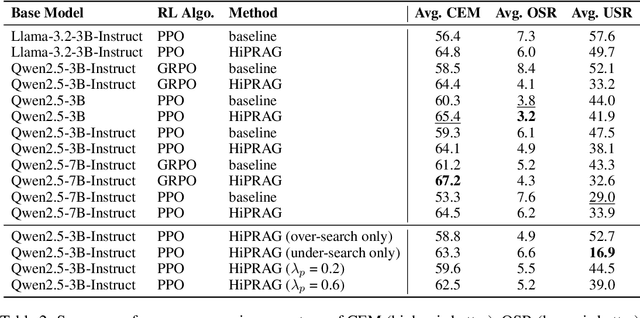
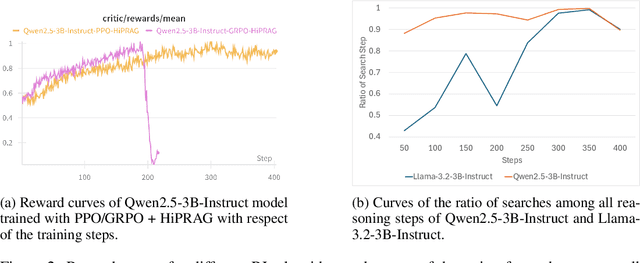
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
Give Me FP32 or Give Me Death? Challenges and Solutions for Reproducible Reasoning
Jun 11, 2025Large Language Models (LLMs) are now integral across various domains and have demonstrated impressive performance. Progress, however, rests on the premise that benchmark scores are both accurate and reproducible. We demonstrate that the reproducibility of LLM performance is fragile: changing system configuration such as evaluation batch size, GPU count, and GPU version can introduce significant difference in the generated responses. This issue is especially pronounced in reasoning models, where minor rounding differences in early tokens can cascade into divergent chains of thought, ultimately affecting accuracy. For instance, under bfloat16 precision with greedy decoding, a reasoning model like DeepSeek-R1-Distill-Qwen-7B can exhibit up to 9% variation in accuracy and 9,000 tokens difference in response length due to differences in GPU count, type, and evaluation batch size. We trace the root cause of this variability to the non-associative nature of floating-point arithmetic under limited numerical precision. This work presents the first systematic investigation into how numerical precision affects reproducibility in LLM inference. Through carefully controlled experiments across various hardware, software, and precision settings, we quantify when and how model outputs diverge. Our analysis reveals that floating-point precision -- while critical for reproducibility -- is often neglected in evaluation practices. Inspired by this, we develop a lightweight inference pipeline, dubbed LayerCast, that stores weights in 16-bit precision but performs all computations in FP32, balancing memory efficiency with numerical stability. Code is available at https://github.com/nanomaoli/llm_reproducibility.
DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
Apr 13, 2025Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.
Prompt-Guided Mask Proposal for Two-Stage Open-Vocabulary Segmentation
Dec 13, 2024



We tackle the challenge of open-vocabulary segmentation, where we need to identify objects from a wide range of categories in different environments, using text prompts as our input. To overcome this challenge, existing methods often use multi-modal models like CLIP, which combine image and text features in a shared embedding space to bridge the gap between limited and extensive vocabulary recognition, resulting in a two-stage approach: In the first stage, a mask generator takes an input image to generate mask proposals, and the in the second stage the target mask is picked based on the query. However, the expected target mask may not exist in the generated mask proposals, which leads to an unexpected output mask. In our work, we propose a novel approach named Prompt-guided Mask Proposal (PMP) where the mask generator takes the input text prompts and generates masks guided by these prompts. Compared with mask proposals generated without input prompts, masks generated by PMP are better aligned with the input prompts. To realize PMP, we designed a cross-attention mechanism between text tokens and query tokens which is capable of generating prompt-guided mask proposals after each decoding. We combined our PMP with several existing works employing a query-based segmentation backbone and the experiments on five benchmark datasets demonstrate the effectiveness of this approach, showcasing significant improvements over the current two-stage models (1% ~ 3% absolute performance gain in terms of mIOU). The steady improvement in performance across these benchmarks indicates the effective generalization of our proposed lightweight prompt-aware method.
Efficient Self-Improvement in Multimodal Large Language Models: A Model-Level Judge-Free Approach
Nov 26, 2024



Self-improvement in multimodal large language models (MLLMs) is crucial for enhancing their reliability and robustness. However, current methods often rely heavily on MLLMs themselves as judges, leading to high computational costs and potential pitfalls like reward hacking and model collapse. This paper introduces a novel, model-level judge-free self-improvement framework. Our approach employs a controlled feedback mechanism while eliminating the need for MLLMs in the verification loop. We generate preference learning pairs using a controllable hallucination mechanism and optimize data quality by leveraging lightweight, contrastive language-image encoders to evaluate and reverse pairs when necessary. Evaluations across public benchmarks and our newly introduced IC dataset designed to challenge hallucination control demonstrate that our model outperforms conventional techniques. We achieve superior precision and recall with significantly lower computational demands. This method offers an efficient pathway to scalable self-improvement in MLLMs, balancing performance gains with reduced resource requirements.
Quadratic Is Not What You Need For Multimodal Large Language Models
Oct 08, 2024



In the past year, the capabilities of Multimodal Large Language Models (MLLMs) have significantly improved across various aspects. However, constrained by the quadratic growth of computation in LLMs as the number of tokens increases, efficiency has become a bottleneck for further scaling MLLMs. Although recent efforts have been made to prune visual tokens or use more lightweight LLMs to reduce computation, the problem of quadratic growth in computation with the increase of visual tokens still persists. To address this, we propose a novel approach: instead of reducing the input visual tokens for LLMs, we focus on pruning vision-related computations within the LLMs. After pruning, the computation growth in the LLM is no longer quadratic with the increase of visual tokens, but linear. Surprisingly, we found that after applying such extensive pruning, the capabilities of MLLMs are comparable with the original one and even superior on some benchmarks with only 25% of the computation. This finding opens up the possibility for MLLMs to incorporate much denser visual tokens. Additionally, based on this finding, we further analyzed some architectural design deficiencies in existing MLLMs and proposed promising improvements. To the best of our knowledge, this is the first study to investigate the computational redundancy in the LLM's vision component of MLLMs. Code and checkpoints will be released soon.
DL3DV-10K: A Large-Scale Scene Dataset for Deep Learning-based 3D Vision
Dec 29, 2023



We have witnessed significant progress in deep learning-based 3D vision, ranging from neural radiance field (NeRF) based 3D representation learning to applications in novel view synthesis (NVS). However, existing scene-level datasets for deep learning-based 3D vision, limited to either synthetic environments or a narrow selection of real-world scenes, are quite insufficient. This insufficiency not only hinders a comprehensive benchmark of existing methods but also caps what could be explored in deep learning-based 3D analysis. To address this critical gap, we present DL3DV-10K, a large-scale scene dataset, featuring 51.2 million frames from 10,510 videos captured from 65 types of point-of-interest (POI) locations, covering both bounded and unbounded scenes, with different levels of reflection, transparency, and lighting. We conducted a comprehensive benchmark of recent NVS methods on DL3DV-10K, which revealed valuable insights for future research in NVS. In addition, we have obtained encouraging results in a pilot study to learn generalizable NeRF from DL3DV-10K, which manifests the necessity of a large-scale scene-level dataset to forge a path toward a foundation model for learning 3D representation. Our DL3DV-10K dataset, benchmark results, and models will be publicly accessible at https://dl3dv-10k.github.io/DL3DV-10K/.
Penetrating the Fog: the Path to Efficient CNN Models
Oct 11, 2018
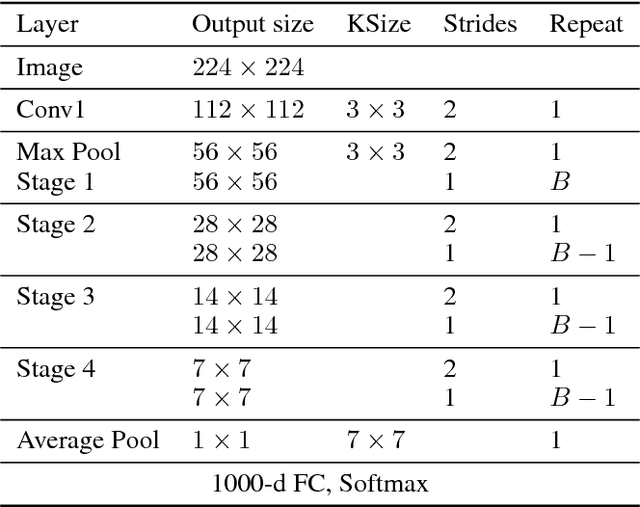
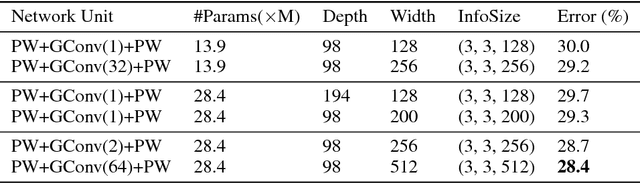
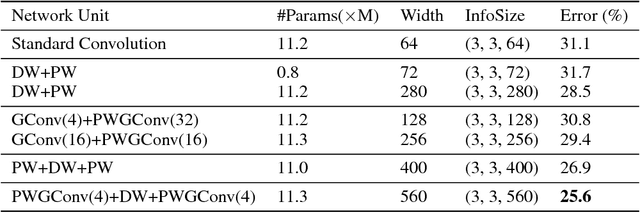
With the increasing demand to deploy convolutional neural networks (CNNs) on mobile platforms, the sparse kernel approach was proposed, which could save more parameters than the standard convolution while maintaining accuracy. However, despite the great potential, no prior research has pointed out how to craft an sparse kernel design with such potential (i.e., effective design), and all prior works just adopt simple combinations of existing sparse kernels such as group convolution. Meanwhile due to the large design space it is also impossible to try all combinations of existing sparse kernels. In this paper, we are the first in the field to consider how to craft an effective sparse kernel design by eliminating the large design space. Specifically, we present a sparse kernel scheme to illustrate how to reduce the space from three aspects. First, in terms of composition we remove designs composed of repeated layers. Second, to remove designs with large accuracy degradation, we find an unified property named information field behind various sparse kernel designs, which could directly indicate the final accuracy. Last, we remove designs in two cases where a better parameter efficiency could be achieved. Additionally, we provide detailed efficiency analysis on the final four designs in our scheme. Experimental results validate the idea of our scheme by showing that our scheme is able to find designs which are more efficient in using parameters and computation with similar or higher accuracy.
Domain-Adversarial Multi-Task Framework for Novel Therapeutic Property Prediction of Compounds
Sep 28, 2018

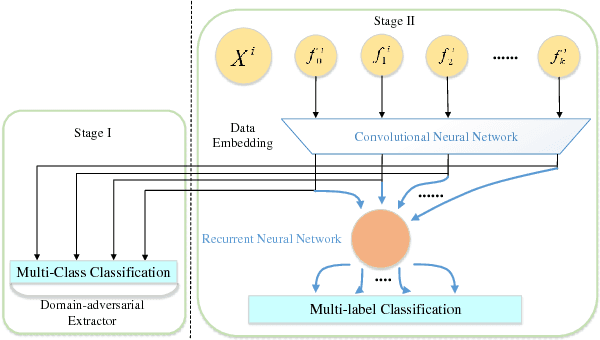
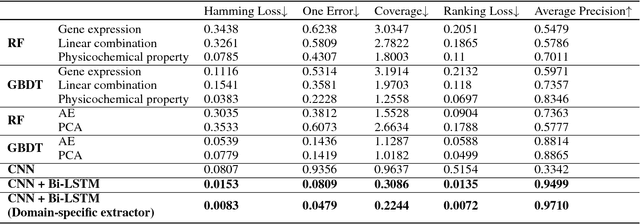
With the rapid development of high-throughput technologies, parallel acquisition of large-scale drug-informatics data provides huge opportunities to improve pharmaceutical research and development. One significant application is the purpose prediction of small molecule compounds, aiming to specify therapeutic properties of extensive purpose-unknown compounds and to repurpose novel therapeutic properties of FDA-approved drugs. Such problem is very challenging since compound attributes contain heterogeneous data with various feature patterns such as drug fingerprint, drug physicochemical property, drug perturbation gene expression. Moreover, there is complex nonlinear dependency among heterogeneous data. In this paper, we propose a novel domain-adversarial multi-task framework for integrating shared knowledge from multiple domains. The framework utilizes the adversarial strategy to effectively learn target representations and models their nonlinear dependency. Experiments on two real-world datasets illustrate that the performance of our approach obtains an obvious improvement over competitive baselines. The novel therapeutic properties of purpose-unknown compounds we predicted are mostly reported or brought to the clinics. Furthermore, our framework can integrate various attributes beyond the three domains examined here and can be applied in the industry for screening the purpose of huge amounts of as yet unidentified compounds. Source codes of this paper are available on Github.
Reconciling Feature-Reuse and Overfitting in DenseNet with Specialized Dropout
Sep 28, 2018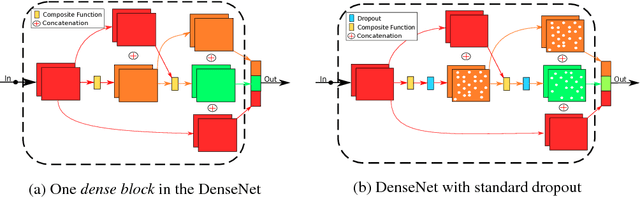
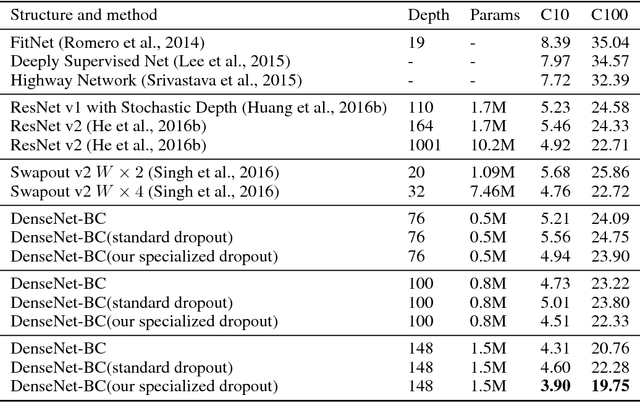
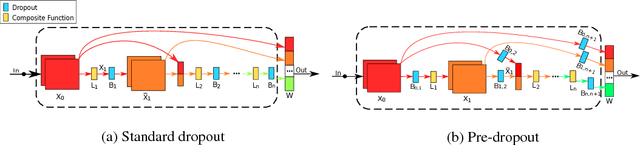
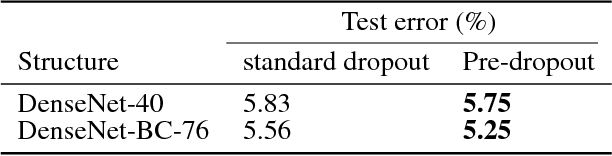
Recently convolutional neural networks (CNNs) achieve great accuracy in visual recognition tasks. DenseNet becomes one of the most popular CNN models due to its effectiveness in feature-reuse. However, like other CNN models, DenseNets also face overfitting problem if not severer. Existing dropout method can be applied but not as effective due to the introduced nonlinear connections. In particular, the property of feature-reuse in DenseNet will be impeded, and the dropout effect will be weakened by the spatial correlation inside feature maps. To address these problems, we craft the design of a specialized dropout method from three aspects, dropout location, dropout granularity, and dropout probability. The insights attained here could potentially be applied as a general approach for boosting the accuracy of other CNN models with similar nonlinear connections. Experimental results show that DenseNets with our specialized dropout method yield better accuracy compared to vanilla DenseNet and state-of-the-art CNN models, and such accuracy boost increases with the model depth.