 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChipBench: A Next-Step Benchmark for Evaluating LLM Performance in AI-Aided Chip Design
Jan 29, 2026While Large Language Models (LLMs) show significant potential in hardware engineering, current benchmarks suffer from saturation and limited task diversity, failing to reflect LLMs' performance in real industrial workflows. To address this gap, we propose a comprehensive benchmark for AI-aided chip design that rigorously evaluates LLMs across three critical tasks: Verilog generation, debugging, and reference model generation. Our benchmark features 44 realistic modules with complex hierarchical structures, 89 systematic debugging cases, and 132 reference model samples across Python, SystemC, and CXXRTL. Evaluation results reveal substantial performance gaps, with state-of-the-art Claude-4.5-opus achieving only 30.74\% on Verilog generation and 13.33\% on Python reference model generation, demonstrating significant challenges compared to existing saturated benchmarks where SOTA models achieve over 95\% pass rates. Additionally, to help enhance LLM reference model generation, we provide an automated toolbox for high-quality training data generation, facilitating future research in this underexplored domain. Our code is available at https://github.com/zhongkaiyu/ChipBench.git.
ScaleSim: Serving Large-Scale Multi-Agent Simulation with Invocation Distance-Based Memory Management
Jan 29, 2026LLM-based multi-agent simulations are increasingly adopted across application domains, but remain difficult to scale due to GPU memory pressure. Each agent maintains private GPU-resident states, including models, prefix caches, and adapters, which quickly exhaust device memory as the agent count grows. We identify two key properties of these workloads: sparse agent activation and an estimable agent invocation order. Based on an analysis of representative workload classes, we introduce invocation distance, a unified abstraction that estimates the relative order in which agents will issue future LLM requests. Leveraging this abstraction, we present ScaleSim, a memory-efficient LLM serving system for large-scale multi-agent simulations. ScaleSim enables proactive prefetching and priority-based eviction, supports diverse agent-specific memory through a modular interface, and achieves up to 1.74x speedup over SGLang on simulation benchmarks.
Rethinking Video Generation Model for the Embodied World
Jan 21, 2026Video generation models have significantly advanced embodied intelligence, unlocking new possibilities for generating diverse robot data that capture perception, reasoning, and action in the physical world. However, synthesizing high-quality videos that accurately reflect real-world robotic interactions remains challenging, and the lack of a standardized benchmark limits fair comparisons and progress. To address this gap, we introduce a comprehensive robotics benchmark, RBench, designed to evaluate robot-oriented video generation across five task domains and four distinct embodiments. It assesses both task-level correctness and visual fidelity through reproducible sub-metrics, including structural consistency, physical plausibility, and action completeness. Evaluation of 25 representative models highlights significant deficiencies in generating physically realistic robot behaviors. Furthermore, the benchmark achieves a Spearman correlation coefficient of 0.96 with human evaluations, validating its effectiveness. While RBench provides the necessary lens to identify these deficiencies, achieving physical realism requires moving beyond evaluation to address the critical shortage of high-quality training data. Driven by these insights, we introduce a refined four-stage data pipeline, resulting in RoVid-X, the largest open-source robotic dataset for video generation with 4 million annotated video clips, covering thousands of tasks and enriched with comprehensive physical property annotations. Collectively, this synergistic ecosystem of evaluation and data establishes a robust foundation for rigorous assessment and scalable training of video models, accelerating the evolution of embodied AI toward general intelligence.
Yggdrasil: Bridging Dynamic Speculation and Static Runtime for Latency-Optimal Tree-Based LLM Decoding
Dec 29, 2025Speculative decoding improves LLM inference by generating and verifying multiple tokens in parallel, but existing systems suffer from suboptimal performance due to a mismatch between dynamic speculation and static runtime assumptions. We present Yggdrasil, a co-designed system that enables latency-optimal speculative decoding through context-aware tree drafting and compiler-friendly execution. Yggdrasil introduces an equal-growth tree structure for static graph compatibility, a latency-aware optimization objective for draft selection, and stage-based scheduling to reduce overhead. Yggdrasil supports unmodified LLMs and achieves up to $3.98\times$ speedup over state-of-the-art baselines across multiple hardware setups.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025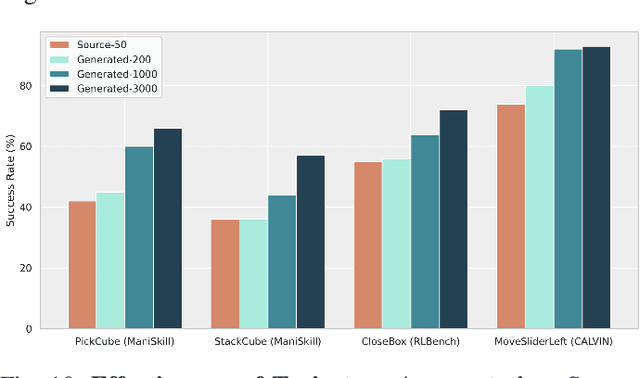



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025


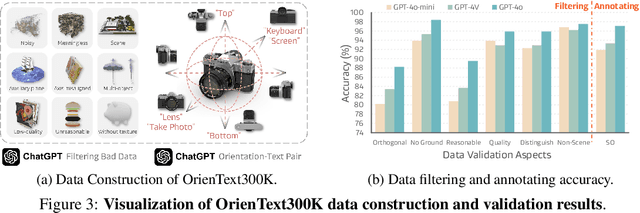
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes
Oct 30, 2024



Grasping in cluttered scenes remains highly challenging for dexterous hands due to the scarcity of data. To address this problem, we present a large-scale synthetic benchmark, encompassing 1319 objects, 8270 scenes, and 427 million grasps. Beyond benchmarking, we also propose a novel two-stage grasping method that learns efficiently from data by using a diffusion model that conditions on local geometry. Our proposed generative method outperforms all baselines in simulation experiments. Furthermore, with the aid of test-time-depth restoration, our method demonstrates zero-shot sim-to-real transfer, attaining 90.7% real-world dexterous grasping success rate in cluttered scenes.
A Geometrical Approach to Evaluate the Adversarial Robustness of Deep Neural Networks
Oct 10, 2023



Deep Neural Networks (DNNs) are widely used for computer vision tasks. However, it has been shown that deep models are vulnerable to adversarial attacks, i.e., their performances drop when imperceptible perturbations are made to the original inputs, which may further degrade the following visual tasks or introduce new problems such as data and privacy security. Hence, metrics for evaluating the robustness of deep models against adversarial attacks are desired. However, previous metrics are mainly proposed for evaluating the adversarial robustness of shallow networks on the small-scale datasets. Although the Cross Lipschitz Extreme Value for nEtwork Robustness (CLEVER) metric has been proposed for large-scale datasets (e.g., the ImageNet dataset), it is computationally expensive and its performance relies on a tractable number of samples. In this paper, we propose the Adversarial Converging Time Score (ACTS), an attack-dependent metric that quantifies the adversarial robustness of a DNN on a specific input. Our key observation is that local neighborhoods on a DNN's output surface would have different shapes given different inputs. Hence, given different inputs, it requires different time for converging to an adversarial sample. Based on this geometry meaning, ACTS measures the converging time as an adversarial robustness metric. We validate the effectiveness and generalization of the proposed ACTS metric against different adversarial attacks on the large-scale ImageNet dataset using state-of-the-art deep networks. Extensive experiments show that our ACTS metric is an efficient and effective adversarial metric over the previous CLEVER metric.
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022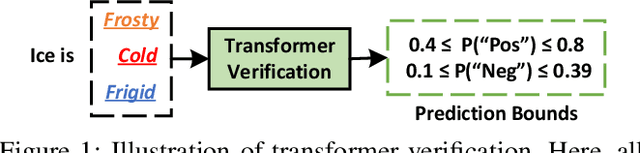

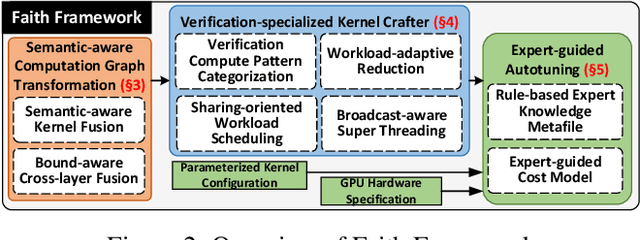
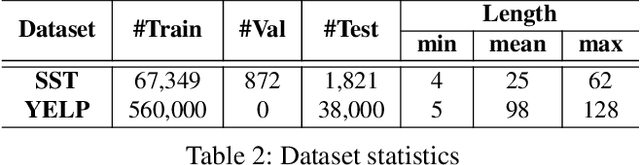
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Empowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Sep 14, 2022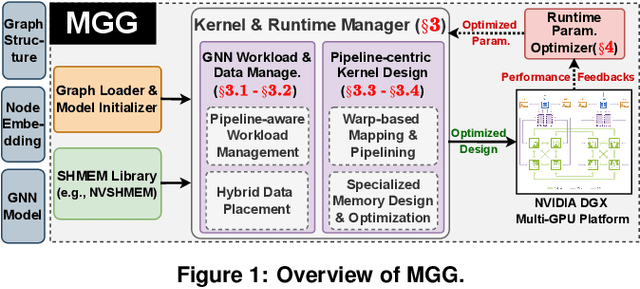

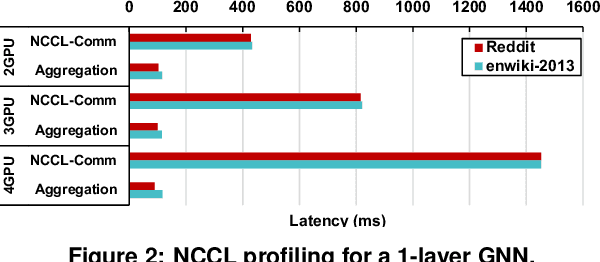

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.