 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic N:M Fine-grained Structured Sparse Attention Mechanism
Feb 28, 2022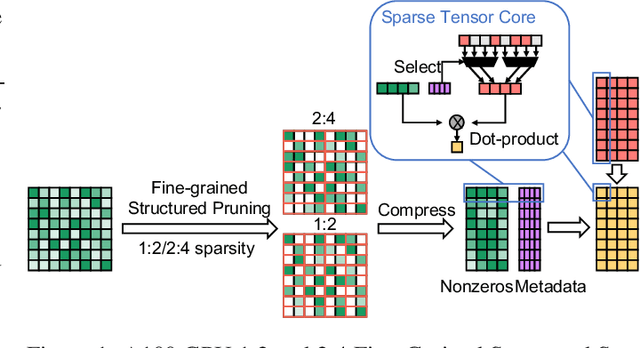
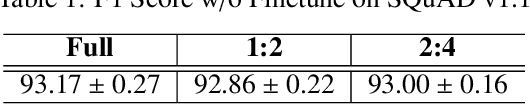
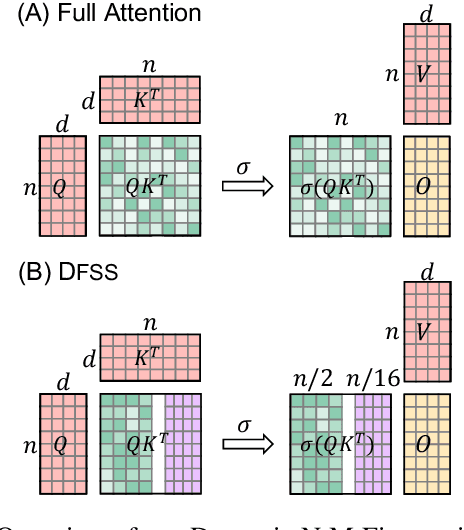
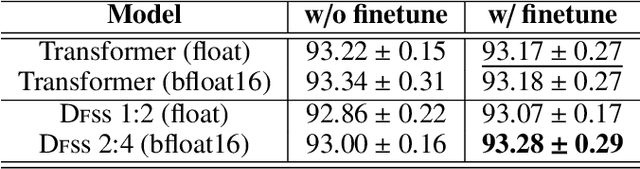
Transformers are becoming the mainstream solutions for various tasks like NLP and Computer vision. Despite their success, the high complexity of the attention mechanism hinders them from being applied to latency-sensitive tasks. Tremendous efforts have been made to alleviate this problem, and many of them successfully reduce the asymptotic complexity to linear. Nevertheless, most of them fail to achieve practical speedup over the original full attention under moderate sequence lengths and are unfriendly to finetuning. In this paper, we present DFSS, an attention mechanism that dynamically prunes the full attention weight matrix to N:M fine-grained structured sparse pattern. We provide both theoretical and empirical evidence that demonstrates DFSS is a good approximation of the full attention mechanism. We propose a dedicated CUDA kernel design that completely eliminates the dynamic pruning overhead and achieves speedups under arbitrary sequence length. We evaluate the 1:2 and 2:4 sparsity under different configurations and achieve 1.27~ 1.89x speedups over the full-attention mechanism. It only takes a couple of finetuning epochs from the pretrained model to achieve on par accuracy with full attention mechanism on tasks from various domains under different sequence lengths from 384 to 4096.