 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022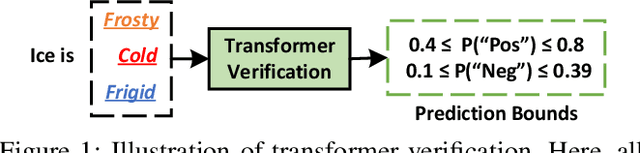

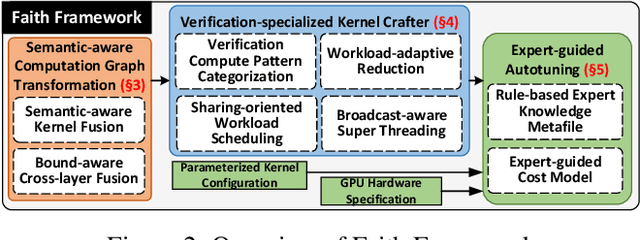
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Dynamic N:M Fine-grained Structured Sparse Attention Mechanism
Feb 28, 2022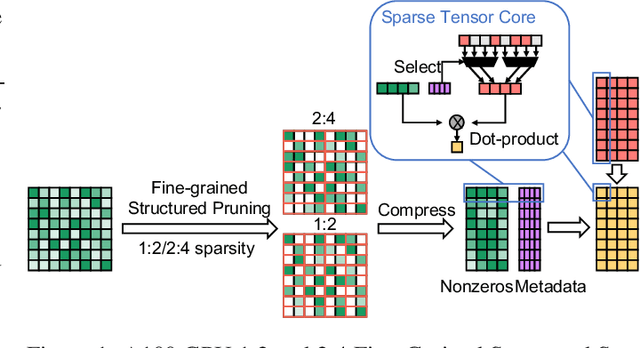
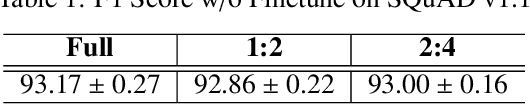
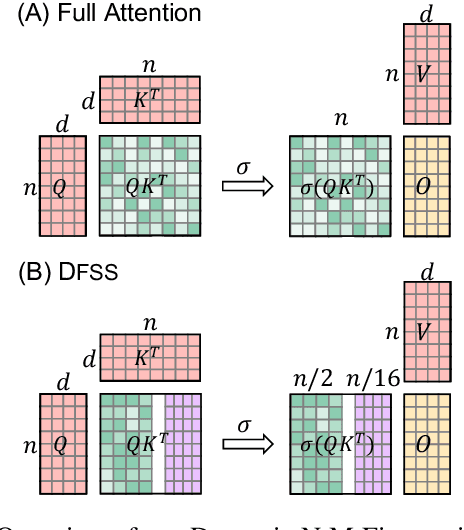
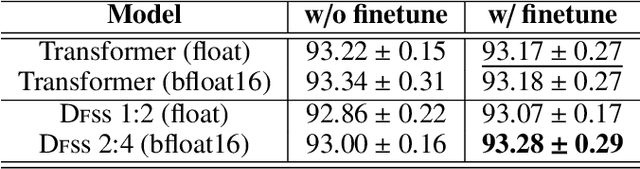
Transformers are becoming the mainstream solutions for various tasks like NLP and Computer vision. Despite their success, the high complexity of the attention mechanism hinders them from being applied to latency-sensitive tasks. Tremendous efforts have been made to alleviate this problem, and many of them successfully reduce the asymptotic complexity to linear. Nevertheless, most of them fail to achieve practical speedup over the original full attention under moderate sequence lengths and are unfriendly to finetuning. In this paper, we present DFSS, an attention mechanism that dynamically prunes the full attention weight matrix to N:M fine-grained structured sparse pattern. We provide both theoretical and empirical evidence that demonstrates DFSS is a good approximation of the full attention mechanism. We propose a dedicated CUDA kernel design that completely eliminates the dynamic pruning overhead and achieves speedups under arbitrary sequence length. We evaluate the 1:2 and 2:4 sparsity under different configurations and achieve 1.27~ 1.89x speedups over the full-attention mechanism. It only takes a couple of finetuning epochs from the pretrained model to achieve on par accuracy with full attention mechanism on tasks from various domains under different sequence lengths from 384 to 4096.
Transformer Acceleration with Dynamic Sparse Attention
Oct 21, 2021
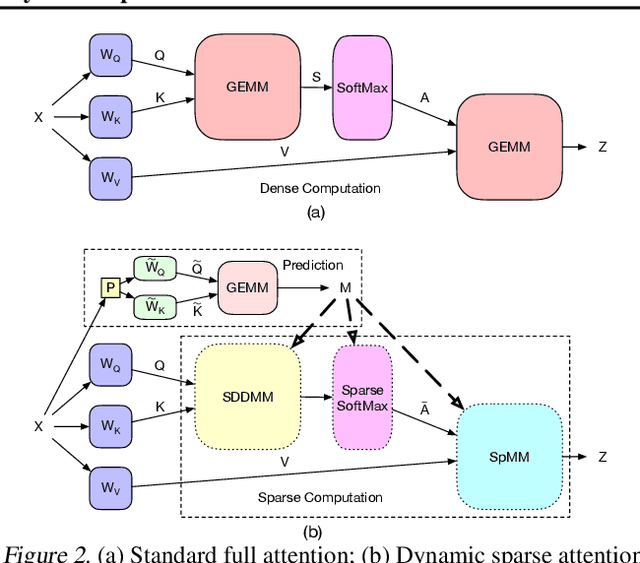
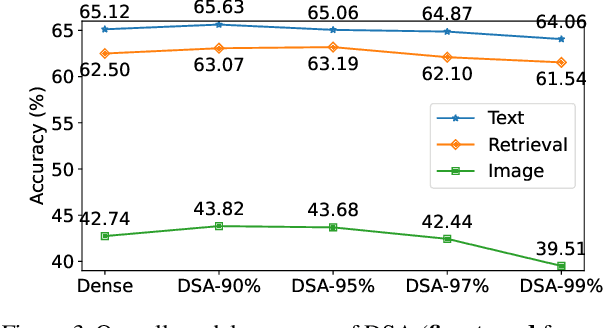
Transformers are the mainstream of NLP applications and are becoming increasingly popular in other domains such as Computer Vision. Despite the improvements in model quality, the enormous computation costs make Transformers difficult at deployment, especially when the sequence length is large in emerging applications. Processing attention mechanism as the essential component of Transformer is the bottleneck of execution due to the quadratic complexity. Prior art explores sparse patterns in attention to support long sequence modeling, but those pieces of work are on static or fixed patterns. We demonstrate that the sparse patterns are dynamic, depending on input sequences. Thus, we propose the Dynamic Sparse Attention (DSA) that can efficiently exploit the dynamic sparsity in the attention of Transformers. Compared with other methods, our approach can achieve better trade-offs between accuracy and model complexity. Moving forward, we identify challenges and provide solutions to implement DSA on existing hardware (GPUs) and specialized hardware in order to achieve practical speedup and efficiency improvements for Transformer execution.
H2Learn: High-Efficiency Learning Accelerator for High-Accuracy Spiking Neural Networks
Jul 25, 2021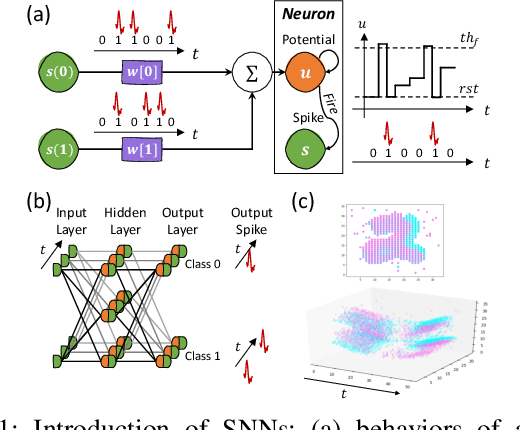
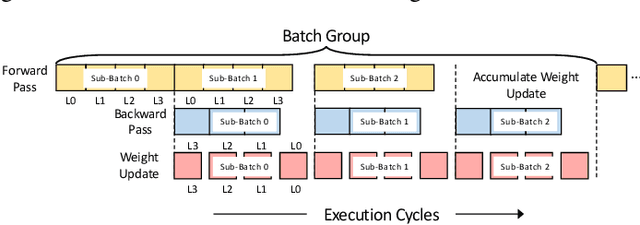
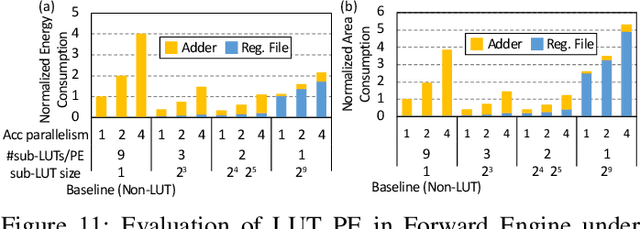
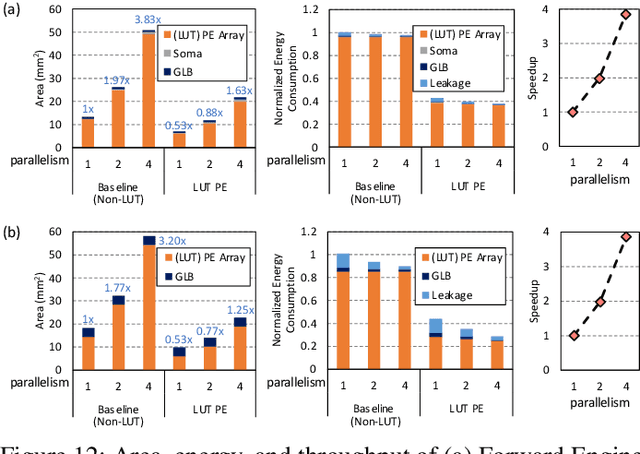
Although spiking neural networks (SNNs) take benefits from the bio-plausible neural modeling, the low accuracy under the common local synaptic plasticity learning rules limits their application in many practical tasks. Recently, an emerging SNN supervised learning algorithm inspired by backpropagation through time (BPTT) from the domain of artificial neural networks (ANNs) has successfully boosted the accuracy of SNNs and helped improve the practicability of SNNs. However, current general-purpose processors suffer from low efficiency when performing BPTT for SNNs due to the ANN-tailored optimization. On the other hand, current neuromorphic chips cannot support BPTT because they mainly adopt local synaptic plasticity rules for simplified implementation. In this work, we propose H2Learn, a novel architecture that can achieve high efficiency for BPTT-based SNN learning which ensures high accuracy of SNNs. At the beginning, we characterized the behaviors of BPTT-based SNN learning. Benefited from the binary spike-based computation in the forward pass and the weight update, we first design lookup table (LUT) based processing elements in Forward Engine and Weight Update Engine to make accumulations implicit and to fuse the computations of multiple input points. Second, benefited from the rich sparsity in the backward pass, we design a dual-sparsity-aware Backward Engine which exploits both input and output sparsity. Finally, we apply a pipeline optimization between different engines to build an end-to-end solution for the BPTT-based SNN learning. Compared with the modern NVIDIA V100 GPU, H2Learn achieves 7.38x area saving, 5.74-10.20x speedup, and 5.25-7.12x energy saving on several benchmark datasets.
A Comprehensive and Modularized Statistical Framework for Gradient Norm Equality in Deep Neural Networks
Jan 01, 2020

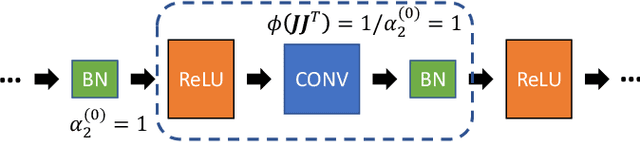
In recent years, plenty of metrics have been proposed to identify networks that are free of gradient explosion and vanishing. However, due to the diversity of network components and complex serial-parallel hybrid connections in modern DNNs, the evaluation of existing metrics usually requires strong assumptions, complex statistical analysis, or has limited application fields, which constraints their spread in the community. In this paper, inspired by the Gradient Norm Equality and dynamical isometry, we first propose a novel metric called Block Dynamical Isometry, which measures the change of gradient norm in individual block. Because our Block Dynamical Isometry is norm-based, its evaluation needs weaker assumptions compared with the original dynamical isometry. To mitigate the challenging derivation, we propose a highly modularized statistical framework based on free probability. Our framework includes several key theorems to handle complex serial-parallel hybrid connections and a library to cover the diversity of network components. Besides, several sufficient prerequisites are provided. Powered by our metric and framework, we analyze extensive initialization, normalization, and network structures. We find that Gradient Norm Equality is a universal philosophy behind them. Then, we improve some existing methods based on our analysis, including an activation function selection strategy for initialization techniques, a new configuration for weight normalization, and a depth-aware way to derive coefficients in SeLU. Moreover, we propose a novel normalization technique named second moment normalization, which is theoretically 30% faster than batch normalization without accuracy loss. Last but not least, our conclusions and methods are evidenced by extensive experiments on multiple models over CIFAR10 and ImageNet.
Hardness-Aware Deep Metric Learning
Mar 13, 2019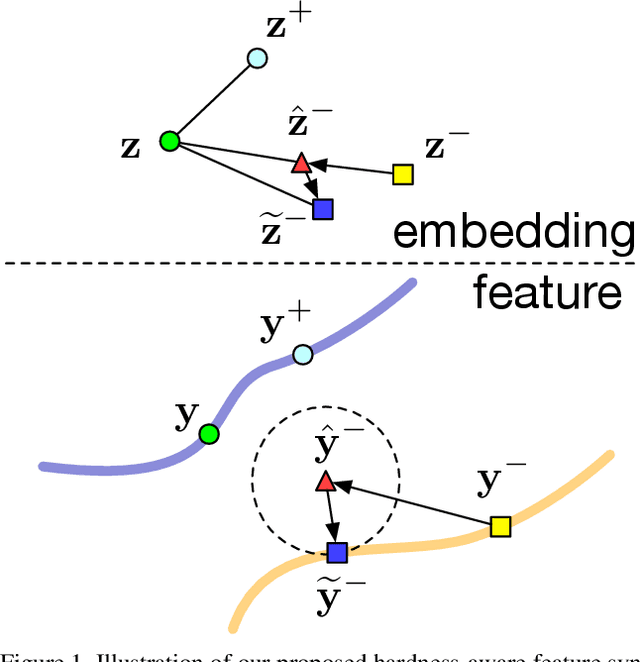
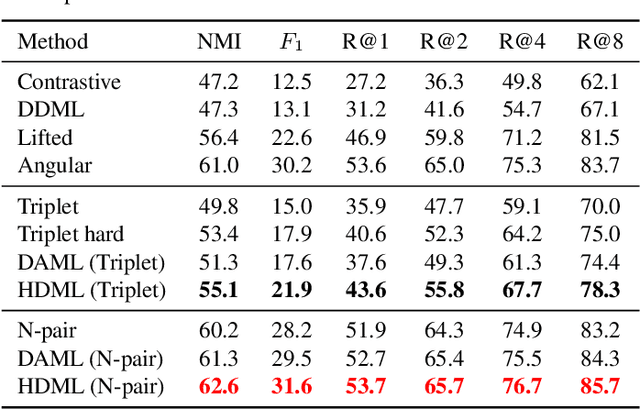
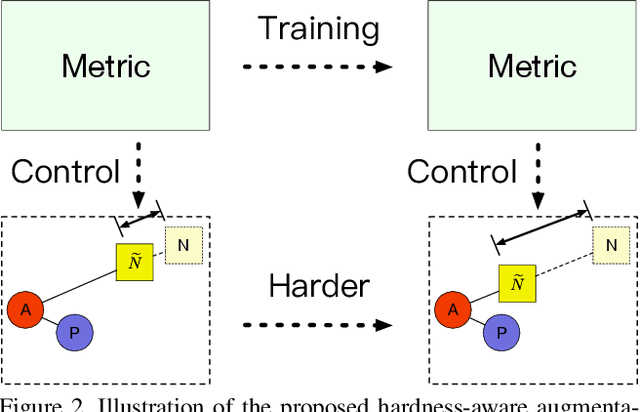
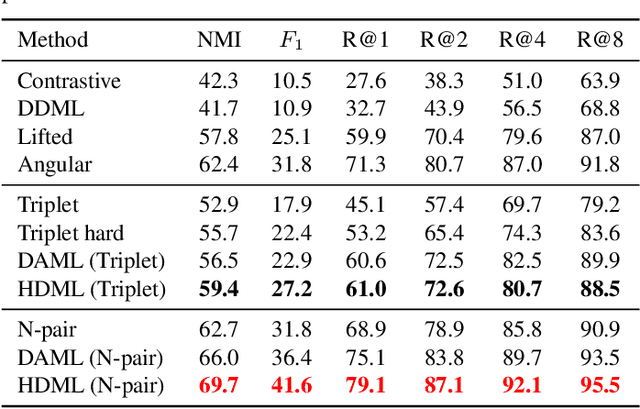
This paper presents a hardness-aware deep metric learning (HDML) framework. Most previous deep metric learning methods employ the hard negative mining strategy to alleviate the lack of informative samples for training. However, this mining strategy only utilizes a subset of training data, which may not be enough to characterize the global geometry of the embedding space comprehensively. To address this problem, we perform linear interpolation on embeddings to adaptively manipulate their hard levels and generate corresponding label-preserving synthetics for recycled training, so that information buried in all samples can be fully exploited and the metric is always challenged with proper difficulty. Our method achieves very competitive performance on the widely used CUB-200-2011, Cars196, and Stanford Online Products datasets.
Batch Normalization Sampling
Nov 02, 2018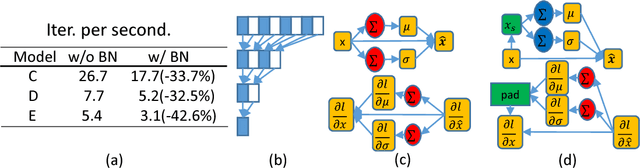
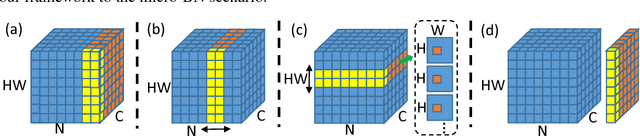
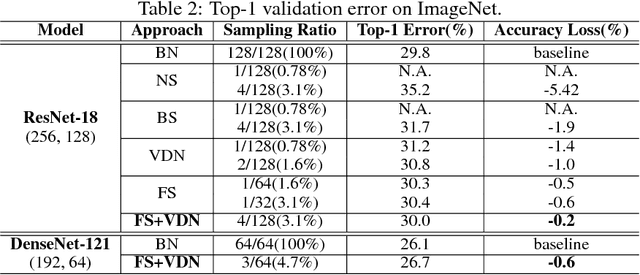
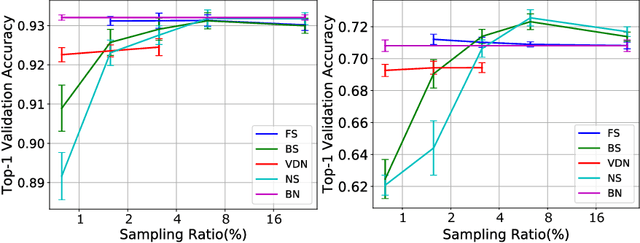
Deep Neural Networks (DNNs) thrive in recent years in which Batch Normalization (BN) plays an indispensable role. However, it has been observed that BN is costly due to the reduction operations. In this paper, we propose alleviating this problem through sampling only a small fraction of data for normalization at each iteration. Specifically, we model it as a statistical sampling problem and identify that by sampling less correlated data, we can largely reduce the requirement of the number of data for statistics estimation in BN, which directly simplifies the reduction operations. Based on this conclusion, we propose two sampling strategies, "Batch Sampling" (randomly select several samples from each batch) and "Feature Sampling" (randomly select a small patch from each feature map of all samples), that take both computational efficiency and sample correlation into consideration. Furthermore, we introduce an extremely simple variant of BN, termed as Virtual Dataset Normalization (VDN), that can normalize the activations well with few synthetical random samples. All the proposed methods are evaluated on various datasets and networks, where an overall training speedup by up to 20% on GPU is practically achieved without the support of any specialized libraries, and the loss on accuracy and convergence rate are negligible. Finally, we extend our work to the "micro-batch normalization" problem and yield comparable performance with existing approaches at the case of tiny batch size.