 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLCo-Bench: VIdeo Language COntinual learning Benchmark
Jun 19, 2024



Video language continual learning involves continuously adapting to information from video and text inputs, enhancing a model's ability to handle new tasks while retaining prior knowledge. This field is a relatively under-explored area, and establishing appropriate datasets is crucial for facilitating communication and research in this field. In this study, we present the first dedicated benchmark, ViLCo-Bench, designed to evaluate continual learning models across a range of video-text tasks. The dataset comprises ten-minute-long videos and corresponding language queries collected from publicly available datasets. Additionally, we introduce a novel memory-efficient framework that incorporates self-supervised learning and mimics long-term and short-term memory effects. This framework addresses challenges including memory complexity from long video clips, natural language complexity from open queries, and text-video misalignment. We posit that ViLCo-Bench, with greater complexity compared to existing continual learning benchmarks, would serve as a critical tool for exploring the video-language domain, extending beyond conventional class-incremental tasks, and addressing complex and limited annotation issues. The curated data, evaluations, and our novel method are available at https://github.com/cruiseresearchgroup/ViLCo .
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022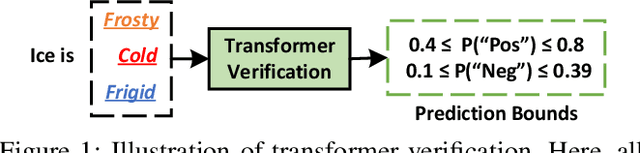

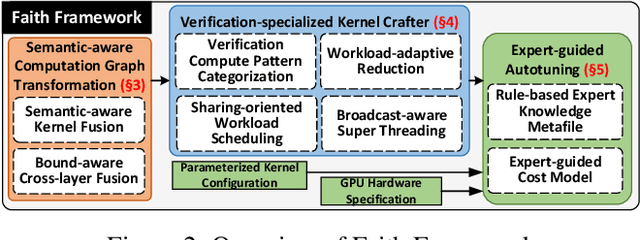
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.