 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDiT: Semantic Region-Adaptive for Diffusion Transformers
Jan 18, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in text-to-image synthesis but remain computationally expensive due to the iterative nature of denoising and the quadratic cost of global attention. In this work, we observe that denoising dynamics are spatially non-uniform-background regions converge rapidly while edges and textured areas evolve much more actively. Building on this insight, we propose SDiT, a Semantic Region-Adaptive Diffusion Transformer that allocates computation according to regional complexity. SDiT introduces a training-free framework combining (1) semantic-aware clustering via fast Quickshift-based segmentation, (2) complexity-driven regional scheduling to selectively update informative areas, and (3) boundary-aware refinement to maintain spatial coherence. Without any model retraining or architectural modification, SDiT achieves up to 3.0x acceleration while preserving nearly identical perceptual and semantic quality to full-attention inference.
LeJOT: An Intelligent Job Cost Orchestration Solution for Databricks Platform
Dec 20, 2025With the rapid advancements in big data technologies, the Databricks platform has become a cornerstone for enterprises and research institutions, offering high computational efficiency and a robust ecosystem. However, managing the escalating operational costs associated with job execution remains a critical challenge. Existing solutions rely on static configurations or reactive adjustments, which fail to adapt to the dynamic nature of workloads. To address this, we introduce LeJOT, an intelligent job cost orchestration framework that leverages machine learning for execution time prediction and a solver-based optimization model for real-time resource allocation. Unlike conventional scheduling techniques, LeJOT proactively predicts workload demands, dynamically allocates computing resources, and minimizes costs while ensuring performance requirements are met. Experimental results on real-world Databricks workloads demonstrate that LeJOT achieves an average 20% reduction in cloud computing costs within a minute-level scheduling timeframe, outperforming traditional static allocation strategies. Our approach provides a scalable and adaptive solution for cost-efficient job scheduling in Data Lakehouse environments.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
Utilizing Sequential Information of General Lab-test Results and Diagnoses History for Differential Diagnosis of Dementia
Feb 21, 2025



Early diagnosis of Alzheimer's Disease (AD) faces multiple data-related challenges, including high variability in patient data, limited access to specialized diagnostic tests, and overreliance on single-type indicators. These challenges are exacerbated by the progressive nature of AD, where subtle pathophysiological changes often precede clinical symptoms by decades. To address these limitations, this study proposes a novel approach that takes advantage of routinely collected general laboratory test histories for the early detection and differential diagnosis of AD. By modeling lab test sequences as "sentences", we apply word embedding techniques to capture latent relationships between tests and employ deep time series models, including long-short-term memory (LSTM) and Transformer networks, to model temporal patterns in patient records. Experimental results demonstrate that our approach improves diagnostic accuracy and enables scalable and costeffective AD screening in diverse clinical settings.
The Study of Perceptual Training of Chinese Mandarin Tones for Monolingual Speakers of English Using Adaptive Computer Based Training Software
Sep 24, 2023


The study explored a new technique of phonetic tone training, which may have a positive impact on second language learning and tone training.
Faith: An Efficient Framework for Transformer Verification on GPUs
Sep 23, 2022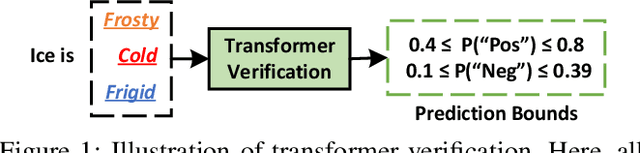

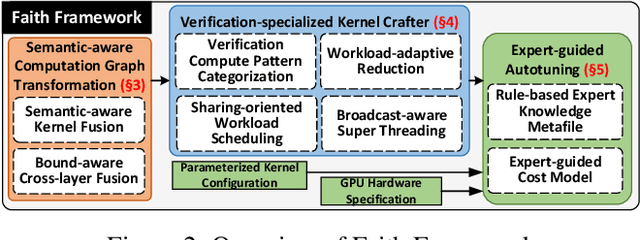
Transformer verification draws increasing attention in machine learning research and industry. It formally verifies the robustness of transformers against adversarial attacks such as exchanging words in a sentence with synonyms. However, the performance of transformer verification is still not satisfactory due to bound-centric computation which is significantly different from standard neural networks. In this paper, we propose Faith, an efficient framework for transformer verification on GPUs. We first propose a semantic-aware computation graph transformation to identify semantic information such as bound computation in transformer verification. We exploit such semantic information to enable efficient kernel fusion at the computation graph level. Second, we propose a verification-specialized kernel crafter to efficiently map transformer verification to modern GPUs. This crafter exploits a set of GPU hardware supports to accelerate verification specialized operations which are usually memory-intensive. Third, we propose an expert-guided autotuning to incorporate expert knowledge on GPU backends to facilitate large search space exploration. Extensive evaluations show that Faith achieves $2.1\times$ to $3.4\times$ ($2.6\times$ on average) speedup over state-of-the-art frameworks.
Empowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Sep 14, 2022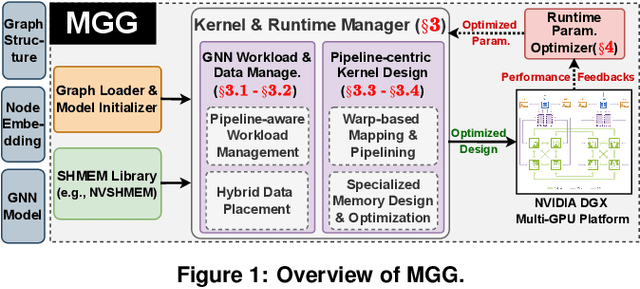

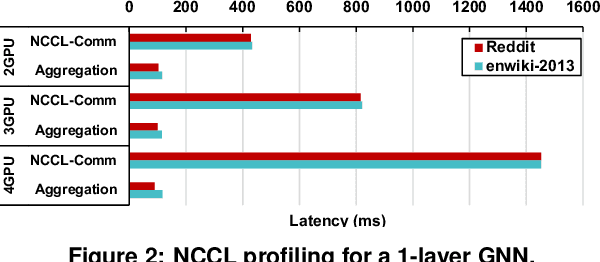

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.
TC-GNN: Accelerating Sparse Graph Neural Network Computation Via Dense Tensor Core on GPUs
Dec 03, 2021
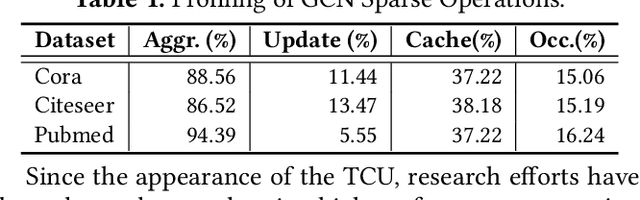
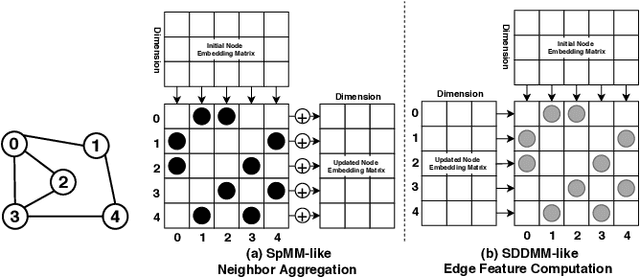

Recently, graph neural networks (GNNs), as the backbone of graph-based machine learning, demonstrate great success in various domains (e.g., e-commerce). However, the performance of GNNs is usually unsatisfactory due to the highly sparse and irregular graph-based operations. To this end, we propose, TC-GNN, the first GPU Tensor Core Unit (TCU) based GNN acceleration framework. The core idea is to reconcile the "Sparse" GNN computation with "Dense" TCU. Specifically, we conduct an in-depth analysis of the sparse operations in mainstream GNN computing frameworks. We introduce a novel sparse graph translation technique to facilitate TCU processing of sparse GNN workload. We also implement an effective CUDA core and TCU collaboration design to fully utilize GPU resources. We fully integrate TC-GNN with the Pytorch framework for ease of programming. Rigorous experiments show an average of 1.70X speedup over the state-of-the-art Deep Graph Library framework across various GNN models and dataset settings.
Towards Efficient Ansatz Architecture for Variational Quantum Algorithms
Nov 26, 2021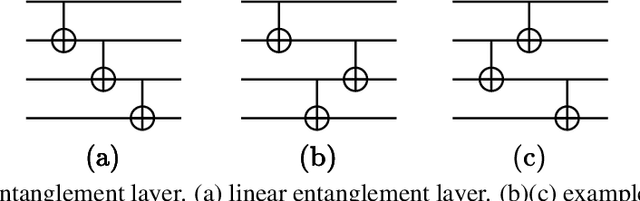
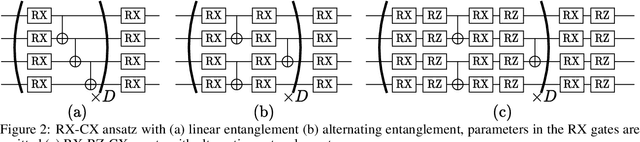
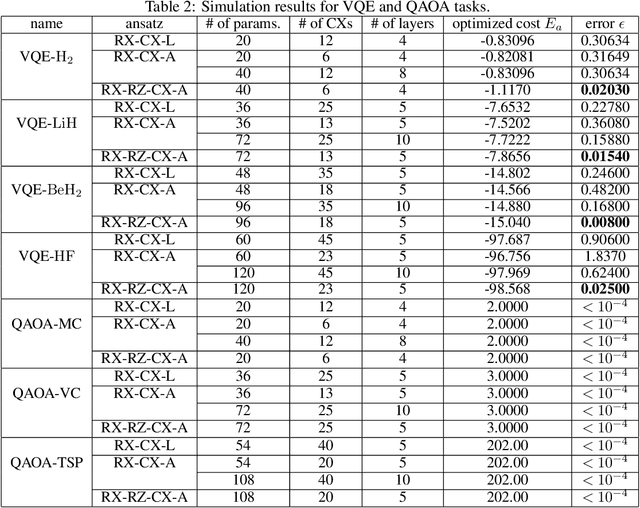
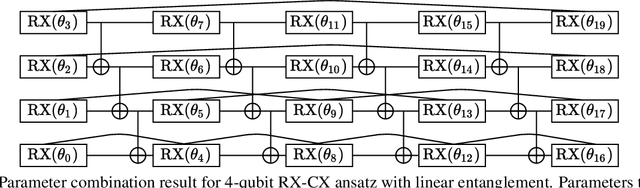
Variational quantum algorithms are expected to demonstrate the advantage of quantum computing on near-term noisy quantum computers. However, training such variational quantum algorithms suffers from gradient vanishing as the size of the algorithm increases. Previous work cannot handle the gradient vanishing induced by the inevitable noise effects on realistic quantum hardware. In this paper, we propose a novel training scheme to mitigate such noise-induced gradient vanishing. We first introduce a new cost function of which the gradients are significantly augmented by employing traceless observables in truncated subspace. We then prove that the same minimum can be reached by optimizing the original cost function with the gradients from the new cost function. Experiments show that our new training scheme is highly effective for major variational quantum algorithms of various tasks.
APNN-TC: Accelerating Arbitrary Precision Neural Networks on Ampere GPU Tensor Cores
Jun 23, 2021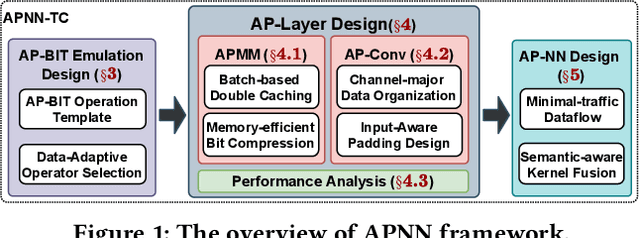

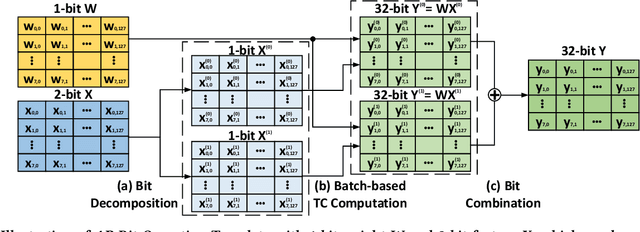

Over the years, accelerating neural networks with quantization has been widely studied. Unfortunately, prior efforts with diverse precisions (e.g., 1-bit weights and 2-bit activations) are usually restricted by limited precision support on GPUs (e.g., int1 and int4). To break such restrictions, we introduce the first Arbitrary Precision Neural Network framework (APNN-TC) to fully exploit quantization benefits on Ampere GPU Tensor Cores. Specifically, APNN-TC first incorporates a novel emulation algorithm to support arbitrary short bit-width computation with int1 compute primitives and XOR/AND Boolean operations. Second, APNN-TC integrates arbitrary precision layer designs to efficiently map our emulation algorithm to Tensor Cores with novel batching strategies and specialized memory organization. Third, APNN-TC embodies a novel arbitrary precision NN design to minimize memory access across layers and further improve performance. Extensive evaluations show that APNN-TC can achieve significant speedup over CUTLASS kernels and various NN models, such as ResNet and VGG.