 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Landscape of Modern Machine Learning: A Review of Machine, Distributed and Federated Learning
Dec 05, 2023



With the advance of the powerful heterogeneous, parallel and distributed computing systems and ever increasing immense amount of data, machine learning has become an indispensable part of cutting-edge technology, scientific research and consumer products. In this study, we present a review of modern machine and deep learning. We provide a high-level overview for the latest advanced machine learning algorithms, applications, and frameworks. Our discussion encompasses parallel distributed learning, deep learning as well as federated learning. As a result, our work serves as an introductory text to the vast field of modern machine learning.
Evaluating Emerging AI/ML Accelerators: IPU, RDU, and NVIDIA/AMD GPUs
Nov 08, 2023The relentless advancement of artificial intelligence (AI) and machine learning (ML) applications necessitates the development of specialized hardware accelerators capable of handling the increasing complexity and computational demands. Traditional computing architectures, based on the von Neumann model, are being outstripped by the requirements of contemporary AI/ML algorithms, leading to a surge in the creation of accelerators like the Graphcore Intelligence Processing Unit (IPU), Sambanova Reconfigurable Dataflow Unit (RDU), and enhanced GPU platforms. These hardware accelerators are characterized by their innovative data-flow architectures and other design optimizations that promise to deliver superior performance and energy efficiency for AI/ML tasks. This research provides a preliminary evaluation and comparison of these commercial AI/ML accelerators, delving into their hardware and software design features to discern their strengths and unique capabilities. By conducting a series of benchmark evaluations on common DNN operators and other AI/ML workloads, we aim to illuminate the advantages of data-flow architectures over conventional processor designs and offer insights into the performance trade-offs of each platform. The findings from our study will serve as a valuable reference for the design and performance expectations of research prototypes, thereby facilitating the development of next-generation hardware accelerators tailored for the ever-evolving landscape of AI/ML applications. Through this analysis, we aspire to contribute to the broader understanding of current accelerator technologies and to provide guidance for future innovations in the field.
Empowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Sep 14, 2022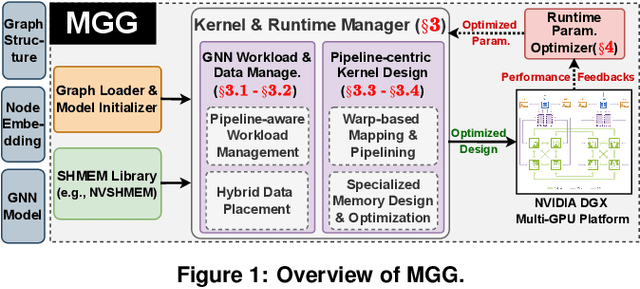

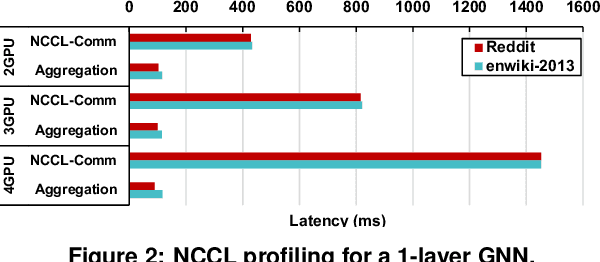

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.