 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering GNNs with Fine-grained Communication-Computation Pipelining on Multi-GPU Platforms
Paper and Code
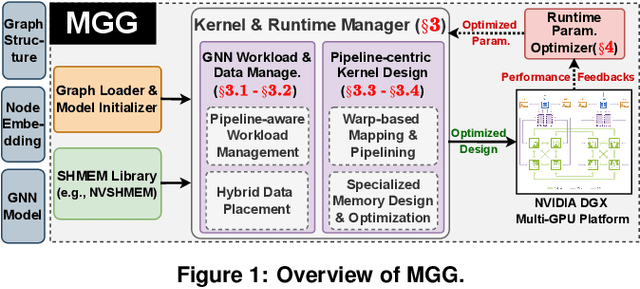

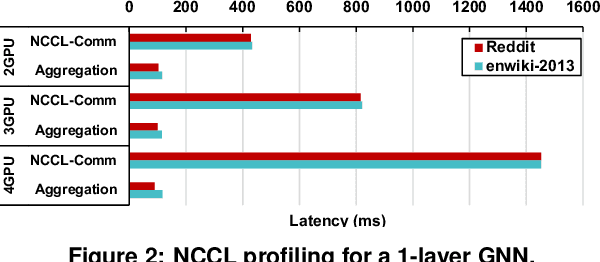

The increasing size of input graphs for graph neural networks (GNNs) highlights the demand for using multi-GPU platforms. However, existing multi-GPU GNN solutions suffer from inferior performance due to imbalanced computation and inefficient communication. To this end, we propose MGG, a novel system design to accelerate GNNs on multi-GPU platforms via a GPU-centric software pipeline. MGG explores the potential of hiding remote memory access latency in GNN workloads through fine-grained computation-communication pipelining. Specifically, MGG introduces a pipeline-aware workload management strategy and a hybrid data layout design to facilitate communication-computation overlapping. MGG implements an optimized pipeline-centric kernel. It includes workload interleaving and warp-based mapping for efficient GPU kernel operation pipelining and specialized memory designs and optimizations for better data access performance. Besides, MGG incorporates lightweight analytical modeling and optimization heuristics to dynamically improve the GNN execution performance for different settings at runtime. Comprehensive experiments demonstrate that MGG outperforms state-of-the-art multi-GPU systems across various GNN settings: on average 3.65X faster than multi-GPU systems with a unified virtual memory design and on average 7.38X faster than the DGCL framework.