 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Reward Steering: An Adaptive Inference-Time Framework that Implicitly Promotes Cognitive Behaviors in Reasoning LLMs
May 30, 2026Strong reasoning depends not only on model knowledge but also on how effectively cognitive behaviors are deployed during generation. Existing methods often rely on explicit behavior-level control, making them insufficiently adaptive when failures and required corrections vary across reasoning states, tasks, and models. To this end, we propose Latent Reward Steering (LRS), an adaptive inference-time framework that promotes cognitive behaviors by optimizing the sparse-autoencoder (SAE) latent states that implicitly carry them. Rather than relying on predefined cognitive behaviors or steering directions derived from them, LRS trains a latent reward model on reasoning traces by final answer correctness to estimate the quality of intermediate latent states. During inference, reward gradients provide state-specific correction directions for fragile latent states, while a reward and confidence gate restricts intervention to states the reward signal flags as fragile. Experiments on multiple reasoning LLM backbones and benchmarks show that \ours consistently improves performance over various baselines, and post-hoc analyses further indicate that \ours implicitly promotes good cognitive behaviors that fix the original reasoning errors. Code is available at: https://github.com/jiakanglee/Latent-Reward-Steering.
Complete-muE: Optimal Hyperparameter Transfer and Scaling for MoE Models
May 22, 2026We propose Complete-muE, a framework which targets hyperparameter transfer across dense FFN and any Mixture-of-Experts (MoE) setups in transformer blocks. Existing tools such as $μ$P (requires fixed architectue) or SDE (requires fixed per-step token count) cannot directly solve the hyperparameter transfer problem in MoE setups because Dense to MoE transfer or MoE total experts scaling changes both architecture and tokens per expert. Complete-muE solves this challenge with a two-bridge system: Bridge~I maps between dense FFN and Dense MoE by active-width $μ$P with a normalized router scale. Bridge~II maps between Dense MoE and sparse MoE by activated-expert scaling, where the first-order SDE LR/WD correction cancels while a bounded residual $σ_0$ shift remains. The resulting transfer rule, which we term as Complete muE, covers changes in activated experts, total capacity, granularity, and shared/group-balanced hybrids for MoE models as well as network width/depth, batch size, and duration changes for general Transformer models. Extensive language model and diffusion model pretraining experiments confirm that complete-muE yields relatively stable hyperparameter optima across model architectures and parameter counts -- with only minor drift consistent with the non-strict SDE behavior of Bridge~II. In practice this drift is small enough that hyperparameters tuned on a single dense reference transfer near-optimally to all MoE configurations -- \emph{tune dense once, transfer to all} is the practical recipe at the core of Complete-muE. This enables MoE models to achieve accelerated convergence speedup over dense models when scaling model capacity without costly hyperparameter search.
Multi-Head Low-Rank Attention
Mar 02, 2026Long-context inference in large language models is bottlenecked by Key--Value (KV) cache loading during the decoding stage, where the sequential nature of generation requires repeatedly transferring the KV cache from off-chip High-Bandwidth Memory (HBM) to on-chip Static Random-Access Memory (SRAM) at each step. While Multi-Head Latent Attention (MLA) significantly reduces the total KV cache size, it suffers from a sharding bottleneck during distributed decoding via Tensor Parallelism (TP). Since its single latent head cannot be partitioned, each device is forced to redundantly load the complete KV cache for every token, consuming excessive memory traffic and diminishing TP benefits like weight sharding. In this work, we propose Multi-Head Low-Rank Attention (MLRA), which enables partitionable latent states for efficient 4-way TP decoding. Extensive experiments show that MLRA achieves state-of-the-art perplexity and downstream task performance, while also delivering a 2.8$\times$ decoding speedup over MLA. Code is available at https://github.com/SongtaoLiu0823/MLRA. Pretrained weights, along with the training and evaluation data, are available at https://huggingface.co/Soughing/MLRA.
Reasoning over Precedents Alongside Statutes: Case-Augmented Deliberative Alignment for LLM Safety
Jan 12, 2026Ensuring that Large Language Models (LLMs) adhere to safety principles without refusing benign requests remains a significant challenge. While OpenAI introduces deliberative alignment (DA) to enhance the safety of its o-series models through reasoning over detailed ``code-like'' safety rules, the effectiveness of this approach in open-source LLMs, which typically lack advanced reasoning capabilities, is understudied. In this work, we systematically evaluate the impact of explicitly specifying extensive safety codes versus demonstrating them through illustrative cases. We find that referencing explicit codes inconsistently improves harmlessness and systematically degrades helpfulness, whereas training on case-augmented simple codes yields more robust and generalized safety behaviors. By guiding LLMs with case-augmented reasoning instead of extensive code-like safety rules, we avoid rigid adherence to narrowly enumerated rules and enable broader adaptability. Building on these insights, we propose CADA, a case-augmented deliberative alignment method for LLMs utilizing reinforcement learning on self-generated safety reasoning chains. CADA effectively enhances harmlessness, improves robustness against attacks, and reduces over-refusal while preserving utility across diverse benchmarks, offering a practical alternative to rule-only DA for improving safety while maintaining helpfulness.
Sparsity-Controllable Dynamic Top-p MoE for Large Foundation Model Pre-training
Dec 16, 2025Sparse Mixture-of-Experts (MoE) architectures effectively scale model capacity by activating only a subset of experts for each input token. However, the standard Top-k routing strategy imposes a uniform sparsity pattern that ignores the varying difficulty of tokens. While Top-p routing offers a flexible alternative, existing implementations typically rely on a fixed global probability threshold, which results in uncontrolled computational costs and sensitivity to hyperparameter selection. In this paper, we propose DTop-p MoE, a sparsity-controllable dynamic Top-p routing mechanism. To resolve the challenge of optimizing a non-differentiable threshold, we utilize a Proportional-Integral (PI) Controller that dynamically adjusts the probability threshold to align the running activated-expert sparsity with a specified target. Furthermore, we introduce a dynamic routing normalization mechanism that adapts layer-wise routing logits, allowing different layers to learn distinct expert-selection patterns while utilizing a global probability threshold. Extensive experiments on Large Language Models and Diffusion Transformers demonstrate that DTop-p consistently outperforms both Top-k and fixed-threshold Top-p baselines. Our analysis confirms that DTop-p maintains precise control over the number of activated experts while adaptively allocating resources across different tokens and layers. Furthermore, DTop-p exhibits strong scaling properties with respect to expert granularity, expert capacity, model size, and dataset size, offering a robust framework for large-scale MoE pre-training.
Your Reward Function for RL is Your Best PRM for Search: Unifying RL and Search-Based TTS
Aug 19, 2025Test-time scaling (TTS) for large language models (LLMs) has thus far fallen into two largely separate paradigms: (1) reinforcement learning (RL) methods that optimize sparse outcome-based rewards, yet suffer from instability and low sample efficiency; and (2) search-based techniques guided by independently trained, static process reward models (PRMs), which require expensive human- or LLM-generated labels and often degrade under distribution shifts. In this paper, we introduce AIRL-S, the first natural unification of RL-based and search-based TTS. Central to AIRL-S is the insight that the reward function learned during RL training inherently represents the ideal PRM for guiding downstream search. Specifically, we leverage adversarial inverse reinforcement learning (AIRL) combined with group relative policy optimization (GRPO) to learn a dense, dynamic PRM directly from correct reasoning traces, entirely eliminating the need for labeled intermediate process data. At inference, the resulting PRM simultaneously serves as the critic for RL rollouts and as a heuristic to effectively guide search procedures, facilitating robust reasoning chain extension, mitigating reward hacking, and enhancing cross-task generalization. Experimental results across eight benchmarks, including mathematics, scientific reasoning, and code generation, demonstrate that our unified approach improves performance by 9 % on average over the base model, matching GPT-4o. Furthermore, when integrated into multiple search algorithms, our PRM consistently outperforms all baseline PRMs trained with labeled data. These results underscore that, indeed, your reward function for RL is your best PRM for search, providing a robust and cost-effective solution to complex reasoning tasks in LLMs.
Two Heads are Better Than One: Test-time Scaling of Multi-agent Collaborative Reasoning
Apr 14, 2025Multi-agent systems (MAS) built on large language models (LLMs) offer a promising path toward solving complex, real-world tasks that single-agent systems often struggle to manage. While recent advancements in test-time scaling (TTS) have significantly improved single-agent performance on challenging reasoning tasks, how to effectively scale collaboration and reasoning in MAS remains an open question. In this work, we introduce an adaptive multi-agent framework designed to enhance collaborative reasoning through both model-level training and system-level coordination. We construct M500, a high-quality dataset containing 500 multi-agent collaborative reasoning traces, and fine-tune Qwen2.5-32B-Instruct on this dataset to produce M1-32B, a model optimized for multi-agent collaboration. To further enable adaptive reasoning, we propose a novel CEO agent that dynamically manages the discussion process, guiding agent collaboration and adjusting reasoning depth for more effective problem-solving. Evaluated in an open-source MAS across a range of tasks-including general understanding, mathematical reasoning, and coding-our system significantly outperforms strong baselines. For instance, M1-32B achieves 12% improvement on GPQA-Diamond, 41% on AIME2024, and 10% on MBPP-Sanitized, matching the performance of state-of-the-art models like DeepSeek-R1 on some tasks. These results highlight the importance of both learned collaboration and adaptive coordination in scaling multi-agent reasoning. Code is available at https://github.com/jincan333/MAS-TTS
RankFlow: A Multi-Role Collaborative Reranking Workflow Utilizing Large Language Models
Feb 04, 2025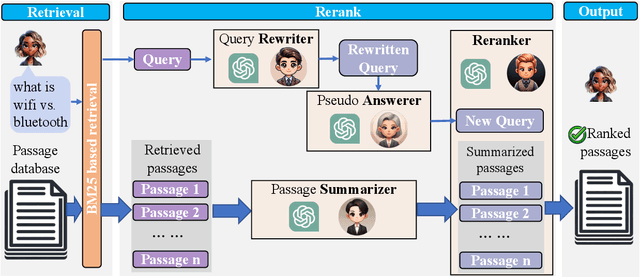
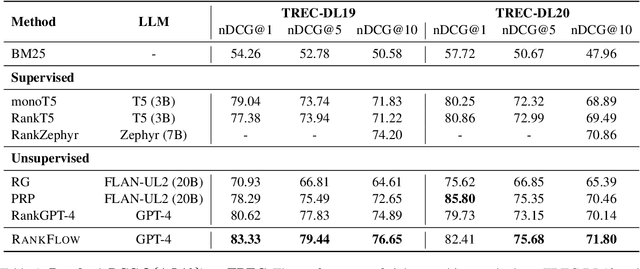
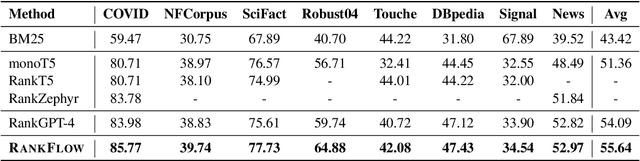
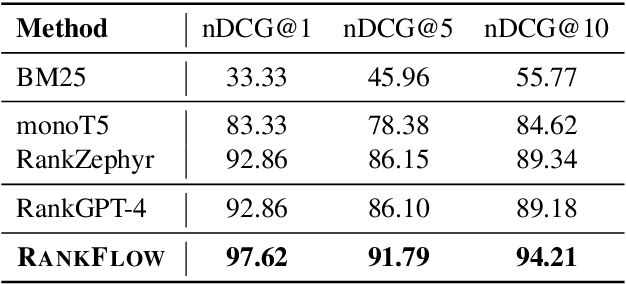
In an Information Retrieval (IR) system, reranking plays a critical role by sorting candidate passages according to their relevance to a specific query. This process demands a nuanced understanding of the variations among passages linked to the query. In this work, we introduce RankFlow, a multi-role reranking workflow that leverages the capabilities of Large Language Models (LLMs) and role specializations to improve reranking performance. RankFlow enlists LLMs to fulfill four distinct roles: the query Rewriter, the pseudo Answerer, the passage Summarizer, and the Reranker. This orchestrated approach enables RankFlow to: (1) accurately interpret queries, (2) draw upon LLMs' extensive pre-existing knowledge, (3) distill passages into concise versions, and (4) assess passages in a comprehensive manner, resulting in notably better reranking results. Our experimental results reveal that RankFlow outperforms existing leading approaches on widely recognized IR benchmarks, such as TREC-DL, BEIR, and NovelEval. Additionally, we investigate the individual contributions of each role in RankFlow. Code is available at https://github.com/jincan333/RankFlow.
APEER: Automatic Prompt Engineering Enhances Large Language Model Reranking
Jun 20, 2024Large Language Models (LLMs) have significantly enhanced Information Retrieval (IR) across various modules, such as reranking. Despite impressive performance, current zero-shot relevance ranking with LLMs heavily relies on human prompt engineering. Existing automatic prompt engineering algorithms primarily focus on language modeling and classification tasks, leaving the domain of IR, particularly reranking, underexplored. Directly applying current prompt engineering algorithms to relevance ranking is challenging due to the integration of query and long passage pairs in the input, where the ranking complexity surpasses classification tasks. To reduce human effort and unlock the potential of prompt optimization in reranking, we introduce a novel automatic prompt engineering algorithm named APEER. APEER iteratively generates refined prompts through feedback and preference optimization. Extensive experiments with four LLMs and ten datasets demonstrate the substantial performance improvement of APEER over existing state-of-the-art (SoTA) manual prompts. Furthermore, we find that the prompts generated by APEER exhibit better transferability across diverse tasks and LLMs. Code is available at https://github.com/jincan333/APEER.
SSNet: A Lightweight Multi-Party Computation Scheme for Practical Privacy-Preserving Machine Learning Service in the Cloud
Jun 04, 2024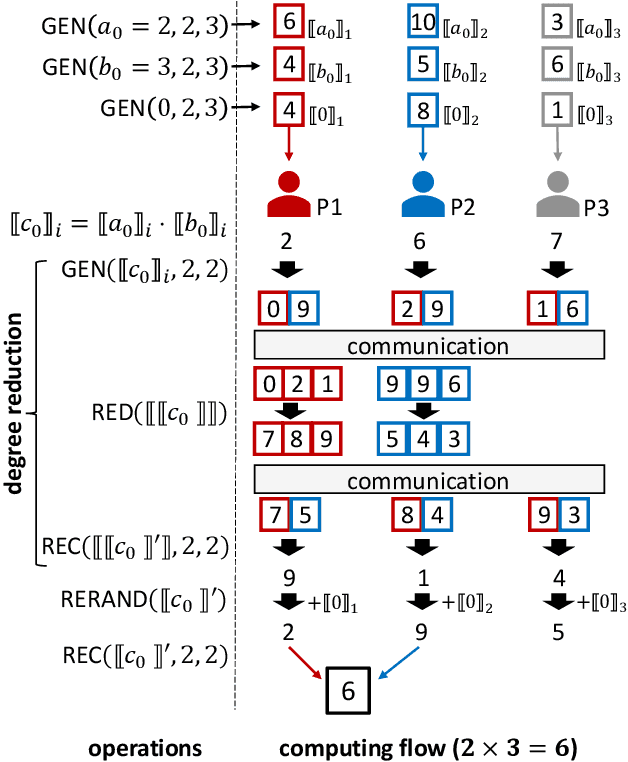
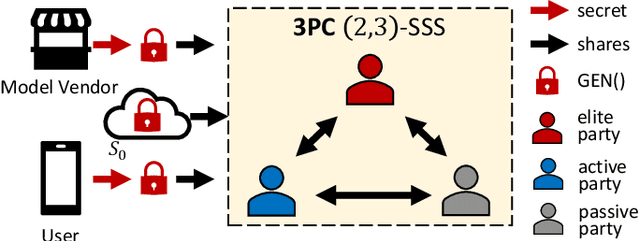
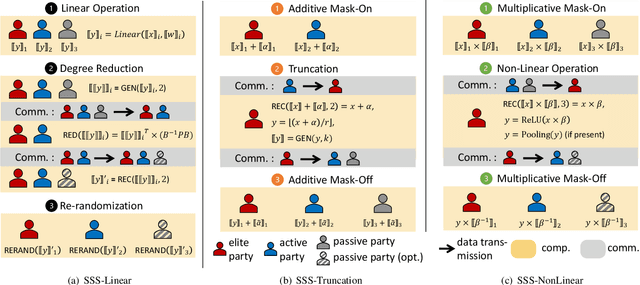
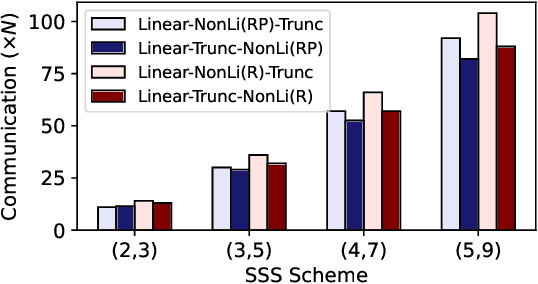
As privacy-preserving becomes a pivotal aspect of deep learning (DL) development, multi-party computation (MPC) has gained prominence for its efficiency and strong security. However, the practice of current MPC frameworks is limited, especially when dealing with large neural networks, exemplified by the prolonged execution time of 25.8 seconds for secure inference on ResNet-152. The primary challenge lies in the reliance of current MPC approaches on additive secret sharing, which incurs significant communication overhead with non-linear operations such as comparisons. Furthermore, additive sharing suffers from poor scalability on party size. In contrast, the evolving landscape of MPC necessitates accommodating a larger number of compute parties and ensuring robust performance against malicious activities or computational failures. In light of these challenges, we propose SSNet, which for the first time, employs Shamir's secret sharing (SSS) as the backbone of MPC-based ML framework. We meticulously develop all framework primitives and operations for secure DL models tailored to seamlessly integrate with the SSS scheme. SSNet demonstrates the ability to scale up party numbers straightforwardly and embeds strategies to authenticate the computation correctness without incurring significant performance overhead. Additionally, SSNet introduces masking strategies designed to reduce communication overhead associated with non-linear operations. We conduct comprehensive experimental evaluations on commercial cloud computing infrastructure from Amazon AWS, as well as across diverse prevalent DNN models and datasets. SSNet demonstrates a substantial performance boost, achieving speed-ups ranging from 3x to 14x compared to SOTA MPC frameworks. Moreover, SSNet also represents the first framework that is evaluated on a five-party computation setup, in the context of secure DL inference.