 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAQR-HNSW: Accelerating Approximate Nearest Neighbor Search via Density-aware Quantization and Multi-stage Re-ranking
Feb 25, 2026Approximate Nearest Neighbor (ANN) search has become fundamental to modern AI infrastructure, powering recommendation systems, search engines, and large language models across industry leaders from Google to OpenAI. Hierarchical Navigable Small World (HNSW) graphs have emerged as the dominant ANN algorithm, widely adopted in production systems due to their superior recall versus latency balance. However, as vector databases scale to billions of embeddings, HNSW faces critical bottlenecks: memory consumption expands, distance computation overhead dominates query latency, and it suffers suboptimal performance on heterogeneous data distributions. This paper presents Adaptive Quantization and Rerank HNSW (AQR-HNSW), a novel framework that synergistically integrates three strategies to enhance HNSW scalability. AQR-HNSW introduces (1) density-aware adaptive quantization, achieving 4x compression while preserving distance relationships; (2) multi-state re-ranking that reduces unnecessary computations by 35%; and (3) quantization-optimized SIMD implementations delivering 16-64 operations per cycle across architectures. Evaluation on standard benchmarks demonstrates 2.5-3.3x higher queries per second (QPS) than state-of-the-art HNSW implementations while maintaining over 98% recall, with 75% memory reduction for the index graph and 5x faster index construction.
Toward Large-Scale Photonics-Empowered AI Systems: From Physical Design Automation to System-Algorithm Co-Exploration
Dec 31, 2025In this work, we identify three considerations that are essential for realizing practical photonic AI systems at scale: (1) dynamic tensor operation support for modern models rather than only weight-static kernels, especially for attention/Transformer-style workloads; (2) systematic management of conversion, control, and data-movement overheads, where multiplexing and dataflow must amortize electronic costs instead of letting ADC/DAC and I/O dominate; and (3) robustness under hardware non-idealities that become more severe as integration density grows. To study these coupled tradeoffs quantitatively, and to ensure they remain meaningful under real implementation constraints, we build a cross-layer toolchain that supports photonic AI design from early exploration to physical realization. SimPhony provides implementation-aware modeling and rapid cross-layer evaluation, translating physical costs into system-level metrics so architectural decisions are grounded in realistic assumptions. ADEPT and ADEPT-Z enable end-to-end circuit and topology exploration, connecting system objectives to feasible photonic fabrics under practical device and circuit constraints. Finally, Apollo and LiDAR provide scalable photonic physical design automation, turning candidate circuits into manufacturable layouts while accounting for routing, thermal, and crosstalk constraints.
Generalist Foundation Models Are Not Clinical Enough for Hospital Operations
Nov 17, 2025Hospitals and healthcare systems rely on operational decisions that determine patient flow, cost, and quality of care. Despite strong performance on medical knowledge and conversational benchmarks, foundation models trained on general text may lack the specialized knowledge required for these operational decisions. We introduce Lang1, a family of models (100M-7B parameters) pretrained on a specialized corpus blending 80B clinical tokens from NYU Langone Health's EHRs and 627B tokens from the internet. To rigorously evaluate Lang1 in real-world settings, we developed the REalistic Medical Evaluation (ReMedE), a benchmark derived from 668,331 EHR notes that evaluates five critical tasks: 30-day readmission prediction, 30-day mortality prediction, length of stay, comorbidity coding, and predicting insurance claims denial. In zero-shot settings, both general-purpose and specialized models underperform on four of five tasks (36.6%-71.7% AUROC), with mortality prediction being an exception. After finetuning, Lang1-1B outperforms finetuned generalist models up to 70x larger and zero-shot models up to 671x larger, improving AUROC by 3.64%-6.75% and 1.66%-23.66% respectively. We also observed cross-task scaling with joint finetuning on multiple tasks leading to improvement on other tasks. Lang1-1B effectively transfers to out-of-distribution settings, including other clinical tasks and an external health system. Our findings suggest that predictive capabilities for hospital operations require explicit supervised finetuning, and that this finetuning process is made more efficient by in-domain pretraining on EHR. Our findings support the emerging view that specialized LLMs can compete with generalist models in specialized tasks, and show that effective healthcare systems AI requires the combination of in-domain pretraining, supervised finetuning, and real-world evaluation beyond proxy benchmarks.
Repurposing the scientific literature with vision-language models
Feb 26, 2025Research in AI for Science often focuses on using AI technologies to augment components of the scientific process, or in some cases, the entire scientific method; how about AI for scientific publications? Peer-reviewed journals are foundational repositories of specialized knowledge, written in discipline-specific language that differs from general Internet content used to train most large language models (LLMs) and vision-language models (VLMs). We hypothesized that by combining a family of scientific journals with generative AI models, we could invent novel tools for scientific communication, education, and clinical care. We converted 23,000 articles from Neurosurgery Publications into a multimodal database - NeuroPubs - of 134 million words and 78,000 image-caption pairs to develop six datasets for building AI models. We showed that the content of NeuroPubs uniquely represents neurosurgery-specific clinical contexts compared with broader datasets and PubMed. For publishing, we employed generalist VLMs to automatically generate graphical abstracts from articles. Editorial board members rated 70% of these as ready for publication without further edits. For education, we generated 89,587 test questions in the style of the ABNS written board exam, which trainee and faculty neurosurgeons found indistinguishable from genuine examples 54% of the time. We used these questions alongside a curriculum learning process to track knowledge acquisition while training our 34 billion-parameter VLM (CNS-Obsidian). In a blinded, randomized controlled trial, we demonstrated the non-inferiority of CNS-Obsidian to GPT-4o (p = 0.1154) as a diagnostic copilot for a neurosurgical service. Our findings lay a novel foundation for AI with Science and establish a framework to elevate scientific communication using state-of-the-art generative artificial intelligence while maintaining rigorous quality standards.
SimPhony: A Device-Circuit-Architecture Cross-Layer Modeling and Simulation Framework for Heterogeneous Electronic-Photonic AI System
Nov 20, 2024



Electronic-photonic integrated circuits (EPICs) offer transformative potential for next-generation high-performance AI but require interdisciplinary advances across devices, circuits, architecture, and design automation. The complexity of hybrid systems makes it challenging even for domain experts to understand distinct behaviors and interactions across design stack. The lack of a flexible, accurate, fast, and easy-to-use EPIC AI system simulation framework significantly limits the exploration of hardware innovations and system evaluations on common benchmarks. To address this gap, we propose SimPhony, a cross-layer modeling and simulation framework for heterogeneous electronic-photonic AI systems. SimPhony offers a platform that enables (1) generic, extensible hardware topology representation that supports heterogeneous multi-core architectures with diverse photonic tensor core designs; (2) optics-specific dataflow modeling with unique multi-dimensional parallelism and reuse beyond spatial/temporal dimensions; (3) data-aware energy modeling with realistic device responses, layout-aware area estimation, link budget analysis, and bandwidth-adaptive memory modeling; and (4) seamless integration with model training framework for hardware/software co-simulation. By providing a unified, versatile, and high-fidelity simulation platform, SimPhony enables researchers to innovate and evaluate EPIC AI hardware across multiple domains, facilitating the next leap in emerging AI hardware. We open-source our codes at https://github.com/ScopeX-ASU/SimPhony
Multi-Dimensional Reconfigurable, Physically Composable Hybrid Diffractive Optical Neural Network
Nov 08, 2024



Diffractive optical neural networks (DONNs), leveraging free-space light wave propagation for ultra-parallel, high-efficiency computing, have emerged as promising artificial intelligence (AI) accelerators. However, their inherent lack of reconfigurability due to fixed optical structures post-fabrication hinders practical deployment in the face of dynamic AI workloads and evolving applications. To overcome this challenge, we introduce, for the first time, a multi-dimensional reconfigurable hybrid diffractive ONN system (MDR-HDONN), a physically composable architecture that unlocks a new degree of freedom and unprecedented versatility in DONNs. By leveraging full-system learnability, MDR-HDONN repurposes fixed fabricated optical hardware, achieving exponentially expanded functionality and superior task adaptability through the differentiable learning of system variables. Furthermore, MDR-HDONN adopts a hybrid optical/photonic design, combining the reconfigurability of integrated photonics with the ultra-parallelism of free-space diffractive systems. Extensive evaluations demonstrate that MDR-HDONN has digital-comparable accuracy on various task adaptations with 74x faster speed and 194x lower energy. Compared to prior DONNs, MDR-HDONN shows exponentially larger functional space with 5x faster training speed, paving the way for a new paradigm of versatile, composable, hybrid optical/photonic AI computing. We will open-source our codes.
SCATTER: Algorithm-Circuit Co-Sparse Photonic Accelerator with Thermal-Tolerant, Power-Efficient In-situ Light Redistribution
Jul 07, 2024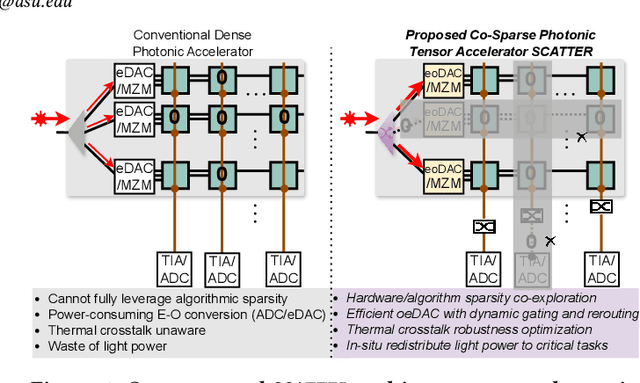
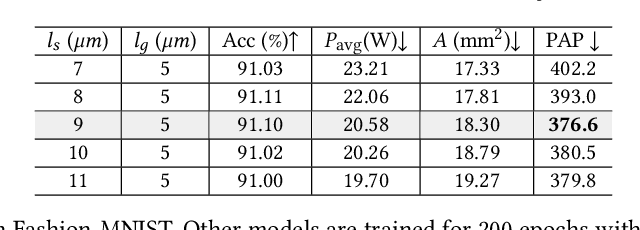
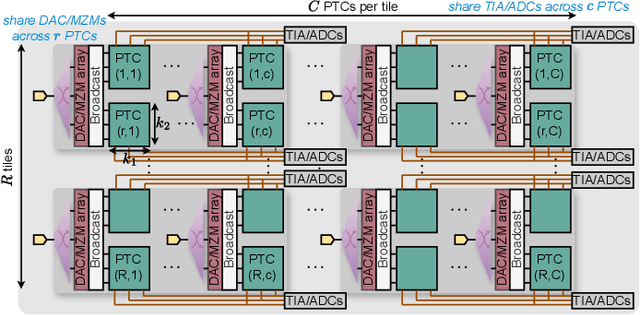
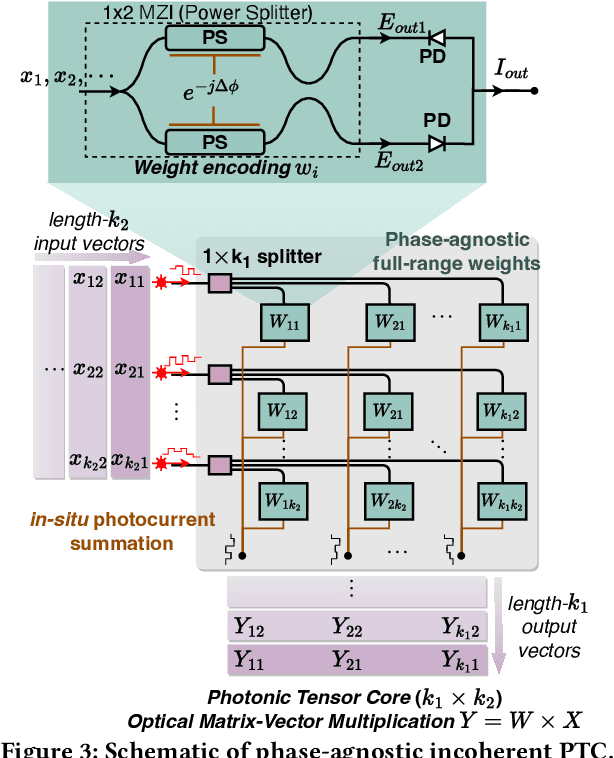
Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads. However, limited reconfigurability, high electrical-optical conversion cost, and thermal sensitivity limit the deployment of current optical analog computing engines to support power-restricted, performance-sensitive AI workloads at scale. Sparsity provides a great opportunity for hardware-efficient AI accelerators. However, current dense photonic accelerators fail to fully exploit the power-saving potential of algorithmic sparsity. It requires sparsity-aware hardware specialization with a fundamental re-design of photonic tensor core topology and cross-layer device-circuit-architecture-algorithm co-optimization aware of hardware non-ideality and power bottleneck. To trim down the redundant power consumption while maximizing robustness to thermal variations, we propose SCATTER, a novel algorithm-circuit co-sparse photonic accelerator featuring dynamically reconfigurable signal path via thermal-tolerant, power-efficient in-situ light redistribution and power gating. A power-optimized, crosstalk-aware dynamic sparse training framework is introduced to explore row-column structured sparsity and ensure marginal accuracy loss and maximum power efficiency. The extensive evaluation shows that our cross-stacked optimized accelerator SCATTER achieves a 511X area reduction and 12.4X power saving with superior crosstalk tolerance that enables unprecedented circuit layout compactness and on-chip power efficiency.
Skip-SCAR: A Modular Approach to ObjectGoal Navigation with Sparsity and Adaptive Skips
May 23, 2024



In ObjectGoal navigation (ObjectNav), agents must locate specific objects within unseen environments, requiring effective observation, prediction, and navigation capabilities. This study found that traditional methods looking only for prediction accuracy often compromise on computational efficiency. To address this, we introduce "Skip-SCAR," a modular framework that enhances efficiency by leveraging sparsity and adaptive skips. The SparseConv-Augmented ResNet (SCAR) at the core of our approach uses sparse and dense feature processing in parallel, optimizing both the computation and memory footprint. Our adaptive skip technique further reduces computational demands by selectively bypassing unnecessary semantic segmentation steps based on environmental constancy. Tested on the HM3D ObjectNav datasets, Skip-SCAR not only minimizes resource use but also sets new performance benchmarks, demonstrating a robust method for improving efficiency and accuracy in robotic navigation tasks.
Advanced Language Model-Driven Verilog Development: Enhancing Power, Performance, and Area Optimization in Code Synthesis
Dec 02, 2023The increasing use of Advanced Language Models (ALMs) in diverse sectors, particularly due to their impressive capability to generate top-tier content following linguistic instructions, forms the core of this investigation. This study probes into ALMs' deployment in electronic hardware design, with a specific emphasis on the synthesis and enhancement of Verilog programming. We introduce an innovative framework, crafted to assess and amplify ALMs' productivity in this niche. The methodology commences with the initial crafting of Verilog programming via ALMs, succeeded by a distinct dual-stage refinement protocol. The premier stage prioritizes augmenting the code's operational and linguistic precision, while the latter stage is dedicated to aligning the code with Power-Performance-Area (PPA) benchmarks, a pivotal component in proficient hardware design. This bifurcated strategy, merging error remediation with PPA enhancement, has yielded substantial upgrades in the caliber of ALM-created Verilog programming. Our framework achieves an 81.37% rate in linguistic accuracy and 62.0% in operational efficacy in programming synthesis, surpassing current leading-edge techniques, such as 73% in linguistic accuracy and 46% in operational efficacy. These findings illuminate ALMs' aptitude in tackling complex technical domains and signal a positive shift in the mechanization of hardware design operations.
Path Planning Under Uncertainty to Localize mmWave Sources
Mar 08, 2023
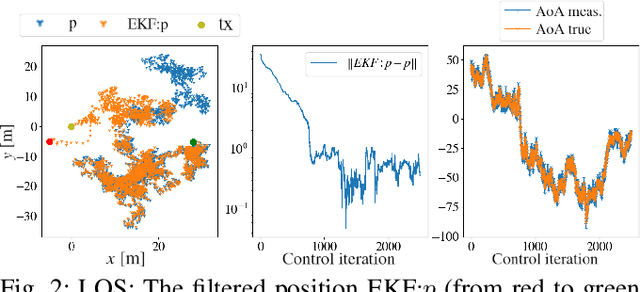

In this paper, we study a navigation problem where a mobile robot needs to locate a mmWave wireless signal. Using the directionality properties of the signal, we propose an estimation and path planning algorithm that can efficiently navigate in cluttered indoor environments. We formulate Extended Kalman filters for emitter location estimation in cases where the signal is received in line-of-sight or after reflections. We then propose to plan motion trajectories based on belief-space dynamics in order to minimize the uncertainty of the position estimates. The associated non-linear optimization problem is solved by a state-of-the-art constrained iLQR solver. In particular, we propose a method that can handle a large number of obstacles (~300) with reasonable computation times. We validate the approach in an extensive set of simulations. We show that our estimators can help increase navigation success rate and that planning to reduce estimation uncertainty can improve the overall task completion speed.