 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Photonics for Machine Intelligence
Apr 12, 2026The exponential growth of machine-intelligence workloads is colliding with the power, memory, and interconnect limits of the post-Moore era, motivating compute substrates that scale beyond transistor density alone. Integrated photonics is emerging as a candidate for artificial intelligence (AI) acceleration by exploiting optical bandwidth and parallelism to reshape data movement and computation. This review reframes photonic computing from a circuits-and-systems perspective, moving beyond building-block progress toward cross-layer system analysis and full-stack design automation. We synthesize recent advances through a bottleneck-driven taxonomy that delineates the operating regimes and scaling trends where photonics can deliver end-to-end sustained benefits. A central theme is cross-layer co-design and workload-adaptive programmability to sustain high efficiency and versatility across evolving application domains at scale. We further argue that Electronic-Photonic Design Automation (EPDA) will be pivotal, enabling closed-loop co-optimization across simulation, inverse design, system modeling, and physical implementation. By charting a roadmap from laboratory prototypes to scalable, reproducible electronic-photonic ecosystems, this review aims to guide the CAS community toward an automated, system-centric era of photonic machine intelligence.
ReDON: Recurrent Diffractive Optical Neural Processor with Reconfigurable Self-Modulated Nonlinearity
Mar 02, 2026Diffractive optical neural networks (DONNs) have demonstrated unparalleled energy efficiency and parallelism by processing information directly in the optical domain. However, their computational expressivity is constrained by static, passive diffractive phase masks that lack efficient nonlinear responses and reprogrammability. To address these limitations, we introduce the Recurrent Diffractive Optical Neural Processor (ReDON), a novel architecture featuring reconfigurable, recurrent self-modulated nonlinearity. This mechanism enables dynamic, input-dependent optical transmission through in-situ electro-optic self-modulation, providing a highly efficient and reprogrammable approach to optical computation. Inspired by the gated linear unit (GLU) used in large language models, ReDON senses a fraction of the propagating optical field and modulates its phase or intensity via a lightweight parametric function, enabling effective nonlinearity with minimal inference overhead. As a non-von Neumann architecture in which the primary weighting elements (metasurfaces) remain fixed, ReDON substantially extends the nonlinear representational capacity and task adaptability of conventional DONNs through recurrent optical hardware reuse and dynamically tunable nonlinearity. We systematically investigate various self-modulation configurations to characterize the trade-offs between hardware efficiency and computational expressivity. On image recognition and segmentation benchmarks, ReDON improves test accuracy and mean intersection-over-union (mIoU) by up to 20% compared with prior DONNs employing either optical or digital nonlinearities at comparable model complexity and negligible additional power consumption. This work establishes a new paradigm for reconfigurable nonlinear optical computing, uniting recurrence and self-modulation within non-von Neumann analog processors.
Toward Large-Scale Photonics-Empowered AI Systems: From Physical Design Automation to System-Algorithm Co-Exploration
Dec 31, 2025In this work, we identify three considerations that are essential for realizing practical photonic AI systems at scale: (1) dynamic tensor operation support for modern models rather than only weight-static kernels, especially for attention/Transformer-style workloads; (2) systematic management of conversion, control, and data-movement overheads, where multiplexing and dataflow must amortize electronic costs instead of letting ADC/DAC and I/O dominate; and (3) robustness under hardware non-idealities that become more severe as integration density grows. To study these coupled tradeoffs quantitatively, and to ensure they remain meaningful under real implementation constraints, we build a cross-layer toolchain that supports photonic AI design from early exploration to physical realization. SimPhony provides implementation-aware modeling and rapid cross-layer evaluation, translating physical costs into system-level metrics so architectural decisions are grounded in realistic assumptions. ADEPT and ADEPT-Z enable end-to-end circuit and topology exploration, connecting system objectives to feasible photonic fabrics under practical device and circuit constraints. Finally, Apollo and LiDAR provide scalable photonic physical design automation, turning candidate circuits into manufacturable layouts while accounting for routing, thermal, and crosstalk constraints.
Democratizing Electronic-Photonic AI Systems: An Open-Source AI-Infused Cross-Layer Co-Design and Design Automation Toolflow
Dec 31, 2025Photonics is becoming a cornerstone technology for high-performance AI systems and scientific computing, offering unparalleled speed, parallelism, and energy efficiency. Despite this promise, the design and deployment of electronic-photonic AI systems remain highly challenging due to a steep learning curve across multiple layers, spanning device physics, circuit design, system architecture, and AI algorithms. The absence of a mature electronic-photonic design automation (EPDA) toolchain leads to long, inefficient design cycles and limits cross-disciplinary innovation and co-evolution. In this work, we present a cross-layer co-design and automation framework aimed at democratizing photonic AI system development. We begin by introducing our architecture designs for scalable photonic edge AI and Transformer inference, followed by SimPhony, an open-source modeling tool for rapid EPIC AI system evaluation and design-space exploration. We then highlight advances in AI-enabled photonic design automation, including physical AI-based Maxwell solvers, a fabrication-aware inverse design framework, and a scalable inverse training algorithm for meta-optical neural networks, enabling a scalable EPDA stack for next-generation electronic-photonic AI systems.
Toward Lifelong-Sustainable Electronic-Photonic AI Systems via Extreme Efficiency, Reconfigurability, and Robustness
Sep 09, 2025The relentless growth of large-scale artificial intelligence (AI) has created unprecedented demand for computational power, straining the energy, bandwidth, and scaling limits of conventional electronic platforms. Electronic-photonic integrated circuits (EPICs) have emerged as a compelling platform for next-generation AI systems, offering inherent advantages in ultra-high bandwidth, low latency, and energy efficiency for computing and interconnection. Beyond performance, EPICs also hold unique promises for sustainability. Fabricated in relaxed process nodes with fewer metal layers and lower defect densities, photonic devices naturally reduce embodied carbon footprint (CFP) compared to advanced digital electronic integrated circuits, while delivering orders-of-magnitude higher computing performance and interconnect bandwidth. To further advance the sustainability of photonic AI systems, we explore how electronic-photonic design automation (EPDA) and cross-layer co-design methodologies can amplify these inherent benefits. We present how advanced EPDA tools enable more compact layout generation, reducing both chip area and metal layer usage. We will also demonstrate how cross-layer device-circuit-architecture co-design unlocks new sustainability gains for photonic hardware: ultra-compact photonic circuit designs that minimize chip area cost, reconfigurable hardware topology that adapts to evolving AI workloads, and intelligent resilience mechanisms that prolong lifetime by tolerating variations and faults. By uniting intrinsic photonic efficiency with EPDA- and co-design-driven gains in area efficiency, reconfigurability, and robustness, we outline a vision for lifelong-sustainable electronic-photonic AI systems. This perspective highlights how EPIC AI systems can simultaneously meet the performance demands of modern AI and the urgent imperative for sustainable computing.
SP2RINT: Spatially-Decoupled Physics-Inspired Progressive Inverse Optimization for Scalable, PDE-Constrained Meta-Optical Neural Network Training
May 23, 2025DONNs harness the physics of light propagation for efficient analog computation, with applications in AI and signal processing. Advances in nanophotonic fabrication and metasurface-based wavefront engineering have opened new pathways to realize high-capacity DONNs across various spectral regimes. Training such DONN systems to determine the metasurface structures remains challenging. Heuristic methods are fast but oversimplify metasurfaces modulation, often resulting in physically unrealizable designs and significant performance degradation. Simulation-in-the-loop training methods directly optimize a physically implementable metasurface using adjoint methods during end-to-end DONN training, but are inherently computationally prohibitive and unscalable.To address these limitations, we propose SP2RINT, a spatially decoupled, progressive training framework that formulates DONN training as a PDE-constrained learning problem. Metasurface responses are first relaxed into freely trainable transfer matrices with a banded structure. We then progressively enforce physical constraints by alternating between transfer matrix training and adjoint-based inverse design, avoiding per-iteration PDE solves while ensuring final physical realizability. To further reduce runtime, we introduce a physics-inspired, spatially decoupled inverse design strategy based on the natural locality of field interactions. This approach partitions the metasurface into independently solvable patches, enabling scalable and parallel inverse design with system-level calibration. Evaluated across diverse DONN training tasks, SP2RINT achieves digital-comparable accuracy while being 1825 times faster than simulation-in-the-loop approaches. By bridging the gap between abstract DONN models and implementable photonic hardware, SP2RINT enables scalable, high-performance training of physically realizable meta-optical neural systems.
SimPhony: A Device-Circuit-Architecture Cross-Layer Modeling and Simulation Framework for Heterogeneous Electronic-Photonic AI System
Nov 20, 2024



Electronic-photonic integrated circuits (EPICs) offer transformative potential for next-generation high-performance AI but require interdisciplinary advances across devices, circuits, architecture, and design automation. The complexity of hybrid systems makes it challenging even for domain experts to understand distinct behaviors and interactions across design stack. The lack of a flexible, accurate, fast, and easy-to-use EPIC AI system simulation framework significantly limits the exploration of hardware innovations and system evaluations on common benchmarks. To address this gap, we propose SimPhony, a cross-layer modeling and simulation framework for heterogeneous electronic-photonic AI systems. SimPhony offers a platform that enables (1) generic, extensible hardware topology representation that supports heterogeneous multi-core architectures with diverse photonic tensor core designs; (2) optics-specific dataflow modeling with unique multi-dimensional parallelism and reuse beyond spatial/temporal dimensions; (3) data-aware energy modeling with realistic device responses, layout-aware area estimation, link budget analysis, and bandwidth-adaptive memory modeling; and (4) seamless integration with model training framework for hardware/software co-simulation. By providing a unified, versatile, and high-fidelity simulation platform, SimPhony enables researchers to innovate and evaluate EPIC AI hardware across multiple domains, facilitating the next leap in emerging AI hardware. We open-source our codes at https://github.com/ScopeX-ASU/SimPhony
Multi-Dimensional Reconfigurable, Physically Composable Hybrid Diffractive Optical Neural Network
Nov 08, 2024



Diffractive optical neural networks (DONNs), leveraging free-space light wave propagation for ultra-parallel, high-efficiency computing, have emerged as promising artificial intelligence (AI) accelerators. However, their inherent lack of reconfigurability due to fixed optical structures post-fabrication hinders practical deployment in the face of dynamic AI workloads and evolving applications. To overcome this challenge, we introduce, for the first time, a multi-dimensional reconfigurable hybrid diffractive ONN system (MDR-HDONN), a physically composable architecture that unlocks a new degree of freedom and unprecedented versatility in DONNs. By leveraging full-system learnability, MDR-HDONN repurposes fixed fabricated optical hardware, achieving exponentially expanded functionality and superior task adaptability through the differentiable learning of system variables. Furthermore, MDR-HDONN adopts a hybrid optical/photonic design, combining the reconfigurability of integrated photonics with the ultra-parallelism of free-space diffractive systems. Extensive evaluations demonstrate that MDR-HDONN has digital-comparable accuracy on various task adaptations with 74x faster speed and 194x lower energy. Compared to prior DONNs, MDR-HDONN shows exponentially larger functional space with 5x faster training speed, paving the way for a new paradigm of versatile, composable, hybrid optical/photonic AI computing. We will open-source our codes.
SCATTER: Algorithm-Circuit Co-Sparse Photonic Accelerator with Thermal-Tolerant, Power-Efficient In-situ Light Redistribution
Jul 07, 2024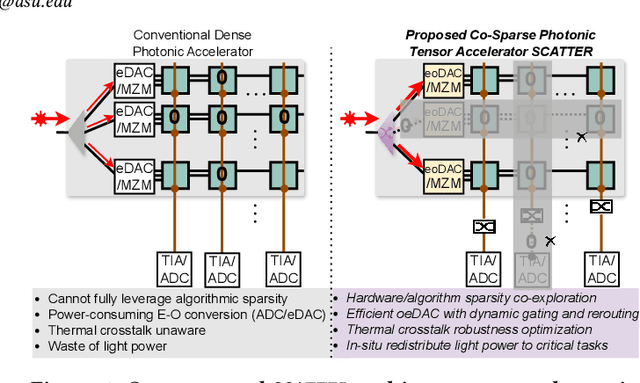
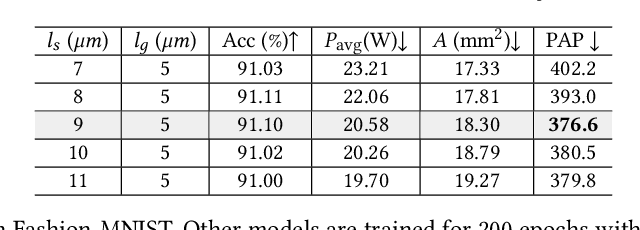
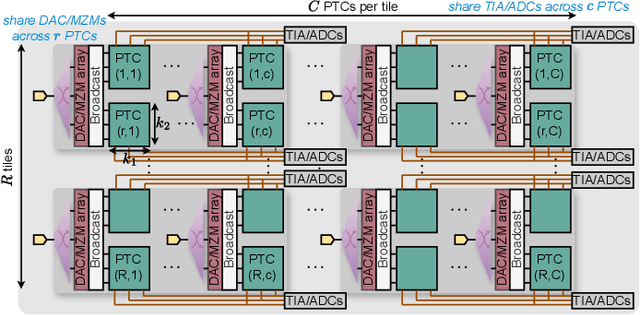
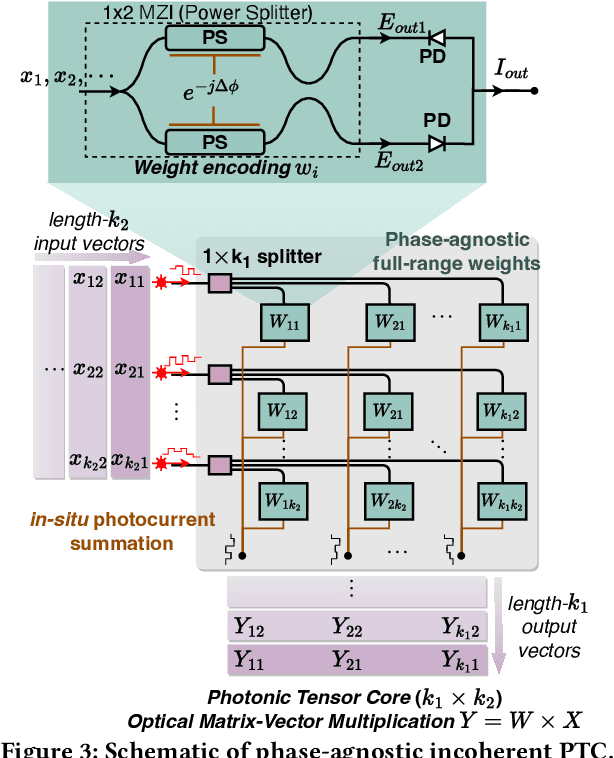
Photonic computing has emerged as a promising solution for accelerating computation-intensive artificial intelligence (AI) workloads. However, limited reconfigurability, high electrical-optical conversion cost, and thermal sensitivity limit the deployment of current optical analog computing engines to support power-restricted, performance-sensitive AI workloads at scale. Sparsity provides a great opportunity for hardware-efficient AI accelerators. However, current dense photonic accelerators fail to fully exploit the power-saving potential of algorithmic sparsity. It requires sparsity-aware hardware specialization with a fundamental re-design of photonic tensor core topology and cross-layer device-circuit-architecture-algorithm co-optimization aware of hardware non-ideality and power bottleneck. To trim down the redundant power consumption while maximizing robustness to thermal variations, we propose SCATTER, a novel algorithm-circuit co-sparse photonic accelerator featuring dynamically reconfigurable signal path via thermal-tolerant, power-efficient in-situ light redistribution and power gating. A power-optimized, crosstalk-aware dynamic sparse training framework is introduced to explore row-column structured sparsity and ensure marginal accuracy loss and maximum power efficiency. The extensive evaluation shows that our cross-stacked optimized accelerator SCATTER achieves a 511X area reduction and 12.4X power saving with superior crosstalk tolerance that enables unprecedented circuit layout compactness and on-chip power efficiency.