 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSP2RINT: Spatially-Decoupled Physics-Inspired Progressive Inverse Optimization for Scalable, PDE-Constrained Meta-Optical Neural Network Training
May 23, 2025DONNs harness the physics of light propagation for efficient analog computation, with applications in AI and signal processing. Advances in nanophotonic fabrication and metasurface-based wavefront engineering have opened new pathways to realize high-capacity DONNs across various spectral regimes. Training such DONN systems to determine the metasurface structures remains challenging. Heuristic methods are fast but oversimplify metasurfaces modulation, often resulting in physically unrealizable designs and significant performance degradation. Simulation-in-the-loop training methods directly optimize a physically implementable metasurface using adjoint methods during end-to-end DONN training, but are inherently computationally prohibitive and unscalable.To address these limitations, we propose SP2RINT, a spatially decoupled, progressive training framework that formulates DONN training as a PDE-constrained learning problem. Metasurface responses are first relaxed into freely trainable transfer matrices with a banded structure. We then progressively enforce physical constraints by alternating between transfer matrix training and adjoint-based inverse design, avoiding per-iteration PDE solves while ensuring final physical realizability. To further reduce runtime, we introduce a physics-inspired, spatially decoupled inverse design strategy based on the natural locality of field interactions. This approach partitions the metasurface into independently solvable patches, enabling scalable and parallel inverse design with system-level calibration. Evaluated across diverse DONN training tasks, SP2RINT achieves digital-comparable accuracy while being 1825 times faster than simulation-in-the-loop approaches. By bridging the gap between abstract DONN models and implementable photonic hardware, SP2RINT enables scalable, high-performance training of physically realizable meta-optical neural systems.
CamMimic: Zero-Shot Image To Camera Motion Personalized Video Generation Using Diffusion Models
Apr 13, 2025We introduce CamMimic, an innovative algorithm tailored for dynamic video editing needs. It is designed to seamlessly transfer the camera motion observed in a given reference video onto any scene of the user's choice in a zero-shot manner without requiring any additional data. Our algorithm achieves this using a two-phase strategy by leveraging a text-to-video diffusion model. In the first phase, we develop a multi-concept learning method using a combination of LoRA layers and an orthogonality loss to capture and understand the underlying spatial-temporal characteristics of the reference video as well as the spatial features of the user's desired scene. The second phase proposes a unique homography-based refinement strategy to enhance the temporal and spatial alignment of the generated video. We demonstrate the efficacy of our method through experiments conducted on a dataset containing combinations of diverse scenes and reference videos containing a variety of camera motions. In the absence of an established metric for assessing camera motion transfer between unrelated scenes, we propose CameraScore, a novel metric that utilizes homography representations to measure camera motion similarity between the reference and generated videos. Extensive quantitative and qualitative evaluations demonstrate that our approach generates high-quality, motion-enhanced videos. Additionally, a user study reveals that 70.31% of participants preferred our method for scene preservation, while 90.45% favored it for motion transfer. We hope this work lays the foundation for future advancements in camera motion transfer across different scenes.
Parametric Shadow Control for Portrait Generationin Text-to-Image Diffusion Models
Mar 27, 2025Text-to-image diffusion models excel at generating diverse portraits, but lack intuitive shadow control. Existing editing approaches, as post-processing, struggle to offer effective manipulation across diverse styles. Additionally, these methods either rely on expensive real-world light-stage data collection or require extensive computational resources for training. To address these limitations, we introduce Shadow Director, a method that extracts and manipulates hidden shadow attributes within well-trained diffusion models. Our approach uses a small estimation network that requires only a few thousand synthetic images and hours of training-no costly real-world light-stage data needed. Shadow Director enables parametric and intuitive control over shadow shape, placement, and intensity during portrait generation while preserving artistic integrity and identity across diverse styles. Despite training only on synthetic data built on real-world identities, it generalizes effectively to generated portraits with diverse styles, making it a more accessible and resource-friendly solution.
V-Trans4Style: Visual Transition Recommendation for Video Production Style Adaptation
Jan 14, 2025We introduce V-Trans4Style, an innovative algorithm tailored for dynamic video content editing needs. It is designed to adapt videos to different production styles like documentaries, dramas, feature films, or a specific YouTube channel's video-making technique. Our algorithm recommends optimal visual transitions to help achieve this flexibility using a more bottom-up approach. We first employ a transformer-based encoder-decoder network to learn recommending temporally consistent and visually seamless sequences of visual transitions using only the input videos. We then introduce a style conditioning module that leverages this model to iteratively adjust the visual transitions obtained from the decoder through activation maximization. We demonstrate the efficacy of our method through experiments conducted on our newly introduced AutoTransition++ dataset. It is a 6k video version of AutoTransition Dataset that additionally categorizes its videos into different production style categories. Our encoder-decoder model outperforms the state-of-the-art transition recommendation method, achieving improvements of 10% to 80% in Recall@K and mean rank values over baseline. Our style conditioning module results in visual transitions that improve the capture of the desired video production style characteristics by an average of around 12% in comparison to other methods when measured with similarity metrics. We hope that our work serves as a foundation for exploring and understanding video production styles further.
Cpp-Taskflow v2: A General-purpose Parallel and Heterogeneous Task Programming System at Scale
Apr 26, 2020
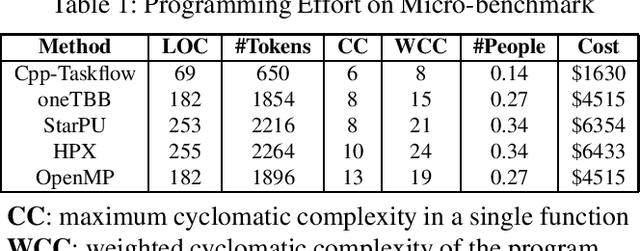

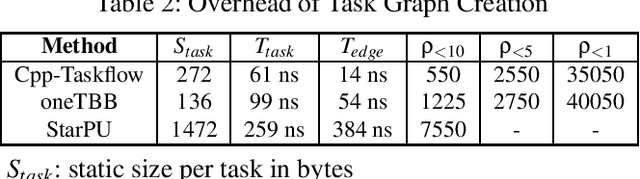
The Cpp-Taskflow project addresses the long-standing question: How can we make it easier for developers to write parallel and heterogeneous programs with high performance and simultaneous high productivity? Cpp-Taskflow develops a simple and powerful task programming model to enable efficient implementations of heterogeneous decomposition strategies. Our programming model empowers users with both static and dynamic task graph constructions to incorporate a broad range of computational patterns including hybrid CPU-GPU computing, dynamic control flow, and irregularity. We develop an efficient heterogeneous work-stealing strategy that adapts worker threads to available task parallelism at any time during the graph execution. We have demonstrated promising performance of Cpp-Taskflow on both micro-benchmark and real-world applications. As an example, we solved a large machine learning workload by up to 1.5x faster, 1.6x less memory, and 1.7x fewer lines of code than two industrial-strength systems, oneTBB and StarPU, on a machine of 40 CPUs and 4 GPUs.