 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Frame Is the Place to Go for Video Content Customization
Nov 19, 2025What role does the first frame play in video generation models? Traditionally, it's viewed as the spatial-temporal starting point of a video, merely a seed for subsequent animation. In this work, we reveal a fundamentally different perspective: video models implicitly treat the first frame as a conceptual memory buffer that stores visual entities for later reuse during generation. Leveraging this insight, we show that it's possible to achieve robust and generalized video content customization in diverse scenarios, using only 20-50 training examples without architectural changes or large-scale finetuning. This unveils a powerful, overlooked capability of video generation models for reference-based video customization.
Parametric Shadow Control for Portrait Generationin Text-to-Image Diffusion Models
Mar 27, 2025Text-to-image diffusion models excel at generating diverse portraits, but lack intuitive shadow control. Existing editing approaches, as post-processing, struggle to offer effective manipulation across diverse styles. Additionally, these methods either rely on expensive real-world light-stage data collection or require extensive computational resources for training. To address these limitations, we introduce Shadow Director, a method that extracts and manipulates hidden shadow attributes within well-trained diffusion models. Our approach uses a small estimation network that requires only a few thousand synthetic images and hours of training-no costly real-world light-stage data needed. Shadow Director enables parametric and intuitive control over shadow shape, placement, and intensity during portrait generation while preserving artistic integrity and identity across diverse styles. Despite training only on synthetic data built on real-world identities, it generalizes effectively to generated portraits with diverse styles, making it a more accessible and resource-friendly solution.
Denoising Hamiltonian Network for Physical Reasoning
Mar 10, 2025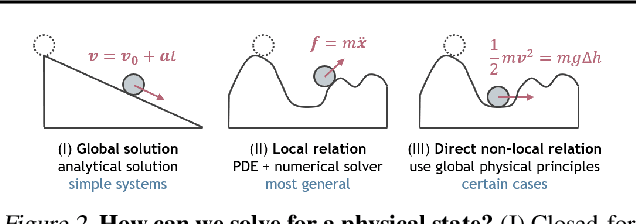
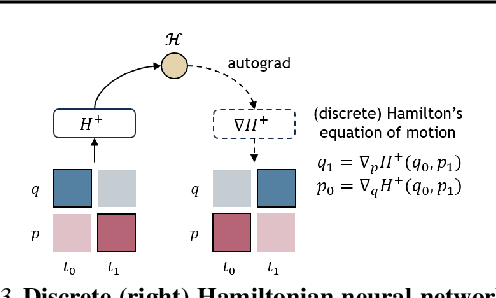
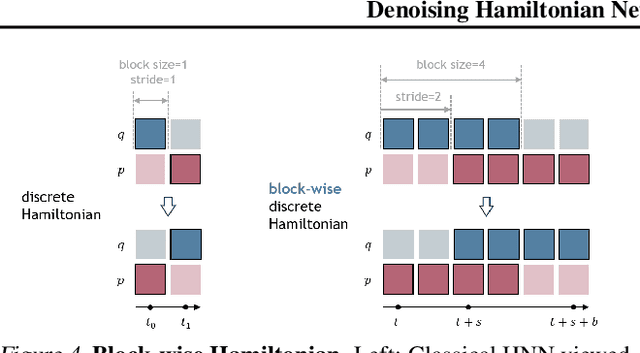
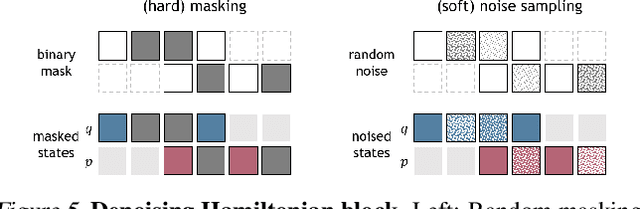
Machine learning frameworks for physical problems must capture and enforce physical constraints that preserve the structure of dynamical systems. Many existing approaches achieve this by integrating physical operators into neural networks. While these methods offer theoretical guarantees, they face two key limitations: (i) they primarily model local relations between adjacent time steps, overlooking longer-range or higher-level physical interactions, and (ii) they focus on forward simulation while neglecting broader physical reasoning tasks. We propose the Denoising Hamiltonian Network (DHN), a novel framework that generalizes Hamiltonian mechanics operators into more flexible neural operators. DHN captures non-local temporal relationships and mitigates numerical integration errors through a denoising mechanism. DHN also supports multi-system modeling with a global conditioning mechanism. We demonstrate its effectiveness and flexibility across three diverse physical reasoning tasks with distinct inputs and outputs.
Exoplanet Detection via Differentiable Rendering
Jan 03, 2025Direct imaging of exoplanets is crucial for advancing our understanding of planetary systems beyond our solar system, but it faces significant challenges due to the high contrast between host stars and their planets. Wavefront aberrations introduce speckles in the telescope science images, which are patterns of diffracted starlight that can mimic the appearance of planets, complicating the detection of faint exoplanet signals. Traditional post-processing methods, operating primarily in the image intensity domain, do not integrate wavefront sensing data. These data, measured mainly for adaptive optics corrections, have been overlooked as a potential resource for post-processing, partly due to the challenge of the evolving nature of wavefront aberrations. In this paper, we present a differentiable rendering approach that leverages these wavefront sensing data to improve exoplanet detection. Our differentiable renderer models wave-based light propagation through a coronagraphic telescope system, allowing gradient-based optimization to significantly improve starlight subtraction and increase sensitivity to faint exoplanets. Simulation experiments based on the James Webb Space Telescope configuration demonstrate the effectiveness of our approach, achieving substantial improvements in contrast and planet detection limits. Our results showcase how the computational advancements enabled by differentiable rendering can revitalize previously underexploited wavefront data, opening new avenues for enhancing exoplanet imaging and characterization.
Repurposing Pre-trained Video Diffusion Models for Event-based Video Interpolation
Dec 10, 2024



Video Frame Interpolation aims to recover realistic missing frames between observed frames, generating a high-frame-rate video from a low-frame-rate video. However, without additional guidance, the large motion between frames makes this problem ill-posed. Event-based Video Frame Interpolation (EVFI) addresses this challenge by using sparse, high-temporal-resolution event measurements as motion guidance. This guidance allows EVFI methods to significantly outperform frame-only methods. However, to date, EVFI methods have relied on a limited set of paired event-frame training data, severely limiting their performance and generalization capabilities. In this work, we overcome the limited data challenge by adapting pre-trained video diffusion models trained on internet-scale datasets to EVFI. We experimentally validate our approach on real-world EVFI datasets, including a new one that we introduce. Our method outperforms existing methods and generalizes across cameras far better than existing approaches.
Flash-Splat: 3D Reflection Removal with Flash Cues and Gaussian Splats
Oct 03, 2024We introduce a simple yet effective approach for separating transmitted and reflected light. Our key insight is that the powerful novel view synthesis capabilities provided by modern inverse rendering methods (e.g.,~3D Gaussian splatting) allow one to perform flash/no-flash reflection separation using unpaired measurements -- this relaxation dramatically simplifies image acquisition over conventional paired flash/no-flash reflection separation methods. Through extensive real-world experiments, we demonstrate our method, Flash-Splat, accurately reconstructs both transmitted and reflected scenes in 3D. Our method outperforms existing 3D reflection separation methods, which do not leverage illumination control, by a large margin. Our project webpage is at https://flash-splat.github.io/.
EndoSparse: Real-Time Sparse View Synthesis of Endoscopic Scenes using Gaussian Splatting
Jul 01, 2024



3D reconstruction of biological tissues from a collection of endoscopic images is a key to unlock various important downstream surgical applications with 3D capabilities. Existing methods employ various advanced neural rendering techniques for photorealistic view synthesis, but they often struggle to recover accurate 3D representations when only sparse observations are available, which is usually the case in real-world clinical scenarios. To tackle this {sparsity} challenge, we propose a framework leveraging the prior knowledge from multiple foundation models during the reconstruction process, dubbed as \textit{EndoSparse}. Experimental results indicate that our proposed strategy significantly improves the geometric and appearance quality under challenging sparse-view conditions, including using only three views. In rigorous benchmarking experiments against state-of-the-art methods, \textit{EndoSparse} achieves superior results in terms of accurate geometry, realistic appearance, and rendering efficiency, confirming the robustness to sparse-view limitations in endoscopic reconstruction. \textit{EndoSparse} signifies a steady step towards the practical deployment of neural 3D reconstruction in real-world clinical scenarios. Project page: https://endo-sparse.github.io/.
VividDream: Generating 3D Scene with Ambient Dynamics
May 30, 2024We introduce VividDream, a method for generating explorable 4D scenes with ambient dynamics from a single input image or text prompt. VividDream first expands an input image into a static 3D point cloud through iterative inpainting and geometry merging. An ensemble of animated videos is then generated using video diffusion models with quality refinement techniques and conditioned on renderings of the static 3D scene from the sampled camera trajectories. We then optimize a canonical 4D scene representation using an animated video ensemble, with per-video motion embeddings and visibility masks to mitigate inconsistencies. The resulting 4D scene enables free-view exploration of a 3D scene with plausible ambient scene dynamics. Experiments demonstrate that VividDream can provide human viewers with compelling 4D experiences generated based on diverse real images and text prompts.
Single-shot volumetric fluorescence imaging with neural fields
May 16, 2024Single-shot volumetric fluorescence (SVF) imaging offers a significant advantage over traditional imaging methods that require scanning across multiple axial planes as it can capture biological processes with high temporal resolution across a large field of view. Existing SVF imaging methods often require large, complex point spread functions (PSFs) to meet the multiplexing requirements of compressed sensing, which limits the signal-to-noise ratio, resolution and/or field of view. In this paper, we introduce the QuadraPol PSF combined with neural fields, a novel approach for SVF imaging. This method utilizes a cost-effective custom polarizer at the back focal plane and a polarization camera to detect fluorescence, effectively encoding the 3D scene within a compact PSF without depth ambiguity. Additionally, we propose a reconstruction algorithm based on the neural fields technique that addresses the inaccuracies of phase retrieval methods used to correct imaging system aberrations. This algorithm combines the accuracy of experimental PSFs with the long depth of field of computationally generated retrieved PSFs. QuadraPol PSF, combined with neural fields, significantly reduces the acquisition time of a conventional fluorescence microscope by approximately 20 times and captures a 100 mm$^3$ cubic volume in one shot. We validate the effectiveness of both our hardware and algorithm through all-in-focus imaging of bacterial colonies on sand surfaces and visualization of plant root morphology. Our approach offers a powerful tool for advancing biological research and ecological studies.
PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation
Apr 19, 2024Realistic object interactions are crucial for creating immersive virtual experiences, yet synthesizing realistic 3D object dynamics in response to novel interactions remains a significant challenge. Unlike unconditional or text-conditioned dynamics generation, action-conditioned dynamics requires perceiving the physical material properties of objects and grounding the 3D motion prediction on these properties, such as object stiffness. However, estimating physical material properties is an open problem due to the lack of material ground-truth data, as measuring these properties for real objects is highly difficult. We present PhysDreamer, a physics-based approach that endows static 3D objects with interactive dynamics by leveraging the object dynamics priors learned by video generation models. By distilling these priors, PhysDreamer enables the synthesis of realistic object responses to novel interactions, such as external forces or agent manipulations. We demonstrate our approach on diverse examples of elastic objects and evaluate the realism of the synthesized interactions through a user study. PhysDreamer takes a step towards more engaging and realistic virtual experiences by enabling static 3D objects to dynamically respond to interactive stimuli in a physically plausible manner. See our project page at https://physdreamer.github.io/.